Understanding Linear Regression and Gradient Descent
Linear regression is about predicting continuous values, while logistic regression deals with discrete predictions. Gradient descent is a widely used optimization technique in machine learning. To predict commute times for new individuals based on data, we can use linear regression assuming a linear relationship between inputs and outputs. The process involves learning parameters to best fit the data, typically done through maximizing conditional likelihood.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Regress-itation Feb. 5, 2015
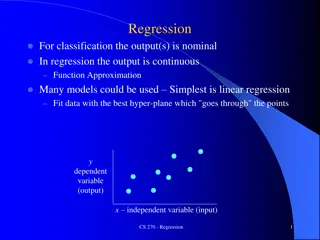
Outline Linear regression Regression: predicting a continuous value Logistic regression Classification: predicting a discrete value Gradient descent Very general optimization technique
Regression wants to predict a continuous- valued output for an input. Data: Goal:
Linear regression assumes a linear relationship between inputs and outputs. Data: Goal:
Now, you want to predict commute time for a new person, who lives 1.1 miles from campus.
Now, you want to predict commute time for a new person, who lives 1.1 miles from campus. 1.1
Now, you want to predict commute time for a new person, who lives 1.1 miles from campus. ~23 1.1
How can we find this line? Define xi: input, distance from campus yi: output, commute time We want to predict y for an unknown x Assume In general, assume y = f(x) + For 1-D linear regression, assume f(x) = w0 + w1x We want to learn the parameters w
We can learn w from the observed data by maximizing the conditional likelihood. Recall: Introducing some new notation
We can learn w from the observed data by maximizing the conditional likelihood.
We can learn w from the observed data by maximizing the conditional likelihood. minimizing least-squares error
For the 1-D case Two values define this line w0: intercept w1: slope f(x) = w0 + w1x
Logistic regression is a discriminative approach to classification. Classification: predicts discrete-valued output E.g., is an email spam or not?
Logistic regression is a discriminative approach to classification. Discriminative: directly estimates P(Y|X) Only concerned with discriminating (differentiating) between classes Y In contrast, na ve Bayes is a generative classifier Estimates P(Y) & P(X|Y) and uses Bayes rule to calculate P(Y|X) Explains how data are generated, given class label Y Both logistic regression and na ve Bayes use their estimates of P(Y|X) to assign a class to an input X the difference is in how they arrive at these estimates.
The assumptions of logistic regression Given Want to learn Want to learn p(Y=1|X=x)
The logistic function is appropriate for making probability estimates. a b
Logistic regression models probabilities with the logistic function. Want to predict Y=1 for X when P(Y=1|X) 0.5 Y = 1 P(Y=1|X) Y = 0
Logistic regression models probabilities with the logistic function. Want to predict Y=1 for X when P(Y=1|X) 0.5 Y = 1 P(Y=1|X) Y = 0
Therefore, logistic regression is a linear classifier. Use the logistic function to estimate the probability of Y given X Decision boundary:
Maximize the conditional likelihood to find the weights w = [w0,w1, ,wd].
How can we optimize this function? Concave [check Hessian of P(Y|X,w)] No closed-form solution for w
Gradient descent can optimize differentiable functions. Suppose you have a differentiable function f(x) Gradient descent Choose starting point ?(0) Repeat until no change: Updated value for optimum Previous value for optimum Step size Gradient of f, evaluated at current x
Here is the trajectory of gradient descent on a quadratic function.
Gradient descent can optimize differentiable functions. Suppose you have a differentiable function f(x) Gradient descent Choose starting point ?(0) Repeat until no change: Updated value for optimum Previous value for optimum Step size Gradient of f, evaluated at current x