Understanding Open MPI: A Comprehensive Overview

Open MPI is a high-performance implementation of MPI, widely used in academic, research, and industry settings. This article delves into the architecture, implementation, and usage of Open MPI, providing insights into its features, goals, and practical applications. From a high-level view to detailed run-time parameters, this overview covers essential aspects for getting started with Open MPI.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Open MPI China MCP 1
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
What is MPI? Message Passing Interface De facto standard Not an official standard(IEEE, IETF) Written and ratified by the MPI Forum Body of academic, research, and industry representatives MPI spec MPI-1 published in 1994 MPI-2 published in 1996 MPI-3 published in 2012 Specified interfaces in C, C++, Fortran 77/90 4
MPI High-Level View User Application MPI API Operation System
MPI Goal High-level network API Abstract away the underlying transport Easy to use for customers API designed to be friendly to high performance network Ultra low latency (nanoseconds matter) Rapid ascent to wire-rate bandwidth Typically used in High Performance Computing(HPC) environments Has a bias for large compute jobs HPC definition is evolving MPI starting to be used outside of HPC MPI is a good network IPC API 6
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
Open MPI Overview OpenMPI is an open source, high-performance implementation of MPI Open MPI represents the union of four research/academic, open source MPI implementations: LAM(Local Area Multicomputer)/MPI, LA(Los Alamos)/MPI, FT-MPI(Fault-Tolerant MPI) and PACX- MPI(Parallel Computer eXtension MPI) Open MPI has three main abstraction project layers Open Portable Access Layer (OPAL): Open MPI's core portability between different operating systems and basic utilities. Open MPI Run-Time Environment (ORTE): Launch, monitor individual processes, and group individual processes in to jobs Open MPI (OMPI): Public MPI API and only one exposed to applications. 8
Open MPI High-Level View MPI Application Open MPI (OMPI) Project Open MPI Run-Time Environment (ORTE) Project Open Portable Access Layer (OPAL) Project Operation System Hardware
Project Separation MPI Application libompi libopen-rte libopen-pal Operation System Hardware 10
Library dependencies MPI Application libompi libopen-rte libopen-pal Operation System Hardware 11
Plugin Architecture Open MPI architecture design Portable, high-performance implementation of the MPI standard Share common base code to meet widely different requirement Run-time loadable components were natural choice, the same interface behavior can be implemented multiple different ways. Users can then choose, at run time, which plugin(s) to use Plugin Architecture Each project is structured similarly Main / Core code Components(Plugins) Frameworks Governed by the Modular Component Architecture 12
MCA Architecture Overview User Application MPI API Modular Component Architecture (MCA) Framework Framework Framework Framework Framework Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. Comp. 13
MCA Layout MCA Top-level architecture for component services Find, load, unload components Frameworks Targeted set of functionality Defined interfaces Essentially: a group of one type of plugins E.g., MPI point-to-point, high-resolution timers Components Code that exports a specific interface Loaded/unloaded rum-time Plugins Modules A components paired with resources E.g., TCP component loaded, find 2 IP interface(eth0, eth1), make 2 TCP modules 14
OMPI Architecture Overview OMPI Layer MPI one-sided communicatio n interface( osc) MPI Byte Transfer Layer (btl) MPI collective operations (coll) Memory Pool Framework (mpool) Framework Base tcp sm grdma rgpusm. Comp. Comp. Comp. Base sm tuned pt2pt. rdma Base Base 15
ORTE Architecture Overview ORTE Layer Process Lifecycle Management (PLM) OpenRTE Group Communicati on(grpcomm) I/O Routing table for the RML (routed) Framework Forwarding service (iof) Base tm slurm pmi bad Comp. Comp. Comp. hnp radix direct Base Base Base tool 16
OPAL Architecture Overview OPAL Layer High Hardware locality (hwloc) Compression Framework (compress) IP interface (if) Framework resolution timer (timer) Base Posix_ipv4 Linux_ipv6 bzip gzip Comp. Comp. Comp. linux external hwloc151 Base Base Base dawin 17
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
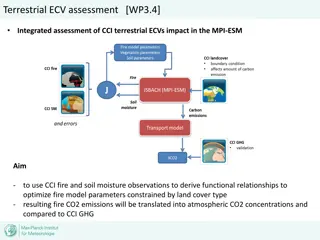
Open MPI TI Implementation Open MPI on K2H platform All components in 1.7.1 are supported Launching and initial interfacing by using SSH Adding BTLs for SRIO and Hyperlink transports MPI Application A15 SMP Linux A15 SMP Linux Ethernet MPI MPI Hyperlink IPC IPC SRIO Open CL Open CL IPC IPC Shared Shared K2H K2H memory/Navigato r memory/Navigato r subsyste subsyste Kern el Kern el Kern el Kern el Kern el Kern el C66x C66x m m OpenMP Run-time OpenMP Run-time 19 Node 0 Node 1
OMPI TI Added Components OMPI Layer MPI one-sided communicatio n interface( osc) MPI Byte Transfer Layer (btl) MPI collective operations (coll) Memory Pool Framework (mpool) Framework Base hlink srio grdma rgpusm. Comp. Comp. Comp. Base sm tuned pt2pt. rdma Base Base 20
OpenMPI Hyperlink BTL Hyperlink is TI-proprietary high speed, point-to-point interface, with 4 lanes up to 12.5Gbps (maximum transfer of 5.5-6 Gbytes/s). New BTL module has been added to ti-openmpi (openmpi 1.7.1 based) to support transport over Hyperlink. MPI Hyperlink communication is driven by A15 only. K2H device has 2 Hyperlink ports (0 and 1) allowing one SoC to connect directly with two neighboring SoCs. Daisy chaining is not supported. Additional connectivity can be obtained by mapping common memory region in intermediate node Data transfers are operated by EDMA Hyperlink BTL support is seamlessly integrated into OpenMPI run-time: Example code to run mpptest using 2 nodes over hyperlink: /opt/ti-openmpi/bin/mpirun --mca btl self,hlink -np 2 -host c1n1,c1n2 ./mpptest -sync logscale Example code to run nbody using 4 nodes hyperlink: /opt/ti-openmpi/bin/mpirun --mca btl self,hlink -np 4 -host c1n1,c1n2,c1n3,c1n4 ./nbody 1000 HL1 HL1 K2H K2H HL1 HL1 K2H K2H HL0 HL0 HL0 HL0 HL0 HL0 3 node Hyperlink topology 4 node Hyperlink topology HL1 HL1 K2H HL0 HL1 K2H K2H 21
OpenMPI Hyperlink BTL connection types Node 2 writes to Node 3 Node 3 Node 2 src dst Adjacent connections Local read Local read src dst Node 3 writes to Node 2 Same memory block mapped via both Hyperlink ports (to different nodes), used only for diagonal uni- directional connection Node 3 reads from Node 2t Node 2 Node 3 HL1 HL1 dst transfer Same memory block mapped via both Hyperlink ports (to different nodes), used only for diagonal uni- directional connection src Sending fragment from node 1 to node 3 HL0 HL0 Node 3 writes to Node 4 Node 1 writes to Node 2 Diagonal connections HL0 Sending fragment from node 3 to node 1 HL0 src HL1 HL1 transfer dst Node 1 Node 4 Node1 reads from Node 4 22
OpenMPI SRIO BTL Serial RapidIO connections are high speed low-latency connections that can be switched via external switching fabric (SRIO switches) or by K2H on-chip packet forwarding tables (when SRIO switch is not available) K2H device has 4 SRIO lanes that can be configured as 4x1 lane links, or 1x4 lane link. Wire speed can be up to 5Gbps, with data link speed of 4 Gbps (due to 8/10b encoding) Texas Instruments ti-openmpi (based on openmpi 1.7.1) includes SRIO BTL based on SRIO DIO transport, using Linux rio_mport device driver. MPI SRIO communication is driven by A15 only. SRIO nodes are statically enumerated (current support) and programming of packet forwarding tables is done inside MPI run-time, based on list of participating nodes. HW topology is specified by JSON file Programming of packet forwarding tables is static and allows HW-assisted routing of packets w/o any SW intervention in transferring nodes. Packet forwarding table has 8 entries (some limitations can be encountered based on topology and traffic patters) Each entry specify min-SRIO-ID, max-SRIO-ID, outgoing port External SRIO fabric typically provide non-blocking switching capabilities and might be favorable for certain applications and HW designs SRIO BTL, based on destination hostname determines outgoing port and destination ID. Previously programmed packet forwarding tables in all nodes ensure deterministic routability to destination node. SRIO BTL support is seamlessly integrated into OpenMPI run-time: Example code to run mpptest using 2 nodes over SRIO: /opt/ti-openmpi/bin/mpirun --mca btl self,srio -np 2 -host c1n1,c1n2 ./mpptest -sync logscale Example code to run nbody using 12 nodes over SRIO: /opt/ti-openmpi/bin/mpirun --mca btl self,srio -np 12 -host c1n1,c1n2,c1n3,c1n4,c4n1,c4n2,c4n3,c4n4,c7n1,c7n2,c7n3,c7n4 ./nbody 1000 23
OpenSRIO BTL possible topologies star topology SRIO switch K2H K2H K2H K2H K2H K2H Packet forwarding capability allows creation of HW virtual links (no SW operation!) K2H K2H K2H K2H K2H K2H 2-D torus (16-nodes) K2H K2H Connections with 4 lanes per link K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H K2H Full connectivity of 4 nodes 1 lane per link 24
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
Open MPI Run-time Parameters MCA parameters are the basic unit of run-time tuning for Open MPI. The system is a flexible mechanism that allows users to change internal Open MPI parameter values at run time If a task can be implemented in multiple, user-discernible ways, implement as many as possible and make choosing between them be an MCA parameter Service provided by the MCA base Does not mean that they are restricted to the MCA components of frameworks OPAL, ORTE, and OMPI projects all have base parameters Allows users to be proactive and tweak Open MPI's behavior for their environment. It s allows users to experiment with the parameter space to find the best configuration for their specific system. 26
MCA parameters lookup order 1. mpirun command line mpirun mca <name> <value> 2. Environment variable export OMPI_MCA_<name> <value> 3. File, these location are themselves tunable $HOME/.openmpi/mca-params.conf $prefix/etc/openmpi-mca-params.conf 4. Default value 27
MCA run-time parameters usage Get the MCA information The ompi_info command can list the parameters for a given component, all the parameters for a specific framework, or all parameters. /opt/ti-openmpi/bin/ompi_info param all all Show all the MCA parameters for all components that ompi_info finds /opt/ti-openmpi/bin/ompi_info param btl all Show all the MCA parameters for all BTL components /opt/ti-openmpi/bin/ompi_info param btl tcp Show all the MCA parameters for TCP BTL component MCA Usage The mpirun command execute serial and parallel jobs in Open MPI /opt/ti-openmpi/bin/mpirun mca orte_base_help_aggregate 0 mca btl_base_verbose 100 mca btl self, tcp np 2 host k2node1, k2node2 /home/mpiuser/nbody 1000 Select the btl_base_verbose and use tcp for transport 28
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
Open MPI API Usage Open MPI API is standard MPI API, refer to the following link to get more information: http://www.open-mpi.org/doc/ This example project locate at <mcsdk-hpc_install_path>/demos/testmpi MPI_Init (&argc, &argv); /* Startup */ /* starts MPI */ MPI_Comm_rank (MPI_COMM_WORLD, &rank); /* Who am I?*/ /* get current process id */ MPI_Comm_size (MPI_COMM_WORLD, &size);/* How many peers do I have */ /* get number of processes */ { /* Get the name of the processor */ char processor_name[320]; int name_len; MPI_Get_processor_name(processor_name, &name_len); printf("Hello world from processor %s, rank %d out of %d processors\n", processor_name, rank, size); gethostname(processor_name, 320); printf ("locally obtained hostname %s\n", processor_name); } MPI_Finalize(); /* Finish the MPI application and release sources*/ 30
Run the Open MPI example Use the mpirun and mca parameters to run the example /opt/ti-openmpi/bin/mpirun mca btl self, sm, tcp np 8 host k2node1, k2node2 ./testmpi Output messages >>> Hello world from processor k2hnode1, rank 3 out of 8 processors locally obtained hostname k2hnode1 Hello world from processor k2hnode1, rank 0 out of 8 processors locally obtained hostname k2hnode1 Hello world from processor k2hnode2, rank 5 out of 8 processors locally obtained hostname k2hnode2 Hello world from processor k2hnode2, rank 4 out of 8 processors locally obtained hostname k2hnode2 Hello world from processor k2hnode2, rank 7 out of 8 processors locally obtained hostname k2hnode2 Hello world from processor k2hnode2, rank 6 out of 8 processors locally obtained hostname k2hnode2 Hello world from processor k2hnode1, rank 1 out of 8 processors locally obtained hostname k2hnode1 Hello world from processor k2hnode1, rank 2 out of 8 processors locally obtained hostname k2hnode1 <<< 31
Agenda MPI Overview Open MPI Architecture Open MPI TI Implementation Open MPI Run-time Parameters Open MPI Usage Example Getting Started
Getting Started Bookmarks URL Download http://software- dl.ti.com/sdoemb/sdoemb_public_sw/mcsdk_hpc/latest/index_FDS.html Getting Started Guide http://processors.wiki.ti.com/index.php/MCSDK_HPC_3.x_Getting_Started_Guid e TI OpenMPI User Guide http://processors.wiki.ti.com/index.php/MCSDK_HPC_3.x_OpenMPI Open MPI Open Source High Performance Computing, Message Passing Interface (http://www.open-mpi.org/) Open MPI Training Documents http://www.open-mpi.org/video/ Support http://e2e.ti.com/support/applications/high-performance-computing/f/952.aspx 33