Understanding Regular Expressions in Natural Language Processing

Dive into the world of regular expressions for text processing in NLP, learning about disjunctions, negations, patterns, anchors, and practical examples. Discover how to efficiently search for specific text strings using these powerful tools.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Natural Language Processing Lecture 4
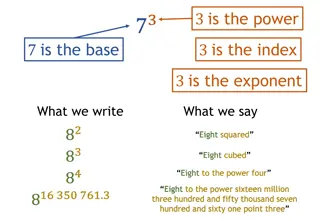
Regular expressions A formal language for specifying text strings How can we search for any of these? woodchuck woodchucks Woodchuck Woodchucks
Regular Expressions: Disjunctions Letters inside square brackets [] Pattern Matches [wW]oodchuck Woodchuck,woodchuck [1234567890] Any digit Ranges [A-Z] Pattern Matches Drenched Blossoms [A-Z] An upper case letter my beans were impatient [a-z] A lower case letter Chapter 1: Down the Rabbit Hole [0-9] A single digit
Regular Expressions: Negation in Disjunction Negations [^Ss] Carat means negation only when first in [] Pattern Matches Oyfn pripetchik [^A-Z] Not an upper case letter I have no exquisite reason [^Ss] Neither S nor s Look here [^e^] Neither e nor ^ Look up a^b now a^b The pattern a carat b
Regular Expressions: More Disjunction Woodchucks is another name for groundhog! The pipe | for disjunction Pattern Matches groundhog|woodchuck yours mine yours|mine a|b|c = [abc] [gG]roundhog|[Ww]oodchuck
Regular Expressions: ? * + . Pattern Matches color colour colou?r Optional previous char ab! aab! aaab! aaaab! aa*b! 0 or more of previous char ab! aab! aaab! aaaab! a+b! 1 or more of previous char baa baaa baaaa baaaaa baa+ begin begun begun beg3n beg.n Stephen C Kleene Kleene *, Kleene +
Regular Expressions: Anchors ^ $ Pattern ^[A-Z] ^[^A-Za-z] \.$ .$ Matches Palo Alto 1 Hello The end. The end? The end!
Example Find me all instances of the word the in a text. the Misses capitalized examples [tT]he Incorrectly returns other or theology [^a-zA-Z][tT]he[^a-zA-Z]
Errors The process we just went through was based on fixing two kinds of errors Matching strings that we should not have matched (there, then, other) False positives (Type I) Not matching things that we should have matched (The) False negatives (Type II) In NLP we are always dealing with these kinds of errors. Reducing the error rate for an application often involves two antagonistic efforts: Increasing accuracy or precision (minimizing false positives) Increasing coverage or recall (minimizing false negatives).
Precision and Recall Precision: How many selected items are relevant Recall: How many relevant items are selected 11
Accuracy and Precision Accuracy refers to the closeness of a measured value to a standard or known value. For example, if in lab you obtain a weight measurement of 3.2 kg for a given substance, but the actual or known weight is 10 kg, then your measurement is not accurate. In this case, your measurement is not close to the known value. Precision refers to the closeness of two or more measurements to each other. Using the example above, if you weigh a given substance five times, and get 3.2 kg each time, then your measurement is very precise. Precision is independent of accuracy. You can be very precise but inaccurate, as described above. You can also be accurate but imprecise. https://labwrite.ncsu.edu/Experimental%20Design/accuracyprecision.htm 12
Accuracy and Precision Accuracy refers to how close a measurement is to the true value. Precision is how consistent results are when measurements are repeated An easy way to remember the difference between accuracy and precision is: ACcurate is Correct (or Close to real value) PRecise is Repeating (or Repeatable) . 13
Text Normalization Every NLP task needs to do text normalization: Segmenting/tokenizing words in running text Normalizing word formats Segmenting sentences in running text
Tokenization Given a character sequence and a defined document unit, tokenization is the task of chopping it up into pieces, called tokens , perhaps at the same time throwing away certain characters, such as punctuation. Here is an example of tokenization Input: Friends, Romans, Countrymen, lend me your ears; Output: 17
How many words? I do uh main- mainly business data processing Fragments, filled pauses Seuss s cat in the hat is different from other cats! Lemma: same stem, part of speech, rough word sense cat and cats = same lemma Wordform: the full inflected surface form cat and cats = different wordforms
How many words? they lay back on the San Francisco grass and looked at the stars and their Type: an element of the vocabulary. Token: an instance of that type in running text. How many? 15 tokens (or 14) 13 types (or 12) (or 11?)
How many words? N = number of tokens V = vocabulary = set of types |V| is the size of the vocabulary Church and Gale (1990): |V| > O(N ) Tokens = N Types = |V| Switchboard phone conversations 2.4 million 20 thousand Shakespeare 884,000 31 thousand Google N-grams 1 trillion 13 million
Linux TR Command for basic text processing tr is an UNIX utility for translating, or deleting, or squeezing repeated characters. It will read from STDIN and write to STDOUT. tr stands for Translation. Syntax $ tr [OPTION] SET1 [SET2] If both the SET1 and SET2 are specified then tr command will replace each characters in SET1 with each character in same position in SET2. 21
Linux TR Command for basic text processing complement of a pattern echo abcdefghijklmnop | tr -c 'a' 'z' azzzzzzzzzzzzzzzz delete specific characters echo 'clean this up' | tr -d 'up' clean this the c option is combined with the d delete option to extract a phone number. echo 'Phone: 01234 567890' | tr -cd '[:digit:]' 01234567890 squeeze repeating characters s In the following example a string with too many spaces is squeezed to remove them. echo 'too many spaces here | tr -s '[:space:]' too many spaces here 22
Linux TR Command for basic text processing To truncate the first set to the second set use the t option. By Default tr will repeat the last character of the second set if the first and second sets are different lengths. Consider the following example. echo 'the cat in the hat' | tr 'abcdefgh' '123' t33 31t in t33 31t The last character of the second set is repeated to match any letter from c-h. Using the truncate option limits the matching to the length of the second set. echo 'the cat in the hat' | tr -t 'abcdefgh' '123' the 31t in the h1t find and replace echo "some_url_that_I_have" | tr "_" "-" some-url-that-I-have 23
Linux TR Command for basic text processing translate between "upper" and "lower" case characters is to use the "[:lower:]" and "[:upper:]" options: $ echo 'welcome to Computer Science' | tr "[:lower:]" "[:upper:]" WELCOME TO COMPUTER SCIENCE $ echo 'welcome to Computer Science' | tr "a-z" "A-Z WELCOME TO COMPUTER SCIENCE Delete newline: cat shakes.txt Line one Line two . cat shakes.txt | tr d \n White Space to Tabs tr [:space:] '\t < shakes.txt | more White Space to NewLine tr [:space:] '\n < shakes.txt | more 24
Linux TR Command for basic text processing $ tr [:upper:] [:lower:] < items.txt > output.txt $ cat output.txt 25
Simple Tokenization in UNIX tr -sc A-Za-z \n < shakes.txt | sort | uniq -c Given a text file, output the word tokens and their frequencies tr -scA-Za-z \n < shakes.txt | sort | uniq -c Change all non-alpha to newlines Sort in alphabetical order Merge and count each type Please study: https://www.thegeekstuff.com/2012/12/linux-tr-command/
More counting Merging upper and lower case tr A-Z a-z < shakes.txt | tr -sc A-Za-z \n | sort | uniq -c Sorting the counts tr A-Z a-z < shakes.txt | tr -sc A-Za-z \n | sort | uniq -c | sort -nr 23243 the 22225 i 18618 and 16339 to 15687 of 12780 a 12163 you 10839 my 10005 in 8954 d
Issues in Tokenization Finland Finlands Finland s ? What are, I am, is not Hewlett Packard ? state of the art ? lower-case lowercase lower case ? one token or two? ?? Finland s capital what re, I m, isn t Hewlett-Packard state-of-the-art Lowercase San Francisco m.p.h., PhD.
Tokenization: language issues French L'ensemble one token or two? L ? L ? Le ? Want l ensemble to match with un ensemble German noun compounds are not segmented Lebensversicherungsgesellschaftsangestellter life insurance company employee German information retrieval needs compound splitter
Tokenization: language issues Chinese and Japanese no spaces between words: Sharapova now lives in US southeastern Florida Further complicated in Japanese, with multiple alphabets intermingled Dates/amounts in multiple formats 500 $500K( 6,000 ) Katakana Hiragana Kanji Romaji End-user can express query entirely in hiragana!
Word Tokenization in Chinese Also called Word Segmentation Chinese words are composed of characters Characters are generally 1 syllable and 1 morpheme. Average word is 2.4 characters long. Standard baseline segmentation algorithm: Maximum Matching (also called Greedy)
Maximum Matching Word Segmentation Algorithm Given a wordlist of Chinese, and a string. Start a pointer at the beginning of the string Find the longest word in dictionary that matches the string starting at pointer Move the pointer over the word in string Go to 2
Max-match segmentation illustration the cat in the hat Thecatinthehat Thetabledownthere the table down there theta bled own there Doesn t generally work in English! But works astonishingly well in Chinese Modern probabilistic segmentation algorithms even better