Understanding Multicollinearity in Regression Analysis

Multicollinearity is a crucial issue in regression analysis, affecting the accuracy of estimators and hypothesis testing. Detecting multicollinearity involves examining factors like high R-squared values, low t-statistics, and correlations among independent variables. Ways to identify multicollinearity include analyzing auxiliary regressions, VIF, Eigenvalues, and condition indices. The consequences of multicollinearity, such as biased estimations and difficulties in hypothesis testing, underscore the importance of addressing this issue in statistical modeling.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Kakhramon Yusupov June 15th, 2017 1:30pm 3:00pm Session 3 MODEL DIAGNOSTICS AND SPECIFICATION MODEL DIAGNOSTICS AND SPECIFICATION
Data collection process Constraints on model or in the population being sampled. Model specification An over-determined models
Perfect multicollinearity is the case when two ore more independent variables Can create perfect linear relationship. + + = ..... 0 X X X kX 1 1 2 2 3 3 k = + ..... 3 2 kX 1 X X X 1 2 3 k 1 1 Perfect multicollinearity is the case when two ore more independent variables Can create less than perfect linear relationship. 1 = + + ..... 3 2 k X X X X e 1 2 3 k i 1 1 1 1
The OLS is BLUE but large variances and covariances making process estimation difficult. Large variances cause large confidence intervals and accepting or rejecting hypothesis are biased. T statistics are biased Although t-stats are low, R-square might be very high. The sensitivity of estimators and variances are very high to small changes in dataset.
2 2 2 1 = = = var( ) VIF 2 2 2 2 2 2 2 2 2 1 ( ) 1 ( ) x r 3 , 2 x r 3 , 2 x i i i . 1 96 ( ) se VIF k k Due to low t-stats we can not reject our Null Hypothesis = 0 k k t ( ) se VIF k = = = = : ... 0 H Ha: Not all slope coefficients are simultaneously zero 0 2 3 k 2 2 /( 2 ) 1 n n k ESS n k R R k = = = F 2 1 1 1 1 ( ) /( ) k RSS k R R k Due to high R square the F-value will be very high and rejection of Ho will be easy
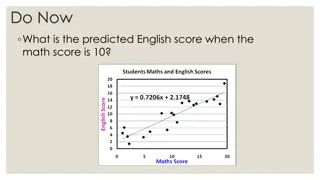
Multicollinearity is a question of degree. It is a feature of sample but not population. How to detect : High R square but low t-stats. High correlation coefficients among the independent variables. Auxiliary regression High VIF Eigenvalue and condition index.***
Ho: The Xi variable is not collinear = + + + + ..... X X X X X X 0 0 1 1 2 2 3 3 i k k = 2 2 j R R Run regression where one X is dependent and other X s are independent and Obtain R square 2 /( ) 2 Df num = k Df num = k- -2 2 Df denom = n Df denom = n- -k+1 R k , , ... x x x x = F 2 3 i k k+1 i ) 1 + 2 1 ( ) /( R n k , , ... x x x x 2 3 i k k k- - is the number of explanatory variables including intercept. is the number of explanatory variables including intercept. n n- - is sample size. is sample size. If F stat is higher than F critical then Xi variable is collinear If F stat is higher than F critical then Xi variable is collinear Rule of thumb: Rule of thumb: if R square of auxiliary regression is higher than over if R square of auxiliary regression is higher than over R square then it might be troublesome. R square then it might be troublesome.
Do nothing. Combining cross section and time series Transformation of variables (differencing, ratio transformation) Additional data observations.
Homoscedasticity or equal variance of ui [ ) | var( = i i u E X u f(u) var( = = 2 i 2 ( | )] ( | ) E u X E u X i i ) i i 2 i | u i X i Y Y X X
Error learning models; Higher variability in independent variable might increase higher variability in dependent variable. Spatial Correlation. Data collecting biases. Existence of extreme observations (outliers) Incorrect specification of Model Skewness in the distribution
2 n n X = i = i ) 2 = = = 2 2 ( ( ) ( ) i Var W E u E u i i i n = j 2 1 1 X j 1 n = i 2 2 If variance of residuals is constant then Our equation collapses to original variance Formula. X i i 1 2 n = j 2 X j 1 2 ) = ( Var n = j 2 X j 1
The regression coefficients are unbiased The usual formula for coefficient variances is wrong The OLS estimation is BLU but not efficient. t-test and F test are not valid.
= + + Y X + u 1 2 i i i , 0= i 1 X = + Y X X u 1 , 0 2 i i i i X Y X * , 0 = + + i i i u 1 2 i i i i 2 1 1 u 2 = = = = = * * 2 2 ( ) ( ) ( ) 1 i Var u E u E E u i i i i 2 2 i i i
* 2 2 X u Y X * * , 0 = i i i i Min 1 2 * * { , } 1 2 i i i i w ) X ( ) w w Y X w X w Y * i i i i X i i i i = 2 2 2 ( )( ( ) w w i i i i i X w * i = ( ) Var 2 2 2 ( ) ( ) w w w X i i i i i
Graphical Method Park test White s general Hetroscedasticity test Breush-Pagan-Godfrey Test
= + + Y X u i i i = u 2 i 2 X e i i = + Log + 2 i 2 log( ) log( ) ( ) ( ) X Log u i i 2 Is not known and we use = + Log + 2 i 2 u log( ) log( ) ( ) ( ) X Log u i i If coefficient beta is statistically different from zero, it indicates that Hetroscedasticity is present.
= + + Y X u i i i 1. Order your sample from lowest to highest. Omit your central your central observation and divide your sample into two samples. 2. Run two regressions for two samples and obtain RSS1 and RSS2. RSS1 represents RSS from small X sample. 3. Each RSS has following degrees of freedom n c RSS k 1 2 2 n c k RSS 2 2 df / RSS = 2 1 Calculate / RSS df 2k n c 2 2 Follows F distribution with df of num and denom equal to
= + + + + ... Y X X X u 0 1 1 2 2 i k k i = = + + 0 + Z + 1 + Z ... + Z 2 i ( ... + 2 ) f Z Z Z v 0 1 1 2 2 k k i + 2 v 1 2 i k k i : _ _ _ hom Ho The residuals are oscedastic If you reject your Null hypothesis then there is Hetroscedasticity. .
Step1. Estimate original regression model and get residuals . Step2. Obtain u , 1 , 2 n u .......... u u 3 n = u i ~ 2 =1 i N K 2 u Step3. Construct p = i ~ i 2 Step4. Estimate the following regression model. = + + + + ... p Z Z Z v 0 1 1 2 2 i k k i Step5. Obtain 1 = ESS 2 2 ~ 1 m m- is number of parameters of Step 4 regression
Step1. Estimate original regression model and get residuals . = + + + Y X X u 0 1 1 2 2 i i Step2. Estimate 2 2 = + + + + + + 2 u X X X X X X v 0 1 1 2 2 3 3 4 4 5 1 2 i i 2~ 2 nR m If you reject your Null hypothesis then there is Hetroscedasticity. .
Weighted Least squares White s Hetroscedasticity consistent variance and standard errors. Transformations according to Hetroscedasticity pattern.
LM test score and assume that 1. Regress each element of X2 onto all elements of X1 and collect residual in r r matrix 2. Then form u*R 3. Then run regression 1 on ur 4. = + 0 + Y X H X u 1 1 : 2 2 = 0 2 u*R ur N SSR 0 k 2 ) 1 1 = 2 i var( ' ' A X X u X X X X i i
Inertia. Specification Bias: Omitted relevant variables. Specification bias: Incorrect functional form. Cobweb phenomenon. Lags Data manipulation. Data Transformation. Non-stationary
The regression coefficients are unbiased The usual formula for coefficient variances is wrong The OLS estimation is BLU but not efficient. t-test and F test are not valid.
DW test: (the regression model includes intercept, there is no lagged dependent variable, the explanatory variables, the X s are non-stochastic, residuals follow AR(1) process, residuals are normally distributed) n = h 1 [var( n )] 2 ( 1) e e 2 t t = d ( 0 1 , ) h N asy 2 t e 1 / 2 d
= + + + ... + Y X X X u 0 1 , 1 2 , 2 , t t t k k t i = + + + + ..... + ... u + X X X 0 1 1 2 2 t k k + + + + u u u u e 1 1 2 2 3 3 t t t k t k t : H There is no kth order serial correlation 0 2~ 2 p ( ) n p R Test Statistic Where n- number of observations, p-number of residual lag variables.
GLS Newey-West Autocorrelation consistent variance and standard errors. Including lagged dependent variable. Transformations according to Autocorrelation pattern.
If the value of rho is known = + + Y X u 1 u 2 t t t 1 1 = + u v 1 t t t = Y + + Y X u 1 1 2 1 + 1 t t t X = + 1 ( ) ( ) Y X u u 1 1 2 1 1 t t t t t t If the value of rho is not known = + ( ) Y Y X X u u 1 2 1 1 t t t t t t = + Y X u 2 t t t
First estimate original regression and obtain residuals = + + 1 Y X + u t 1 2 t 1 t = 1 u u v 1 t t t After runing AR(1) regression obtain the value of Rho and run GLS regression ( ) ( ) ( + ) = + * * 1 ( ) Y Y X X u u 1 2 1 1 1 t t t t t t Using GLS coefficients obtain new residuals and obtain new value of Rho = + + * * 2 Y X u 1 2 t t t = + 2 2 u u v 1 t t t Continue the process until you get convergence in coefficients.
Distribute d lag models = + + + + Y Autoregres X sive X X u 0 1 1 2 2 t t t t t model = + + + Y X Y u 1 t t t t
1. Omission of relevant variables + + = e X X Y t = + the model t which you estimate Y X u 1 1 t t 1 1 2 2 = 1 ' ( ' ) X X X Y 1 1 1 = + + = 1 ' ( ' ) ( ) = X X X X X e 1 ) 1 1 1 ( 1 2 ) 2 X t + + = 1 ' 1 ' 1 ' ( ' ' ( ' ) X X X X X X X X X X e 1 + 1 1 X 1 ' 1 1 1 1 = 2 2 X 1 ) 1 1 t + 1 ' 1 ' ( ) where ( ' X X e X X X 1 2 1 1 1 1 1 1 2 t = 1 + + ' or and v if E( ) 0 X X X e 2 1 t ) = ( E 1 2
If omitted variable does not relate to other included independent variables then OLS estimator still BLUE Proxy variables Use other methods other than OLS