Data Management Workshop: Stata Commands for Statistical Analysis

This workshop conducted by UCLA's OARC covers essential Stata commands for preparing data sets for statistical analysis. It includes topics like inspecting and creating variables, handling missing data, merging datasets, and processing data efficiently. Participants will learn to use do-files, write code, and read syntax specifications to enhance data management skills.

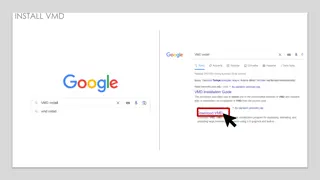
Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
UCLA OARC STATISTICAL METHODS AND DATA ANALYTICS STATA data management
Purpose of the workshop Data sets usually do not arrive in a state immediately ready for analysis Variables need to be cleaned E.g. missing data codes like -99 can invalidate analyses if left untouched Data errors should be corrected Variables need to be generated Unnecessary data should perhaps be dropped for efficiency Data sets may need to be merged together This workshop covers commonly used Stata commands to prepare data sets for statistical analysis
Topics Inspecting variables Creating variables Selecting observations and variables Missing data Date variables String variables Appending data sets Merging data sets Looping Processing data by groups
save Preliminaries load
Use do-files Write and run code in do-files, text files where Stata commands can be saved. A record of the commands used Can easily make adjustments to code later To run code from the do-file, highlight code and then Ctrl-D or click Execute(do) icon Comments: precede text with * or enclose text within /*and */ *not executed /* this is a comment */ You can also place comments on the same line as a command following // tab x // also a comment
Reading syntax specifications in this workshop Unitalicized words should be typed as is Italicized words should be replaced with the appropriate variable, command, or value For example: merge 1:1 varlist using filename varlist should be replaced with one or more variable names filename should be replaced with a file s name The rest should be typed as is varlist will be used throughout the workshop to mean one or more variable names
Workshop dataset This dataset contains fake hospital patient data, with patients as rows of data (no patient id, though) A mix of continuous and discrete numeric variables as well as string variables Some data errors and missing data codes in the data Each patient is also linked to a doctor (docid). Another dataset containing doctor variables will be merged into this dataset later in the seminar.
saveand use * save data as Stata data set, overwrite save data_clean.dta, replace We recommend that you save your data set under a different name after performing some data management on it Always good to have untouched raw, data set You may change your mind later about how variables should be generated/cleaned/etc * .dta automatically added so can omit it save data_clean, replace * load data_clean, clear memory first use data_clean, clear To quickly save and load your data in Stata, save as a Stata file (usually .dta) useloads Stata data files
browse Inspecting variables summarize tabulate codebook
browse Spreadsheet style window view browse or click on the spreadsheet and magnifying glass icon in the Stata toolbar Numeric variables appear black String variables appear red Numeric variables with value labels appear blue For large data sets, we need commands that allow us to quickly inspect variables
summarize summarize(abbreviated summ) provides summary statistics for numeric variables, which may be useful for data management: Number of non-missing observations *summary stats for variable y summ y *summary stats for all numeric variables summ Does this variable have the correct number of missing observations? Mean and standard deviation Are there any data errors or missing data codes that make the mean or standard deviation seem implausible? Minimum and maximum Are the min and max within the plausible range for this variable?
tabulate tabulate(abbreviated tab here) frequency tables (# observations per value) string or numeric variables ok but not continuous numeric variables *table of frequencies of race * display missing tab race, miss *2-way table of frequencies tab race gender Questions to ask with tab: Is this the number of categories I expect? Are the categories numbered and labeled as I expect? Do these frequencies look right? Important data management options miss -treat missing values as another category nolabel remove labels to inspect underlying numeric representation
codebook *detailed info about variables x and y codebook x y Detailed information about variables codebookprovides: For all variables Number of unique values Number of missing values Value labels, if applied For numeric variables Range quantiles, means and standard deviation for continuous variables Frequencies for discrete variables For string variables frequencies warnings about leading and trailing blanks *detailed info about all variables codebook
generate Creating variables help functions egen
generatevariables generate(abbreviated genor even g) is the basic command to create variables Often from other existing variables if the value of the input variable is missing, the generated value will be missing as well. *sum of tests * if any test=., testsum=. gen testsum = test1 + test2 + test3 *reverse-code a 1,2,3 variable gen revvar = 4-var We will be using genthroughout this seminar
Functions to use with generate *get table of function help pages help functions We can use functions to perform some operation on a variable to generate another variable *random number (0,1) for each obs gen x = runiform() Later sections of this seminar will take a focused look at the function groups Date and Time and String *running (cumulative) sum of x gen sumx = sum(x) *extract year from date variable gen yr_birth= year(date_birth) We will use many various functions from other groups as well *extract 1st 3 numbers of phone number gen areacode = substr(phone, 1, 3) Most of these functions accept no more than one variable as an input
egen, extended generation command egen(extended generate) creates variables with its own, exclusiveset of functions, which include: Many functions that accept multiple variables as arguments cut() function to create categorical variable from continuous variable group() function to create a new grouping variable that is the crossing of two grouping variables *mean of 3 y variables egen ymean = rowmean(y1 y2 y3) *how many missing values in y vars egen ymiss = rowmiss(y1 y2 y3) * how many of the y vars equal 2 or 3 egen y2or3 = anycount(y1 y2 y3), values(2 3) *age category variable: * 0-17, 18-59, 60-120, with value labels egen agecat = cut(age), at(0, 18, 60, 120) label *create agecat-by-race variable, with value labels egen agecat_race = group(agecat, race), label
if Selecting observations and variables <>=!~&| replace recode drop keep
if: selecting by condition *tab x for age > 60, include missing tab x if age > 60, miss select observations that meet a certain condition ifclause usually placed after the command specification, but before the comma that marks the beginning of the list of options.
Logical and relational operators *summary stats for y * for obs where insured not equal to 1 summ y if insured != 1 Relational Operators > greater than <= less than or equal *tab x for obs where * age < 60 and insured equal to 1 tab x if (age < 60) & (insured == 1) == equal != not equal ~= not equal Logical Operators & and | or ! not ~ not
replaceand if The replacecommand is used to replace the values of an existing variable with new values *binary variable coding whether pain is greater than 6 gen highpain = 0 replace highpain = 1 if pain > 6 Typically, replace is used with ifto replace the values in a subset of observation
Change variable coding with recode *recode (0,1,2)->3 and (6,7)->5 recode income_cat (0 1 2 = 3) (6 7 = 5) Variables are often not coded the way we want too many categories or with values out of order. With recode, we can handle all recodes for a variable in a single step.
keep and drop: filtering observations * drop observations where age < 18 drop if age < 18 Drop unneeded observations using: drop if exp * same thing as above keep if age >= 18 Where exp expresses some condition that if true, will cause an observation to be dropped Conversely, we can keep only observations that satisfy some condition with keep if exp
drop(or keep) variables * drop variables x y z drop x y z Unneeded variables can be dropped with: drop varlist * drop all variables in consecutive columns * from age-dob drop age-dob where varlistis a list of variables to drop See examples for some shortcuts to drop many variables at once * drop all variables that begin with pat drop pat* Or, if you need to drop most variables, you can keepa few * drop all variables but age keep age
. .a .b misstable summarize Missing Data mvdecode missing()
Missing data * overview of how missing values work in Stata and Stata commands for missing values help missing Missing values are very common in real data, and it is important for an analyst to be aware of missingness in the data set Hopefully, you know any missing data codes (e.g. -99) When reading in data from a text or Excel file, missing data can be represented by an empty field.
Missing values in Stata replace stringvar = if stringvar == -99 . is missing for numeric variables (also called sysmiss) * replace with sysmiss if -99 (skipped) replace numvar = . if numvar == -99 is missing for string variables (also called blank). * use .a for different missing data code -98 * (e.g. refused to answer) replace numvar = .a if numvar == -98 Additional missing data values are available .a through .z can be used to represent different types of missing (refusal, don t know, etc.). Missing values are very large numbers in Stata all non-missing numbers < . < .a < .b < < .z
misstable summarize: finding existing missing values misstable summarize produces a table of missing values (of all types) across a set of variables *table of missing values across all variables misstable summarize column Obs=. counts the number of missing values equal to . column Obs>. counts the number of missing values other than ., such as .a and .b column Obs<. and the entire right-hand section Obs<. address non-missing values
Detecting missing data codes *boxplot of variables graph box lungcapacity test1 test2 extreme numeric values are often used to represent missing values -99 or 999 Undetected, these missing data codes can be included as real data in statistical analysis Use summarizeand graph boxplot to look for missing data codes across many variables at once
Use mvdecodeto convert user-defined missing data codes to missing values *convert -99 to . for all variables mvdecode _all, mv(-99) We can quickly convert all user-defined missing codes to system missing values across all numeric variables with mvdecode. *convert -99 to . and -98 to .a mvdecode _all, mv(-99 =. \ -98=.a) Unfortunately, mvdecode will not work at all on string variables.
The missing()function The missing()function returns TRUE if the value is any one of Stata s missing values (., .a, .b, etc) *eligible if not missing for lungcapacity gen eligible = 0 replace eligible = 1 if !missing(lungcapacity)
Be careful with relational operators when working with missing values * we want hightest1 = 1 if test1 > 10 * but . > 10, so this is not right gen hightest1 = 0 replace hightest1 = 1 if test1 > 10 Missing values are very large numbers in Stata all non-missing numbers < . < .a < .b < < .z *now hightest1 will be . when test1 is . replace hightest1 = . if test1 == . Thus, (. > 50) results in TRUE When creating variables from other variables, make sure you know how you want to handle missing values
help datetime date() Date variables format year() month() day()
Dates as strings and numbers * Overview of how Stata handles dates help datetime In Stata we can store dates as strings January 2, 2021 1-2-2021 *Use codebook or describe to determine whether your date variable is a string or number codebook date_var However, dates should be represented numerically in Stata if the date dataare needed To create analysis variables For plotting *Alternatively, we can look at the variable in the browser: red=string, blue/black=number browse date_var Numeric dates (with day, month, and year data) in Stata are represented by the number of days since January 1, 1960 (a reference date) January 2, 2021 = 22,280
date(): converting string dates to numeric Use the date() function to convert string dates to numeric in Stata * create numeric version of date of birth * order is month, day, year gen newdob = date(dob, MDY ) The generic syntax, for example with gen, is: gen varname = date(stringdate, mask) stringdateis a variable maskis a code that specifies the order of the components of the date For day, month, year dates: maskis MDY if the order is month, day, year maskis DMY if the order is day, month, year
The date() function accepts dates in many formats *just display commands to show date() usage . di date("March 5, 2021", "MDY") 22344 String dates are recorded in many different formats, but fortunately, the date() function is flexible in what it accepts as inputs . di date("Mar 5, 2021", "MDY") 22344 . di date("3/5/2021", "MDY") 22344 . di date("3-5-2021", "MDY") 22344 *add 20 or 19 to the mask if year is 2-digit . di date("3-5-21", "MD20Y") 22344 . di date("3-5-21", "MD19Y") -14181
Formatting numeric dates After conversion using date(), the resulting variable will be filled with numbers representing dates, but can be hard to read directly as dates *apply date format to variable newdob format newdob %td Stata s format command controls how variables are displayed The format %td formats numbers as dates 22344will appear as 2mar2021after applying the format
Date arithmetic * length of stay gen los = discharge_date admit_date Once dates are stored as numeric variables in Stata, we can perform date arithmetic, for example, to find the number of days between two dates
Functions to extract components of dates *year of birth gen yob = year(dob) At times, we will need to extract one of the components of a date, such as the year *month of birth gen mob = month(dob) Each of these functions returns a number: year(): numeric year month(): 1 to 12 day(): day of the month
help string functions strtrim() String variables substr() + encode destring
Strings in Stata * z now missing if z was -99 replace z = if z== -99 Strings are just a series of characters Variables can generally be stored as either numeric or string String values are surrounded by quotes when specifying a Stata command String missing is Many estimation commands in Stata will not work with string variables.
String functions * help page for all string functions help string functions Stata provides a number of functions to clean, combine, and extract components of string variables We will examine a few in detail shortly Other useful functions: strlen(): length of strings strpos(): the position in a string where a substring is found strofreal(): convert number to string with a specified format
strtrim(): trimming white space * some of these categories should be combined tab hospital String variables often arrive messy, with unnecessary spaces at the beginning or end of the string May 3, 2001 * remove all leading and trailing whitespace replace hospital = strtrim(hospital) tab hospital Extra spaces can complicate string matching and extracting components tabwill treat UCLA and UCLA as separate categories strtrim() removes whitespace from the beginning and end of strings
substr(): extracting a substring substr() extracts a substring from a longer string *area code starts at 1, length=3 gen areacode = substr(phone, 1, 3) *extract last 5 characters as zip code gen zipcode = substr(address, -5, 5) substr(s, n1, n2) sis a string value or string variable n1is the starting position negative number counts from the end n2is the length of the string
+: concatenating strings *create full name variable: Last, First gen fullname = lastname + , + firstname Strings can be joined or concatenated together in a Stata command with a + String variables can be combined with string constants this way
String matching For matching strings exactly, we can use the == operator * for regular expression functions help regexm For more flexible pattern matching, Stata has a number of functions that use regular expressions e.g. to find strings that contain either US or USA and may or may not contain periods US U.S. USA U.S.A. See help regexm See help strmatch Regular expressions are beyond the scope of this workshop
Encoding strings into numeric variables Categorical variables are often initially coded as strings But most estimation commands require numeric variables * convert hospital to numeric, generate new variable encode hospital, gen(hospnum) encodeconverts string variables to numeric assigns a numeric value to each distinct string value applies value labels of the original string values Use the gen() option to create a new variable Or instead use replaceto overwrite the original string variable The ordering of the categories is alphabetical Remember, when browsing, string variables will appear red while numeric variables with labels will appear blue
Convert number variables stored as strings to numeric with destring Sometimes, variables with number values are loaded as strings into Stata. *convert string wbc to numeric and overwrite destring wbc, replace This can happen can a character value is mistakenly entered, or a non-numeric code (e.g. NA ) is used for missing. Or the variable was saved as a string in other software (e.g. Excel) We do not want to use encodehere, because the variable values are truly numbers rather than categories we would not want the 1.25 converted to a category. Instead, we can use destring, which directly translates numbers stored as strings into the numbers themselves.
Appending data sets append
Appending: adding observations We often wish to combine data sets that are split into multiple files that have the same variables (more or less) Data collected over several waves of time Data collected from different labs/sources ID DOB Weight Insured 101 3-3-1981 175 1 ID DOB Weight Insured Loaded in Stata 102 2-14-1975 213 0 101 3-3-1981 175 1 103 12-10-1990 198 1 102 2-14-1975 213 0 = 103 12-10-1990 198 1 + 201 4-29-1970 150 0 ID DOB Weight Insured 202 12-15-1963 254 0 On hard drive 201 4-29-1970 150 0 203 1-10-1962 199 1 202 12-15-1963 254 0 203 1-10-1962 199 1























 variables")






function")



: converting string dates to")
 function accepts dates in")






: trimming white space")
: extracting a substring")