Introduction to JMP Text Explorer Platform: Unveiling Text Exploration Tools

"Discover the power of JMP tools for text exploration with examples of data curation steps, quantifying text comments, and modeling ratings data. Learn about data requirements, overall processing steps, key definitions, and the bag of words approach in text analysis using Amazon gourmet food review data."

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Introduction to JMP Text Explorer Platform Jeff Swartzel and Tracy Desch With credit to Scott Reese and Jeremy Christman
Objectives To introduce Text Exploration via JMP tools To provide examples of data curation steps Illustrate ways to quantify text comments Explore modeling ratings data with quantified text comments
Data requirements Stacked data file One row per comment Matched ratings There can be exceptions to this approach. Make sure that you don t have duplicate documents in your corpus!
Overall process 1) Data preparation aka Curation 1) Tokenizing 2) Recoding 3) Phrasing 4) Stemming 5) Stopwords 2) Analysis 1. Which terms are most common? 2. What context are terms used? 3. Which terms appear together? Are there recurring themes? 3)Modeling 1) Save Vectors to table 2) Model building
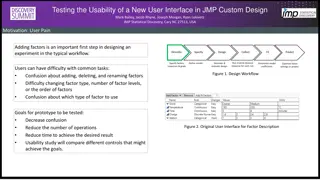
Our Data Source Amazon Products Reviews and Metadata from 1996 to 2014 Found here: http://jmcauley.ucsd.edu/data/amazon/ We focused on gourmet food review summaries TASTES GOOD AND IS GOOD FOR YOU -5 stars I wish I could find these in a store instead of online! -5 stars Not natural/organic at all -1 star Mixed thoughts -3 stars bugs all over it -2 stars Flavorful, great price, and surprisingly not that hot -5 stars
Key Definitions Term smallest piece of text, similar to a word in a sentence Phrase collection of terms that occur together Document all of the terms in a specific row/column intersection This is often the panelist s response to a single question. Corpus- a collection of documents, a single column Stemming the process of removing word endings from words with the same beginning. Dogs , Doggies , Dog all can be stemmed to Dog- so they are counted the same
Overall process- bag of words approach Document term matrix built A table that is used to COUNT all the terms Maintained in the background due to size Very Sparse matrix (not many data points) Basis for most of the Text Analysis options The manner in which words are counted can be modified For example: Yes or No For example: No occurrence, One occurrence, or Many occurrences Singular Value Decomposition (will be discussed later ) A method of dimensionality reduction Preserves as much information as possible and reduces the number of columns
How does it work? The Document Term Matrix (DTM) is a table of all terms. Every term is given its own column Default setting is to create Binary responses for each term: 1 = Yes the term is present in the comment 0 = No the term is NOT present in the comment
Counting There are several ways to count the terms. JMP refers to this as Weighting The weighting determines the values that go into the cells of the document term matrix. Binary: 1 if a term occurs in each document and 0 if not. Ternary: 2 if a term occurs more than once in each document, 1 if it occurs only once and 0 otherwise. Frequency: The count of a term s occurrence in each document. Log Freq: Log10 ( 1 + x ), where x is the count of a term s occurrence in each document. TF IDF: Term Frequency- Inverse Document Frequency. This is the default approach. A method of counting that accounts for how often a term is used by the total number of uses TF * log( nDoc / nDocTerm ). The terms in the formula are defined as follows: TF = frequency of the term in the document nDoc = number of documents in the corpus nDocTerm = number of documents that contain the term
CURATION Why Curation- JMP s bag of words approach uses a frequency count for analysis Therefore, HOW you count the words matters. Curation is the process of wrangling the data into a way that is useful for you. For example, would you count the following as separate terms or the same: Perfume, Parfume, Pefume, Perfumes, perfumed? Clean, Kleen, Cleaner, Cleaning lady, Cleaners, cleaned, cleaning? Perfume, scent, aroma, odor, smell, fragrance?
CURATION Curation tools Recode Enables you to change the values for one or more terms. Select the terms in the list before selecting this option. Always recode before stemming Add phrase Adds the selected phrases to the Term List and updates the Term Counts accordingly. Only added phrases will be included in the analysis and Document Term Matrix Stemming Combining words with identical beginnings (stems) by removing the endings that differ. This results in jump , jumped , and jumping all being treated as the term jump . Add stop word Excludes a word that is not providing benefit to the analysis. For example, if every review contains, diaper this does not provide additional benefit to the analysis. There is a default list of stop words (such as, the, of, or etc.) that can be modified and saved. Although stop words are not eligible to be terms, they can be used in phrases.
CURATION Recode example Used for the following: To correct typos or misspellings Combining synonyms Grouping terms together based upon category expertise of known themes or topics
ANALYSIS Common Analysis questions 1.Which terms are most common? 2.What context are terms used? 3.Which terms appear together/ are there recurring themes? 4.How can I use this in a predictive model?
ANALYSIS Topic Analysis, Rotated SVD Performs a varimax rotated singular value decomposition of the document term matrix to produce groups of terms called topics. In other words It takes the Document Term Matrix, which is mostly 0 s, and converts it into a more compact data set where topics are oriented towards a set of words. Topic analysis is similar to factor analysis. You need to set the number of vectors, which is how many topics you will end up with. Negative values indicate that a term occurs less frequently compared to terms with positive values.
ANALYSIS Which terms appear together? Rotated SVD Red hotspot > Topic Analysis, Rotated SVD Let s start with 20 For real analysis, you would modify this several times to generate a meaningful set Keep all defaults for now Select OK In future runs, you could modify the weighting
ANALYSIS A note on Iterations Data cleaning will continue after you conduct your SVD. This most often takes place as: Clean the data, Conduct SVD, Clean the data, Conduct SVD repeat until your data is most meaningful to you.
ANALYSIS Which terms appear together? Iterate to find the optimal topics by modifying the following: Number of topics Stop words Consider low frequency words as stop words Use various approaches on your newly quantified text to improve your understanding of the text: Partition- shows biggest breaks in the data Generalized regression- shows model effects Tabulate then Graphbuilder of topics- shows biggest differences between products
ANALYSIS How can I use this in a predictive model? Use SVD to understand themes (like PC or Factor Analysis) This helps: Group comments by theme Discover the common themes much faster Turn comments into series of continuous factors Implemented Directly in JMP 14
ANALYSIS How can I use this in a predictive model? We will start with the Topic Analysis, Rotated SVD results Approach: 1. Curate data to useful topics of interest 2. Save vectors for each topic to the data table 3. Use various tools to further analysis and drive understanding of impact
Key points to remember: Text Explorer is intended to combine similar terms, recode terms, and provide understanding on underlying patterns to enable efficient exploration of the comments. JMP uses a bag of words approach- frequency matters, not order. Iterative steps will take time and effort. It is still necessary to always explore and read actual verbatims JMP has Show Text tool that can help with this Category expertise will result in the most robust learnings and insight creation.
Overall process (one more time) 1) Data preparation aka Curation 1) Tokenizing 2) Recoding 3) Phrasing 4) Stemming 5) Stopwords 2) Analysis 1. Which terms are most common? 2. What context are terms used? 3. Which terms appear together? Are there recurring themes? 3)Modeling 1) Save Vectors to table 2) Model building
Remember: JMP Text tools are intended to enable more insight generation by helping to make you more efficient! Context is critical Use SHOW TEXT
Set Display Options to be default File > Preferences > Platform > Text Explorer




















")


![Guardians of Collection Enhancing Your Trading Card Experience with the Explorer Sleeve Bundle [4-pack]](/thumb/3698/guardians-of-collection-enhancing-your-trading-card-experience-with-the-explorer-sleeve-bundle-4-pack.jpg)