Challenges in Developing a Coherent Provenance Architecture
In the IS-ENES Cases, challenges arise in establishing a formal model for provenance architecture across various data lifecycle steps. The need for a coherent approach is emphasized to manage provenance information artifacts effectively. These challenges demand the creation of a structured framework to collect and maintain provenance data throughout the data lifecycle.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
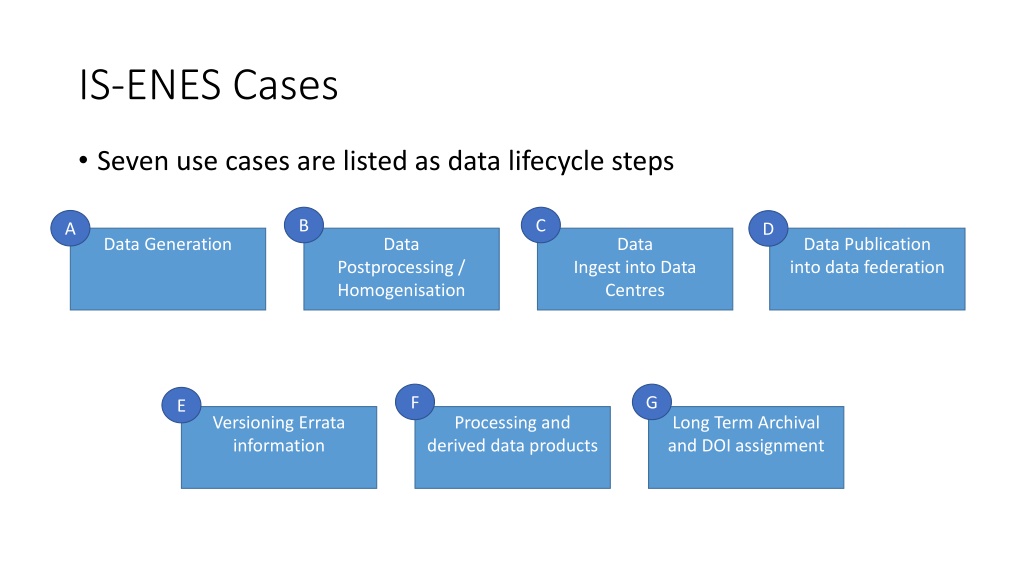
IS-ENES Cases Seven use cases are listed as data lifecycle steps B C A D Data Generation Data Data Data Publication into data federation Postprocessing / Homogenisation Ingest into Data Centres F G E Versioning Errata information Processing and derived data products Long Term Archival and DOI assignment
IS-ENES Cases The seven use cases have provenance requirements B C A D Data Generation Data Data Data Publication into data federation Postprocessing / Homogenisation Files organized in collections characterized by facets defined in CVs Ingest into Data Centres Data center specific ingest workflow logs Formal model documentation (ES-DOC) Connection of files with PIDs and ES-DOC F G E Versioning Errata information Processing and derived data products Long Term Archival and DOI assignment Errata documents connected with PIDs Derived data products, processing logs (input data, tool info) Author information, DOI for collections
IS-ENES Cases Provenance Challenges Different ENES use cases for provenance collection and management along the complete data life cycle. Large amount of provenance related information artefacts collected along the data life cycle. A coherent, formal model based on overall provenance architecture is missing.
IS-ENES Cases Challenge 3 Suggest a coherent, formal model based on overall provenance architecture B C A D Data Generation Data Data Data Publication into data federation Postprocessing / Homogenisation Files organized in collections characterized by facets defined in CVs Ingest into Data Centres Data center specific ingest workflow logs Formal model documentation (ES-DOC) Connection of files with PIDs and ES-DOC F G E Versioning Errata information Processing and derived data products Long Term Archival and DOI assignment Errata documents connected with PIDs Derived data products, processing logs (input data, tool info) Author information, DOI for collections
IS-ENES Cases Challenge 3 Why is a coherent, formal model based on overall provenance architecture needed? B C A D Data Generation Data Data Data Publication into data federation Postprocessing / Homogenisation Files organized in collections characterized by facets defined in CVs Ingest into Data Centres Data center specific ingest workflow logs Formal model documentation (ES-DOC) Connection of files with PIDs and ES-DOC F G E Versioning Errata information Processing and derived data products Long Term Archival and DOI assignment Errata documents connected with PIDs Derived data products, processing logs (input data, tool info) Author information, DOI for collections
Specific requirements for provenance? Since each step already collects some type of provenance information, is it OK to just map them to PROV independently? PROV metadata for Generation PROV metadata for Postprocessing PROV metadata for Data Centres Ingest Data center specific ingest workflow logs PROV metadata for Data Publication Formal model documentation (ES-DOC) Files organized in collections characterized by facets defined in CVs Connection of files with PIDs and ES-DOC PROV metadata for Versioning Errata PROV metadata for Processing PROV metadata for LTArchival/DOI Errata documents connected with PIDs Derived data products, processing logs (input data, tool info) Author information, DOI for collections
There are commonalities on the provenance metadata PROV metadata for Postprocessing NOTE: Common in the sense of they store similar metadata, not implying that they are the same metadata PROV metadata for Data Centres Ingest Data center specific ingest workflow logs Files organized in collections characterized by facets defined in CVs PROV metadata for Generation PROV metadata for Data Publication Formal model documentation (ES-DOC) Connection of files with PIDs and ES-DOC ES-DOC PROV metadata for Versioning Errata PROV metadata for LTArchival/DOI PROV metadata for Processing Errata documents connected with PIDs Author information, DOI for collections Derived data products, processing logs (input data, tool info)
Could we suggest a common PROV schema? PROV metadata for Data Centres Ingest PROV metadata for Postprocessing PROV metadata for Generation PROV metadata for Data Publication Common PROV Schema PROV metadata for Versioning Errata PROV metadata for LTArchival/DOI PROV metadata for Processing
Could we suggest a common PROV schema? PROV metadata for Data Centres Ingest PROV metadata for Postprocessing PROV metadata for Generation PROV metadata for Data Publication Common PROV Schema Question: Is PROV flexible enough to - Map to different institutions, processes and datasets? - include reference to input to build a provenance chain? - create a provenance registry? PROV metadata for Versioning Errata PROV metadata for LTArchival/DOI PROV metadata for Processing Idea: Handle each case as a black box - Keep the output metadata - include reference to input - Resolve input reference if more metadata is needed
In this context: What are the actual requirements of a provenance architecture? B C A D Data Generation Data Data Data Publication into data federation Postprocessing / Homogenisation Files organized in collections characterized by facets defined in CVs Ingest into Data Centres Data center specific ingest workflow logs Formal model documentation (ES-DOC) Connection of files with PIDs and ES-DOC F G E Versioning Errata information Processing and derived data products Long Term Archival and DOI assignment Errata documents connected with PIDs Derived data products, processing logs (input data, tool info) Author information, DOI for collections
A proposed set of requirements for provenance Architecture Provenance metadata should be lightweight The contents of the provenance metadata should contain only the metadata corresponding to the latest state and a reference to the source. The detailed history is only needed locally and can be unpacked on request. Provenance metadata should be self contained Limit the need of external entities/systems to interpret provenance provenance data should be retained / preserved close to the place at which it is generated / relevant. Provenance metadata should be resolvable Every link in the provenance chain should point to its origin Provenance should be backwards compatible Adding or changing provenance metadata should preserve the compatibility with previous instances, not requiring them to be updated.