Enhancing Multi-Node Systems with Coherent DRAM Caches



C
A
N
D
Y
:
E
N
A
B
L
I
N
G
C
O
H
E
R
E
N
T
D
R
A
M
C
A
C
H
E
S
F
O
R
M
U
L
T
I
-
N
O
D
E
S
Y
S
T
E
M
S
Chiachen Chou, Georgia Tech
Aamer Jaleel, NVIDIA
Moinuddin K. Qureshi, Georgia Tech


MICRO 2016
Taipei, Taiwan
Oct 18, 2016


3
D
-
D
R
A
M
H
E
L
P
S
M
I
T
I
G
A
T
E
B
A
N
D
W
I
D
T
H
W
A
L
L
3D-DRAM: High Bandwidth Memory (HBM)
courtesy: Micron, AMD, Intel, NVIDIA
2
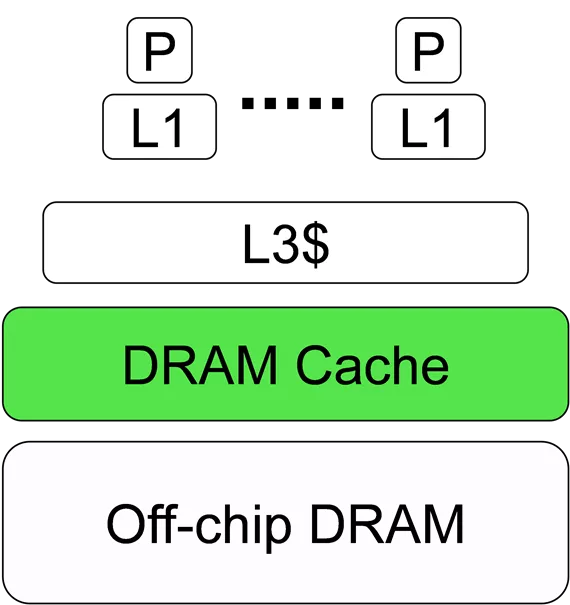

Compared to DDR, 3D DRAM as a cache (DRAM
Cache) transparently provides 4-8X bandwidth



D
R
A
M
C
A
C
H
E
S
F
O
R
M
U
L
T
I
-
N
O
D
E
S
Y
S
T
E
M
S
3
W
e
s
t
u
d
y
D
R
A
M
c
a
c
h
e
s
f
o
r
M
u
l
t
i
-
N
o
d
e
s
y
s
t
e
m
s
Prior studies focus on single-node systems
M
E
M
O
R
Y
-
S
I
D
E
C
A
C
H
E
(
M
S
C
)
4
P
P
P
P
P
P
P
P
DRAM$
DRAM$
Node 0
Node 1
Implicitly coherent, easy to implement
Memory-Side Cache is implicitly
coherent and simple to implement
L3
L3
long-latency
interconnect
local
local
S
H
O
R
T
C
O
M
I
N
G
S
O
F
M
E
M
O
R
Y
-
S
I
D
E
C
A
C
H
E
5
P
P
P
P
P
P
P
P
DRAM$
DRAM$
Node 0
Node 1
Implicitly coherent, easy to implement
Cache only local data, long latency of remote data
A L3 cache miss of remote data incurs
a long latency in Memory-Side Cache
L3
L3
long-latency
interconnect
C
O
H
E
R
E
N
T
D
R
A
M
C
A
C
H
E
S
(
C
D
C
)
6
P
P
P
P
P
P
P
P
DRAM$
DRAM$
Node 0
Node 1
Cache local/remote data, save remote miss latency
Need coherence support
Coherent DRAM Cache saves the L3 miss latency
of remote data but needs coherence support
L3
L3
P
O
T
E
N
T
I
A
L
P
E
R
F
O
R
M
A
N
C
E
I
M
P
R
O
V
E
M
E
N
T
7
AVG: 1.3X
4-node system, each node has 1GB DRAM$
Ideal-CDC outperforms Memory-Side Cache by 30%
A
G
E
N
D
A
•
The Need for Coherent DRAM Cache
•
Challenge 1: A Large Coherence Directory
•
Challenge 2: A Slow Request-For-Data Operation
•
Summary
8
D
I
R
E
C
T
O
R
Y
-
B
A
S
E
D
C
O
H
E
R
E
N
C
E
P
R
O
T
O
C
O
L
9
P
P
P
P
P
P
P
P
LLC
Node 0
Node 1
LLC
Coherence Directory (CDir): Sparse Directory*, tracking
cached data in the system
On a cache miss, the home node
accesses the CDir information
Coherence
Directory
Coherence
Directory
*Standalone inclusive directory with recalls
Memory
Memory
CDir
CDir
L
A
R
G
E
C
O
H
E
R
E
N
C
E
D
I
R
E
C
T
O
R
Y
10
10
For giga-scale DRAM cache, the 64MB coherence
directory incurs storage and latency overheads
P
L3
P
P
P
P
L3
P
P
P
On-Die CDir
for L3
Coherence
Directory
DRAM$
Coherence directory size must be proportional to cache size
8MB
1MB
1GB
64MB
Memory-Side Cache
Coherent DRAM Cache
Memory
Memory
DRAM$
W
H
E
R
E
T
O
P
L
A
C
E
C
O
H
E
R
E
N
C
E
D
I
R
E
C
T
O
R
Y
?
11
11
P
L3
P
P
P
DRAM$
Options:
1. SRAM-CDir: place the 64MB CDir on die (SRAM)
2. Embedded-CDir: embed the 64MB CDir in 3D-DRAM
CDir 64MB
Embedding CDir avoids the SRAM storage,
but incurs long access latency to CDir
3D-DRAM
L4$
DRAM$
miss
CDir Entry
P
P
P
P
DRAM$
SRAM
L3
SRAM-CDir
Embedded-CDir
P
P
P
P
1MB
3D-DRAM
64MB
CDir
Coherent DRAM Cache
D
R
A
M
-
C
A
C
H
E
C
O
H
E
R
E
N
C
E
B
U
F
F
E
R
(
D
C
B
)
12
12
Caching the recently used CDir entries for future references
in the unused on-die CDir of L3 coherence
DCB mitigates the latency to access embedded CDir
DRAM$
D
E
S
I
G
N
O
F
D
R
A
M
-
C
A
C
H
E
C
O
H
E
R
E
N
C
E
B
U
F
F
E
R
13
13
3D-DRAM
CDir
DCB
SRAM
64B
(16 CDir entries)
miss
One access to CDir in 3D-DRAM returns 16 CDir entries.
The hit rate of DCB is 80% with the co-
optimization of DCB and embedded-CDir
E
F
F
E
C
T
I
V
E
N
E
S
S
O
F
D
C
B
14
14
4-node system, each node has 1GB DRAM$
DRAM-cache Coherence Buffer (DCB): 21%
A
G
E
N
D
A
•
The Need for Coherent DRAM Cache
•
Challenge 1: A Large Coherence Directory
•
Challenge 2: A Slow Request-For-Data Operation
•
Summary
15
15
S
L
O
W
R
E
Q
U
E
S
T
-
F
O
R
-
D
A
T
A
(
R
F
D
)
16
16
In Coherent DRAM Cache, Request-For-
Data incurs a slow 3D-DRAM access
RFD (fwd-getS): read the data from a remote cache
Home Node
MSC:
SRAM$
Read
S
H
A
R
I
N
G
-
A
W
A
R
E
B
Y
P
A
S
S
17
17
Request-For-Data accesses only read-write shared data
Home Node
Read-write shared data bypass DRAM
caches and are stored only in L3 caches
Request-For-Data
P
E
R
F
O
R
M
A
N
C
E
I
M
P
R
O
V
E
M
E
N
T
O
F
C
A
N
D
Y
18
18
DRAM
Ca
che for Multi-
N
o
d
e S
y
stems (CANDY)
AVG: 1.25X
CANDY: 25% improvement (5% within Ideal-CDC)
S
U
M
M
A
R
Y
•
Coherent DRAM Cache faces two key challenges:
–
Large coherence directory
–
Slow Request-For-Data
•
DRAM
Ca
che for Multi-
N
o
d
e S
y
stems (CANDY)
–
DRAM-cache Coherence Buffer with embedded coherence directory
–
Sharing-Aware Bypass
•
CANDY outperforms Memory-Side Cache by 25% (5% within
Ideal Coherent DRAM Cache)
19
19
C
A
N
D
Y
:
E
N
A
B
L
I
N
G
C
O
H
E
R
E
N
T
D
R
A
M
C
A
C
H
E
S
F
O
R
M
U
L
T
I
-
N
O
D
E
S
Y
S
T
E
M
S
MICRO 2016
Taipei, Taiwan
Oct 18, 2016
T
T
H
H
A
A
N
N
K
K
Y
Y
O
O
U
U
Computer Architecture and Emerging Technologies Lab, Georgia Tech
Chiachen Chou, Georgia Tech
Aamer Jaleel, NVIDIA
Moinuddin K. Qureshi, Georgia Tech
21
21
Backup Slides
D
C
B
H
I
T
R
A
T
E
22
22
O
P
E
R
A
T
I
O
N
B
R
E
A
K
D
O
W
N
23
23
I
N
T
E
R
-
N
O
D
E
N
E
T
W
O
R
K
T
R
A
F
F
I
C
R
E
D
U
C
T
I
O
N
24
24
Compare to MSC, CANDY reduces 65% of the traffic
P
E
R
F
O
R
M
A
N
C
E
(
N
U
M
A
-
A
W
A
R
E
S
Y
S
T
E
M
S
)
25
25
S
H
A
R
I
N
G
-
A
W
A
R
E
B
Y
P
A
S
S
(
1
)
26
26
(1) Detecting read-write shared data
(2) Enforcing R/W shared data to bypass caches
Home Node
Sharing-Aware Bypass detects read-write shared
data at run-time based on coherence operations
CDir Entry
S
H
A
R
I
N
G
-
A
W
A
R
E
B
Y
P
A
S
S
(
2
)
27
27
(1) Detecting read-write shared data
(2) Enforcing R/W shared data to bypass caches
•
L4 cache miss and L3 dirty eviction
Home Node
M
L3
DRAM$
Requester
Sharing-Aware Bypass enforces R/W
shared data to be stored only in L3 caches
1
M
E
T
H
O
D
O
L
O
G
Y
28
28
DRAM$
Off-chip DRAM
4-Node
•
Evaluation in Sniper simulator, baseline: Memory-Side Cache
•
13 parallel benchmarks from NAS, SPLASH2, PARSEC, NU-bench
Exploring the integration of Coherent DRAM Caches in multi-node systems to improve memory performance. Discusses the benefits, challenges, and potential performance improvements compared to existing memory-side cache solutions.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
CANDY: ENABLING COHERENT DRAM CACHES FOR MULTI-NODE SYSTEMS MICRO 2016 Taipei, Taiwan Oct 18, 2016 Chiachen Chou, Georgia Tech Aamer Jaleel, NVIDIA Moinuddin K. Qureshi, Georgia Tech
3D-DRAM HELPS MITIGATE BANDWIDTH WALL 3D-DRAM: High Bandwidth Memory (HBM) P L1 P L1 L3$ 3D-DRAM DRAM Cache Off-chip DRAM Compared to DDR, 3D DRAM as a cache (DRAM Cache) transparently provides 4-8X bandwidth NVIDIA PASCAL AMD Zen Intel Xeon Phi courtesy: Micron, AMD, Intel, NVIDIA 2
DRAM CACHES FOR MULTI-NODE SYSTEMS Prior studies focus on single-node systems Node 0 Node 1 P P P P P P P P P P P P L3$ L3$ L3$ DRAM$ DRAM$ long-latency inter-node DRAM$ Off-chip DRAM Off-chip DRAM network Off-chip DRAM We study DRAM caches for Multi-Node systems 3
MEMORY-SIDE CACHE (MSC) Implicitly coherent, easy to implement Node 0 Node 1 P P P P P P P P L3 L3 DRAM$ DRAM$ local local long-latency interconnect Memory-Side Cache is implicitly coherent and simple to implement 4
SHORTCOMINGS OF MEMORY-SIDE CACHE Implicitly coherent, easy to implement Cache only local data, long latency of remote data Node 0 Node 1 P P P P P P P P L3 ~4MB L3 DRAM$ DRAM$ remote ~1GB long-latency interconnect A L3 cache miss of remote data incurs a long latency in Memory-Side Cache 5
COHERENT DRAM CACHES (CDC) Cache local/remote data, save remote miss latency Need coherence support Node 0 Node 1 P P P P P P P P L3 L3 DRAM$ DRAM$ remote Coherent DRAM Cache saves the L3 miss latency of remote data but needs coherence support 6
POTENTIAL PERFORMANCE IMPROVEMENT 4-node system, each node has 1GB DRAM$ MSC Ideal Coherent DRAM Cache 3.0 2.5 AVG: 1.3X 2.0 Speedup Ideal-CDC outperforms Memory-Side Cache by 30% 1.5 1.0 0.5 0.0 water.n fmm facesim fluid radiosity stream mg ocean.c dedup vips barnes AVG kmeans ocean.nc 7
AGENDA The Need for Coherent DRAM Cache Challenge 1: A Large Coherence Directory Challenge 2: A Slow Request-For-Data Operation Summary 8
DIRECTORY-BASED COHERENCE PROTOCOL Coherence Directory (CDir): Sparse Directory*, tracking cached data in the system Node 0 Node 1 P P P P P P P P LLC LLC Coherence Directory Coherence Directory Memory CDir CDir Memory On a cache miss, the home node accesses the CDir information *Standalone inclusive directory with recalls 9
LARGE COHERENCE DIRECTORY Coherence directory size must be proportional to cache size Coherent DRAM Cache Memory-Side Cache P P P P P P P P L3 L3 8MB On-Die CDir for L3 1GB DRAM$ 1MB Coherence Directory Memory DRAM$ 64MB Memory For giga-scale DRAM cache, the 64MB coherence directory incurs storage and latency overheads 10
WHERE TO PLACE COHERENCE DIRECTORY? Options: 1. SRAM-CDir: place the 64MB CDir on die (SRAM) 2. Embedded-CDir: embed the 64MB CDir in 3D-DRAM DRAM$ miss P P P P P P P CDir 64MB P SRAM L3 L3 L3 3D-DRAM L4$ DRAM$ DRAM$ CDir 64MB Embedded-CDir SRAM-CDir CDir Entry Embedding CDir avoids the SRAM storage, but incurs long access latency to CDir 11
DRAM-CACHE COHERENCE BUFFER (DCB) Caching the recently used CDir entries for future references in the unused on-die CDir of L3 coherence Memory-Side Cache Coherent DRAM Cache DRAM$ miss P P P P P P P P DRAM$ L3 On-Die CDir for L3 On-Die CDir for L3 DRAM-cache Coherence Buffer 1MB 1MB Unused Hit Miss CDir 3D-DRAM CDir Entry 64MB DCB mitigates the latency to access embedded CDir 12
DESIGN OF DRAM-CACHE COHERENCE BUFFER One access to CDir in 3D-DRAM returns 16 CDir entries. SRAM insert DCB miss = = = = 3D-DRAM Demand CDir 64B (16 CDir entries) Set S 4-way set-associative S+1 S+2 S+3 The hit rate of DCB is 80% with the co- optimization of DCB and embedded-CDir 13
EFFECTIVENESS OF DCB 4-node system, each node has 1GB DRAM$ Embedded-CDir DRAM-cache Coherence Buffer (DCB) 3.0 2.5 2.0 Speedup DRAM-cache Coherence Buffer (DCB): 21% 1.5 1.0 0.5 0.0 ocean.c water.n fmm facesim fluid radiosity stream dedup mg vips barnes AVG kmeans ocean.nc 14
AGENDA The Need for Coherent DRAM Cache Challenge 1: A Large Coherence Directory Challenge 2: A Slow Request-For-Data Operation Summary 15
SLOW REQUEST-FOR-DATA (RFD) RFD (fwd-getS): read the data from a remote cache cache miss Remote Home Node Coherence Directory DRAM$ L3 Request-For-Data MSC: SRAM$ Read CDC: DRAM$ Read extra latency In Coherent DRAM Cache, Request-For- Data incurs a slow 3D-DRAM access 16
SHARING-AWARE BYPASS Request-For-Data accesses only read-write shared data cache miss Owner Home Node Coherence Directory P P P P M L3 M DRAM$ Request-For-Data Read-write shared data bypass DRAM caches and are stored only in L3 caches 17
PERFORMANCE IMPROVEMENT OF CANDY DRAM Cache for Multi-Node Systems (CANDY) DCB CANDY Ideal-CDC (64MB SRAM+idealized RFD) 3.0 2.5 AVG: 1.25X 2.0 CANDY: 25% improvement (5% within Ideal-CDC) Speedup 1.5 1.0 0.5 0.0 kmeans water.n fmm facesim radiosity stream fluid ocean.c barnes mg dedup vips AVG ocean.nc 18
SUMMARY Coherent DRAM Cache faces two key challenges: Large coherence directory Slow Request-For-Data DRAM Cache for Multi-Node Systems (CANDY) DRAM-cache Coherence Buffer with embedded coherence directory Sharing-Aware Bypass CANDY outperforms Memory-Side Cache by 25% (5% within Ideal Coherent DRAM Cache) 19
THANK YOU CANDY: ENABLING COHERENT DRAM CACHES FOR MULTI-NODE SYSTEMS MICRO 2016 Taipei, Taiwan Oct 18, 2016 Chiachen Chou, Georgia Tech Aamer Jaleel, NVIDIA Moinuddin K. Qureshi, Georgia Tech Computer Architecture and Emerging Technologies Lab, Georgia Tech
DCB HIT RATE DCB? Hit? Rate DCB-Demand DCB-SpatLoc 100 DCB? Hit? Rate? (%) 80 60 40 20 0 radiosity ocean.c barnes facesim ocean.nc vips stream mg dedup kmeans AVG fluid water.n fmm NPB SPLASH2 PARSEC OTHERS 22
OPERATION BREAKDOWN Consequent? Operation? of? L3? Misses? in? CDC RFD INV Mem Hit 100.00 80.00 Percentage 60.00 40.00 20.00 0.00 radiosity ocean.c barnes ocean.nc facesim vips mg stream dedup AVG kmeans fluid water.n fmm NPB SPLASH2 PARSEC OTHERS 23
INTER-NODE NETWORK TRAFFIC REDUCTION CANDY 100.00 Traffic? Reduction? (%) 80.00 60.00 40.00 20.00 0.00 fmm AVG mg dedup ocean.ncont ocean.cont water.nsq kmeans barnes vips fluidanimate facesim radiosity streamcluster NPB SPLASH2 PARSEC OTHERS Compare to MSC, CANDY reduces 65% of the traffic 24
PERFORMANCE (NUMA-AWARE SYSTEMS) Performance? NUMA-Aware SW-Opt 3.00 Speedup?(w.r.t.? MSC) 2.50 2.00 1.50 1.00 0.50 0.00 radiosity streamcluster barnes kmeans facesim water.nsq fluidanimate dedup fmm vips ocean.cont mg AVG ocean.ncont NPB SPLASH2 PARSEC OTHERS 25
SHARING-AWARE BYPASS (1) (1) Detecting read-write shared data (2) Enforcing R/W shared data to bypass caches cache request Home Node Coherence Directory CDir Entry 1 M RWS Memory Read Invalidate Request-For-Data Flush Read-write shared data, set Read-Write Shared (RWS) bit Sharing-Aware Bypass detects read-write shared data at run-time based on coherence operations 26
SHARING-AWARE BYPASS (2) (1) Detecting read-write shared data (2) Enforcing R/W shared data to bypass caches L4 cache miss and L3 dirty eviction BypL4 bit BypL4 bit + Data cache miss Requester 1 Home Node RWS L3 M Dirty Eviction 1 1 M Yes BypL4? BypL4 No Yes BypL4? DRAM$ Data No Sharing-Aware Bypass enforces R/W shared data to be stored only in L3 caches 27
METHODOLOGY P P P P 4-Node DRAM$ Off-chip DRAM DRAM Cache 1GB DDR3.2GHz, 64-bit 8 channels, 16 banks/ch DRAM Memory 16GB DDR1.6GHz, 64-bit 2 channels 8 banks/ch 4-Node, each node: 4 cores 3.2 GHz 2-wide OOO 4MB 16-way L3 shared cache Capacity Bus Channel Evaluation in Sniper simulator, baseline: Memory-Side Cache 13 parallel benchmarks from NAS, SPLASH2, PARSEC, NU-bench 28



")

")





")



")








")
")
")