Understanding Processor Speculation and Optimization

Dive into the world of processor speculation techniques and optimizations, including compiler and hardware support for speculative execution. Explore how speculation can enhance performance by guessing instruction outcomes and rolling back if needed. Learn about static and dynamic speculation, handling exceptions, and static multiple issue processing.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
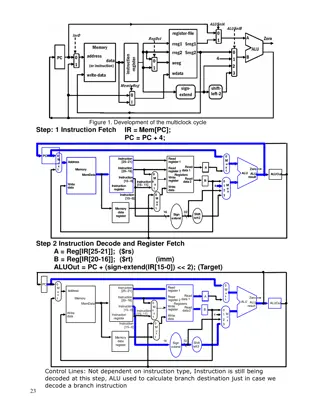
Chapter 4 The Processor 1
Speculation Guess what to do with an instruction Start operation as soon as possible Check whether guess was right If so, complete the operation If not, roll-back and do the right thing Common to static and dynamic multiple issue Examples Speculate on branch outcome instructions after the branch could be executed earlier Roll back if path taken is different Speculate on load a store that precedes a load does not refer to the same address, which would allow the load to be executed before the store Roll back if location is updated 2
Compiler/Hardware Speculation Compiler can reorder instructions e.g., move an instruction across a branch or a store across a load insert additional instructions that check the accuracy of the speculation, and include fix-up instructions to recover from incorrect guess Hardware can look ahead for instructions to execute Buffer results until it determines they are actually needed Flush buffers on incorrect speculation Buffers written to registers or memory if speculation is correct 3
Speculation and Exceptions What if exception occurs on a speculatively executed instruction? e.g., speculative load before null-pointer check, i.e. address it uses is not within bounds when the speculation is incorrect Compiler will ignore such exceptions until they really should occur Hardware buffers the exceptions until it is known the instruction causing it is no longer speculative Static speculation Can add ISA support for deferring exceptions Dynamic speculation Can buffer exceptions until instruction completion (which may not occur) 4
Static Multiple Issue Compiler groups instructions into issue packets Group of instructions that can be issued on a single cycle Determined by pipeline resources required Most static issue processors also rely on the compiler to take on some responsibility for handling data and control hazards. The compiler s responsibilities may include static branch prediction and code scheduling to reduce or prevent all hazards. Think of an issue packet as a very long instruction Specifies multiple concurrent operations Very Long Instruction Word (VLIW) 5
Scheduling Static Multiple Issue Compiler must remove some/all hazards Reorder instructions into issue packets No dependencies within a packet Possibly some dependencies between packets Varies between ISAs; compiler must know! Pad with nop if necessary 6
LEGv8 with Static Dual Issue Two-issue packets One ALU/branch instruction One load/store instruction Instructions are paired and aligned on a 64-bit boundary ALU/branch, then load/store Pad an unused instruction with nop Address Instruction type Pipeline Stages n ALU/branch IF ID EX MEM WB n + 4 Load/store IF ID EX MEM WB n + 8 ALU/branch IF ID EX MEM WB n + 12 Load/store IF ID EX MEM WB n + 16 ALU/branch IF ID EX MEM WB n + 20 Load/store IF ID EX MEM WB 7
Hazards in the Dual-Issue LEGv8 More instructions executing in parallel EX data hazard Forwarding avoided stalls with single-issue Now can t use ALU result in load/store in same packet ADD X0, X0, X1 LDUR X2, [X0,#0] Split into two packets, effectively a stall Load-use hazard Still one cycle use latency, but now two instructions More aggressive scheduling required 9
Scheduling Example Schedule this for dual-issue LEGv8 Loop: LDUR X0, [X20,#0] // X0=array element ADD X0, X0,X21 // add scalar in X21 STUR X0, [X20,#0] // store result SUBI X20, X20,#8 // decrement pointer CMP X20, X22 // branch $s1!=0 BGT Loop ALU/branch Load/store cycle Loop: nop LDUR X0, [X20,#0] 1 SUBI X20, X20,#8 nop 2 ADD X0, X0,X21 nop 3 CMP X20, X22 nop 4 BGT Loop STUR X0, [X20,#0] 5 IPC = 6/5 = 1.2 (c.f. peak IPC = 2) 10 CPI = 0.83 Vs best case of 0.5
Loop Unrolling Replicate loop body to expose more parallelism Reduces loop-control overhead Use different registers per replication Called register renaming Avoid loop-carried anti-dependencies Load followed by a store of the same register Aka name dependence Reuse of a register name 11
Loop Unrolling Example ALU/branch Load/store cycle Loop: SUBI X20, X20,#32 LDUR X0, [X20,#0] 1 nop LDUR X1, [X20,#24] 2 ADD X0, X0, X21 LDUR X2, [X20,#16] 3 ADD X1, X1, X21 LDUR X3, [X20,#8] 4 ADD X2, X2, X21 STUR X0, [X20,#32] 5 ADD X3, X3, X21 STUR X1, [X20,#24] 6 CMP X20,X22 STUR X2, [X20,#16] 7 BGT Loop STUR X3, [X20,#8] 8 IPC = 15/8 = 1.875 Closer to 2, partly from reducing the loop control instructions and partly from dual issue execution Cost of performance improvement is 4 temporary registers and more than double the code size 12
Dynamic Multiple Issue Superscalar processors CPU decides whether to issue 0, 1, 2, each cycle Avoiding structural and data hazards Avoids the need for compiler scheduling Though it may still help to achieve good performance by moving the dependences apart and thereby increasing issue rate Code semantics ensured by the CPU Differences between superscalar and a VLIW processor the code, whether scheduled or not, is guaranteed by the hardware to execute correctly compiled code will always run correctly independent of the issue rate or pipeline structure of the processor Not the case in some VLIW Either recompilation required across different processor models, or Performance poor although runs correctly 13
Dynamic Pipeline Scheduling Allow the CPU to execute instructions out of order to avoid stalls But commit result to registers in order Example LDUR X0, [X21,#20] ADD X1, X0, X2 SUB X23,X23,X3 ANDI X5, X23,#20 Can start sub while ADD is waiting for LDUR 14
Dynamically Scheduled CPU Preserves dependencies Hold pending operands and operations Results also sent to any waiting reservation stations Reorder buffer for register writes Can supply operands for issued instructions 15
Register Renaming Reservation stations and reorder buffer effectively provide register renaming On instruction issue, it is copied to a reservation station If operand is available in register file or reorder buffer Copied to reservation station No longer required in the register; can be overwritten If operand is not in the register file or reorder buffer It will be provided to the reservation station by a functional unit Register update may not be required Out-of-order execution instructions can be executed in a different order than they were fetched The processor executes the instructions in some order that preserves the data flow order of the program 16
In-order commit The instruction fetch and decode unit issues instructions in order The commit unit writes the results to registers and memory in program fetch order The functional units are free to initiate execution whenever the data they need are available Today, all dynamically scheduled pipelines use in-order commit. 17
Speculation Predict branch and continue fetch and issue on the predicted path Don t commit until branch outcome determined Load speculation Avoid load and cache miss delay Predict the effective address Predict loaded value Load before completing outstanding stores Bypass stored values to load unit Don t commit load until speculation cleared 18
Why Do Dynamic Scheduling? Why not just let the compiler schedule code around dependences? Not all stalls are predicable e.g., cache misses cause unpredictable stalls Dynamic scheduling allows the processor to hide some of those stalls by continuing to execute instructions while waiting for the stall to end. Can t always schedule around branches Branch outcome is dynamically determined using dynamic branch prediction processor cannot know the exact order of instructions at compile time, since it depends on the predicted and actual behavior of branches Different implementations of an ISA have different latencies and issue widths Dynamic scheduling allows the hardware to hide most of the details of loop unrolling and register renaming for different pipeline structures 19
Does Multiple Issue Work? The BIG Picture The BIG Picture Yes, but not as much as we d like Programs have real dependencies that limit ILP Some dependencies are hard to eliminate e.g., pointer aliasing Some parallelism is hard to expose Limited window size during instruction issue Memory delays and limited bandwidth Hard to keep pipelines full Speculation by the compiler or the hardware can help if done well 20
Power Efficiency Complexity of dynamic scheduling and speculations requires power Multiple simpler cores may be better Microprocessor Year Clock Rate Pipeline Stages Issue width Out-of-order/ Speculation Cores Power i486 1989 25MHz 5 1 No 1 5W Pentium 1993 66MHz 5 2 No 1 10W Pentium Pro 1997 200MHz 10 3 Yes 1 29W P4 Willamette 2001 2000MHz 22 3 Yes 1 75W P4 Prescott 2004 3600MHz 31 3 Yes 1 103W Core 2006 2930MHz 14 4 Yes 2 75W UltraSparc III 2003 1950MHz 14 4 No 1 90W UltraSparc T1 2005 1200MHz 6 1 No 8 70W 21
4.11 Real Stuff: The ARM Cortex-A8 and Intel Core i7 Pipelines Cortex A53 and Intel i7 Processor ARM A53 Intel Core i7 920 Market Thermal design power Personal Mobile Device 100 milliWatts (1 core @ 1 GHz) 1.5 GHz 4 (configurable) Yes Dynamic 2 8 Static in-order Server, cloud 130 Watts Clock rate Cores/Chip Floating point? Multiple issue? Peak instructions/clock cycle Pipeline stages Pipeline schedule 2.66 GHz 4 Yes Dynamic 4 14 Dynamic out-of-order with speculation 2-level 32 KiB I, 32 KiB D 256 KiB (per core) 2-8 MB Branch prediction 1st level caches/core 2nd level caches/core 3rd level caches (shared) Hybrid 16-64 KiB I, 16-64 KiB D 128-2048 KiB (platform dependent) 22
ARM Cortex-A53 Pipeline The first three stages fetch two instructions at a time and try to keep a 13- entry instruction queue full. It uses a 6k-bit hybrid conditional branch predictor, a 256-entry indirect branch predictor, and an 8-entry return address stack to predict future function returns. The prediction of indirect branches takes an additional pipeline stage. When the branch prediction is wrong, it empties the pipeline, resulting in an eight-clock cycle misprediction penalty. The decode stages of the pipeline determine if there are dependences between a pair of instructions, which would force sequential execution, and in which pipeline of the execution stages to send the instructions. The instruction execution section primarily occupies three pipeline stages and provides one pipeline for load instructions, one pipeline for store instructions, two pipelines for integer arithmetic operations, and separate pipelines for integer multiply and divide operations. The execution stages have full forwarding between the pipelines. Floating-point and SIMD operations add a two more pipeline stages to the instruction execution section and feature one pipeline for multiply/divide/square root operations and one pipeline for other arithmetic operations. 24
ARM Cortex-A53 Performance Ideal CPI = 0.5 Best CPI = 1.0 Median = 1.3 Worst = 8.6 Pipeline hazards 60% of stalls Memory hazards 40% stalls Pipeline stalls are caused by branch mispredictions, structural hazards, and data dependencies between pairs of instructions 25
Core i7 Performance Ideal CPI = 0.25, best = 0.44, median = 0.79, worst = 2.67 Branch misprediction Min = 0%, median = 2%, max = 10% Wasted work Min = 1%, median = 18%, max = 39% 27
4.12 Instruction-Level Parallelism and Matrix Multiply Matrix Multiply Unrolled C code 1 #include <x86intrin.h> 2 #define UNROLL (4) 3 4 void dgemm (int n, double* A, double* B, double* C) 5 { 6 for ( int i = 0; i < n; i+=UNROLL*4 ) 7 for ( int j = 0; j < n; j++ ) { 8 __m256d c[4]; 9 for ( int x = 0; x < UNROLL; x++ ) 10 c[x] = _mm256_load_pd(C+i+x*4+j*n); 11 12 for( int k = 0; k < n; k++ ) 13 { 14 __m256d b = _mm256_broadcast_sd(B+k+j*n); 15 for (int x = 0; x < UNROLL; x++) 16 c[x] = _mm256_add_pd(c[x], 17 _mm256_mul_pd(_mm256_load_pd(A+n*k+x*4+i), b)); 18 } 19 20 for ( int x = 0; x < UNROLL; x++ ) 21 _mm256_store_pd(C+i+x*4+j*n, c[x]); 22 } 23 } 28
4.12 Instruction-Level Parallelism and Matrix Multiply Matrix Multiply Assembly code: 1 vmovapd (%r11),%ymm4 # Load 4 elements of C into %ymm4 2 mov %rbx,%rax # register %rax = %rbx 3 xor %ecx,%ecx # register %ecx = 0 4 vmovapd 0x20(%r11),%ymm3 # Load 4 elements of C into %ymm3 5 vmovapd 0x40(%r11),%ymm2 # Load 4 elements of C into %ymm2 6 vmovapd 0x60(%r11),%ymm1 # Load 4 elements of C into %ymm1 7 vbroadcastsd (%rcx,%r9,1),%ymm0 # Make 4 copies of B element 8 add $0x8,%rcx # register %rcx = %rcx + 8 9 vmulpd (%rax),%ymm0,%ymm5 # Parallel mul %ymm1,4 A elements 10 vaddpd %ymm5,%ymm4,%ymm4 # Parallel add %ymm5, %ymm4 11 vmulpd 0x20(%rax),%ymm0,%ymm5 # Parallel mul %ymm1,4 A elements 12 vaddpd %ymm5,%ymm3,%ymm3 # Parallel add %ymm5, %ymm3 13 vmulpd 0x40(%rax),%ymm0,%ymm5 # Parallel mul %ymm1,4 A elements 14 vmulpd 0x60(%rax),%ymm0,%ymm0 # Parallel mul %ymm1,4 A elements 15 add %r8,%rax # register %rax = %rax + %r8 16 cmp %r10,%rcx # compare %r8 to %rax 17 vaddpd %ymm5,%ymm2,%ymm2 # Parallel add %ymm5, %ymm2 18 vaddpd %ymm0,%ymm1,%ymm1 # Parallel add %ymm0, %ymm1 19 jne 68 <dgemm+0x68> # jump if not %r8 != %rax 20 add $0x1,%esi # register % esi = % esi + 1 21 vmovapd %ymm4,(%r11) # Store %ymm4 into 4 C elements 22 vmovapd %ymm3,0x20(%r11) # Store %ymm3 into 4 C elements 23 vmovapd %ymm2,0x40(%r11) # Store %ymm2 into 4 C elements 24 vmovapd %ymm1,0x60(%r11) # Store %ymm1 into 4 C elements 29
4.14 Fallacies and Pitfalls Fallacies Pipelining is easy (!) The basic idea is easy The devil is in the details e.g., detecting data hazards Pipelining is independent of technology So why haven t we always done pipelining? More transistors make more advanced techniques feasible Pipeline-related ISA design needs to take account of technology trends e.g., predicated instructions Today, concerns about power are leading to less aggressive and more efficient designs. 31
Pitfalls Poor ISA design can make pipelining harder e.g., complex instruction sets (VAX, IA-32) Significant overhead to make pipelining work IA-32 micro-op approach e.g., complex addressing modes Register update side effects, memory indirection e.g., delayed branches Advanced pipelines have long delay slots DEC Alpha and the DEC NVAX Alpha with newer instruction set architecture is twice as fast as NVAX MIPS M/2000 and the DEC VAX 8700 MIPS M/2000 executes more instructions, but the VAX on average executes 2.7 times as many clock cycles, so the MIPS is faster 32
4.14 Concluding Remarks Concluding Remarks ISA influences design of datapath and control Datapath and control influence design of ISA Pipelining improves instruction throughput using parallelism More instructions completed per second Latency for each instruction not reduced Hazards: structural, data, control Multiple issue and dynamic scheduling (ILP) Dependencies limit achievable parallelism Complexity leads to the power wall 33