Open-Domain Question Answering Dataset WikiQA Overview

This content discusses the WikiQA dataset, a challenge dataset for open-domain question answering. It covers topics such as question answering with knowledge base, answer sentence selection, QA sentence dataset, issues with QA sentence dataset, and WikiQA dataset details. Various aspects of open-domain question answering and dataset challenges are explored.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
WikiQA: A Challenge Dataset for Open-Domain Question Answering Yi Yang*, Scott Wen Scott Wen- -tau tau Yih Yih# #, , Christopher Meek# *Georgia Institute of Technology, Atlanta #Microsoft Research, Redmond
Open-domain Question Answering What are the names of Obama s daughters? Question Answering with Knowledge Base Large-scale knowledge bases (e.g., Freebase) KB-specific semantic parsing (e.g., [Berant+ 13], [Yih+ 15]) Question Answering with Free Text High-quality, reliable text (e.g., Wikipedia, news articles)
Answer Sentence Selection Given a factoid question, find the sentence in the candidate set that Contains the answer Can sufficiently support the answer Q: Who won the best actor Oscar in 1973? S1: Jack Lemmon was awarded the Best Actor Oscar for Save the Tiger (1973). S2: Academy award winner Kevin Spacey said that Jack Lemmon is remembered as always making time for others.
QASent Dataset [Wang+ 07] Based on the TREC-QA data Standard benchmark for answer sentence selection Dependency tree matching (e.g., [Wang+ 07], [Wang+ 10], [Yao+ 13]) Tree kernel SVMs (e.g., [Severyn & Moschitti 13]) Latent word alignment with lexical semantic matching (e.g., [Yih+ 13]) Deep neural network models (e.g., [Yu+ 14], [Wang+ 15])
Issues with QASent Dataset Question distribution Contain questions from human editors Candidate selection bias Output from the systems participating in TREC-QA Sentences need to share non-stopwords from the questions Q: How did Seminole war end? A: Ultimately, the Spanish Crown ceded the colony to United States rule. Excluding questions that have no correct answers
WikiQA Dataset Question distribution Questions sampled from Bing query logs Candidate selection Candidate sentences are from summary paragraphs of Wikipedia pages Including Including questions that have no correct answers Answer Triggering: detecting whether a correct answer exists in candidate sentences
Outline Introduction WikiQA Dataset Data construction and annotation Data statistics Experiments Conclusion
Data Construction Questions Questions sampled from Bing query logs Search queries starting with a WH-word Filter out entity queries (e.g., how I met your mother ) Select queries issued by at least 5 users and have clicks to Wikipedia
Data Construction Sentences Candidate sentences Use all sentences from the summary paragraph of the Wikipedia page Who wrote second Corinthians?
Sentence Annotation by Crowdsourcing Step 1: Does the short paragraph answer the question? Question: Who wrote second Corinthians? Second Epistle to the Corinthians The Second Epistle to the Corinthians, often referred to as Second Corinthians (and written as 2 Corinthians), is the eighth book of the New Testament of the Bible. Paul the Apostle and Timothy our brother wrote this epistle to the church of God which is at Corinth, with all the saints which are in all Achaia .
Sentence Annotation by Crowdsourcing Step 2: Check all the sentences that can answer the question in isolation isolation (assuming coreferences and pronouns have been resolved correctly) in Question: Who wrote second Corinthians? Second Epistle to the Corinthians The Second Epistle to the Corinthians, often referred to as Second Corinthians (and written as 2 Corinthians), is the eighth book of the New Testament of the Bible. Paul the Apostle and Timothy our brother wrote this epistle to the church of God which is at Corinth, with all the saints which are in all Achaia .
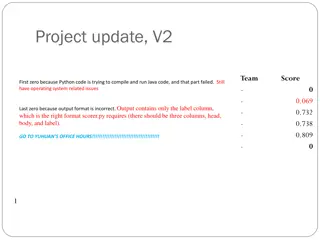
Data Statistics: # Questions 3,047 3,500 3,000 13.4x 2,500 2,000 1,500 1,000 227 500 - # of questions QASent WikiQA
Data Statistics: # Questions & Sentences 35,000 29,258 30,000 3.5x 25,000 20,000 15,000 8,478 10,000 3,047 227 5,000 - # of questions # of sentences QASent WikiQA
Question Classes (UIUC Question Taxonomy) QASent WikiQA Abbr. 1% Desc. 7% Abbr. 1% Entity 14% Entity 16% Desc. 35% Human 29% Location 12% Locatio n 16% Numeric 22% Numeric 31% Human 16% Category Description/Definition has the most questions
Outline Introduction WikiQA Dataset Experiments Baseline systems Evaluation on answer sentence selection Evaluation metric & results on answer triggering Conclusion
Baseline Systems Word matching count (Wd-Cnt) # non-stopwords in Q that also occur in S Latent word alignment (Wd-Algn) [Yih+ ACL-13] ?: What is the fastest car in the world? ? ?,? = ?? ( ) ? ?: The Jaguar XJ220 is the dearest, fastest and most sought after car on the planet. Convolutional NN (CNN) [Yu+ DLWorkshop-14] Convolutional NN & Wd-Cnt (CNN-Cnt)
Evaluation on Answer Sentence Selection 0.9 0.7633 0.7617 0.8 Mean Reciprocal Rank (MRR) 0.6662 0.7 0.623 0.6 0.5 0.4 0.3 0.2 0.1 0 QASent Wd-Cnt Wd-Algn CNN CNN-Cnt
Evaluation on Answer Sentence Selection 0.9 0.7633 0.7617 0.8 Mean Reciprocal Rank (MRR) 0.6662 0.6652 0.7 0.6281 0.623 0.6086 0.6 0.4924 0.5 0.4 0.3 0.2 0.1 0 QASent WikiQA* Wd-Cnt Wd-Algn CNN CNN-Cnt * 1,242 (40.8%) questions that have correct answer sentences in the candidate set
Answer Triggering Given a question and a candidate answer sentence set Detect whether there exist correct answers in the sentences Return a correct answer if there exists one Evaluation metric Question-level precision, recall and F1 score Data All questions in WikiQA are included in this task
Evaluation on Answer Triggering 33 32.5 Question-level F1 score 32 31.5 31 30.61 30.5 30 29.5 29 28.5 28 CNN-Cnt +Q-Length +S-Length +Q-Class +All
Evaluation on Answer Triggering 33 32.5 32.17 Question-level F1 score 32 31.5 31 30.61 30.5 30 29.5 29 28.5 28 CNN-Cnt +Q-Length +S-Length +Q-Class +All
Evaluation on Answer Triggering 33 32.5 32.17 Question-level F1 score 32 31.64 31.5 30.92 31 30.61 30.34 30.5 30 29.5 29 28.5 28 CNN-Cnt +Q-Length +S-Length +Q-Class +All
Conclusion (1/2) WikiQA: A new dataset for open-domain QA Question distribution: questions sampled from Bing query logs Candidate selection: sentences from Wikipedia summary paragraphs Enable Answer Triggering by including questions w/o answers Experiments Different model behaviors on WikiQA and QASent datasets Simple word-matching baseline is no longer strong Answer triggering remains a challenging task
Conclusions (2/2) Future Work Investigate advanced semantic matching methods Encoder-decoder semantic matching (e.g., [Sutskever+ NIPS-14]) Structured text semantic matching (e.g., [Hu+ NIPS-14]) Improve the performance of answer triggering Data & Evaluation Script: http://aka.ms/WikiQA Includes answer phrases labeled by authors













")








")
")