Efficient and Effective Duplicate Detection in Hierarchical Data

This study explores the efficient and effective detection of duplicates in hierarchical data, focusing on fuzzy duplicates and hierarchical relationships in XML. It discusses the current and proposed systems, including the use of Bayesian networks for similarity computations. The methods involve vector of terms, sorted XML neighborhood method, and pruning techniques for enhanced efficiency and precision. Examples and discussions on Bayesian network, directed acyclic graphs, and dependencies are also included.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
EFFICIENT AND EFFECTIVE DUPLICATE DETECTION IN HIERARCHICAL DATA Topic Approval On:02/09/2013 Slide Approval On:02/09/2013 Topic and Slide Approved By: Mrs Jisha P Abraham Sandra Achu George Roll no:49 S7R Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data CONTENTS Introduction Current system Proposed system Bayesian Network Construction Computing Probabilities Network Pruning Conclusion References Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data INTRODUCTION Fuzzy duplicates Duplicates not exactly equal Detect duplicates despite differences in data Hierarchical relationships in xml Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data CURRENT SYSTEM Vector of terms DogmatiX Overlays Sorted XML Neighborhood Method(SXNM) Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data PROPOSED SYSTEM Hierarchical data-XML Xml features Pruning Efficiency Precision Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data DUPLICATES EXAMPLE Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data BAYESIAN NETWORK Directed acyclic graph Nodes-random variables Edges-dependencies Compute similarity Dept of computer science, MACE Kothamangalam
BAYESIAN NETWORK(Cont..) Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data COMPUTING PROBABILITIES Prior probabilities Conditional probabilities CP1 CP2 CP3 CP4 Final Probability Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data CONDITIONALPROBABILITY CP FORMULA EXAMPLE 1 P(Vtij|tij[a1], tij[an])= 1 k n|tij[ak] =1wak subject to 1 k nwak =1 P(Vprs11|prs11[name],prs11[d ob]) P(Vpob11|pob11[value]) P(Veml11|eml11[value]) P(Vaddij|addij[value]) P(Cprs11|pob11,cnt11) P(Ccnt11|eml11,add**) 2 P(Ctij|t1ij,t2ij, ,tnij)=1/n* nk=1 tkij Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data CONDITIONAL PROBABILITY(Cont..) CP FORMULA EXAMPLE 3 P(tij|Vtij,Ctij)={1 iff Vtij=Ctij=1 0 Otherwise P(prs11|Vprs11,Cprs11) P(pob11|Vpob11) P(cnt11|Ccnt11) P(eml11|Veml11) P(addij|Vaddij) 4 P(t**|t1* ,t2*, ,tn*)=1/n nk=1tk* P(ti*|ti1,ti2, ,tin)={1 iff j|tij=1 0 Otherwise P(add**|add1*,add2*) P(add1*|addi1) Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data FINAL PROBABILITY COURTESY:IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING Dept of computer science, MACE Kothamangalam
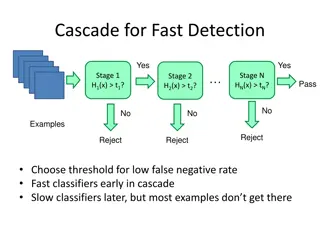
Efficient and effective Duplicate Detection In Hierarchical Data ACCELERATING NETWORK EVALUATION Complexity-O(n1 n2) Analyze whole network Time consuming Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data NETWORK PRUNING Lossless pruning strategy Optimize network evaluation Threshold Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data PRUNING ALGORITHM Input: The node N, threshold T Get ordered list of parents in N Assign maximum probability of each node as 1 currentscore 0 for each node n in L do If n is a value node then Compute similarities else Determine newthreshold Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data PRUNING ALGORITHM (Cont..) Call NetworkPruning recursively end if ComputeProbability if currentscore < T then End network evaluation End for Return currentScore Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data EFFECT OF NODE ORDER ON PRUNING Accelerate network evaluation Heuristic for sorting Depth Average string size Distinctiveness Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data VARYING PRUNING FACTOR Pruning factor Lower pruning factor Faster Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data ADVANTAGES OF PROPOSED SYSTEM Flexible Pruning-efficiency Precision Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data CONCLUSION Duplicate detection Bayesian network Compute probabilities Pruning Strategy-Efficiency Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data REFERENCES L. Leita o, P. Calado, and M. Weis, Structure-Based Inference ofXML Similarity for Fuzzy Duplicate Detection, Proc. 16th ACMInt l Conf. Information and Knowledge Management, pp. 293-302,2007 P. Calado, M. Herschel, and L. Leita o, An Overview of XML Duplicate Detection Algorithms, Soft Computing in XML Data Management, Studies in Fuzziness and Soft Computing,vol. 255,pp. 193-224, 2010 Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data REFERENCES(Cont..) L. Leita o and P. Calado, Duplicate Detection through Structure Optimization, Proc. 20th ACM Int l Conf. Information and Knowledge Management, pp. 443-452, 2011 Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data THANK YOU Dept of computer science, MACE Kothamangalam
Efficient and effective Duplicate Detection In Hierarchical Data Dept of computer science, MACE Kothamangalam








")