
Introduction to Spatial Data Mining: Discovering Patterns in Large Datasets
Spatial data mining involves uncovering valuable patterns from extensive spatial datasets, offering insights into historical events, environmental phenomena, and predictive analytics. Examples range from analyzing disease outbreaks to predicting habitat suitability for endangered species. The applic
2 views • 20 slides

Subsurface Structures of Pit Craters Through Seismic Reflection
Discover the technique of seismic reflection imaging to unveil the subsurface structures of pit craters on Earth and Mars. Follow the analysis of seismic data to map pit craters and their connections to geological features like dykes and fault jogs, shedding light on the formation processes of these
1 views • 11 slides

Biological Datasets and Omics Approaches in Disease Research
Explore the world of biological datasets, lipidomics, genomics, epigenomics, proteomics, and the application of omics in studying biological mechanisms, predicting outcomes, and identifying important variables. Dive into DNA, gene expression, methylation, and genetic datasets to unravel the complexi
1 views • 34 slides

VSAM Logical Record Access Methods
VSAM utilizes three primary methods to find logical records - Relative Byte Address, Relative Record Number, and Key field. Relative Byte Address assigns a unique address to each record based on sequential ordering. Relative Record Number is used in RRDS datasets to access records by a numbered sequ
3 views • 35 slides

Geophysics Field Testing Workshop: Methods and Interpretation
This workshop on geophysics field testing covers a range of methods such as downhole and surface testing, spectral analysis, seismic refraction, and more. Geophysical investigations help assess subsurface properties efficiently and non-invasively, offering valuable insights for site exploration and
1 views • 16 slides

Skin Cancer Primary Tumour Staging Changes: RCPath Updates
Explore the latest primary tumour staging changes for skin cancer, including updates from RCPath, datasets for BCC and SCC, changes in TNM classification for skin carcinomas, and upcoming new college datasets. Dive into the evolving landscape of skin cancer staging since January 2018 with detailed s
0 views • 11 slides

Proteomics Data Analysis Workflows in Perseus
This content provides a detailed walkthrough of utilizing Perseus interface/functions for analyzing label-free and SILAC datasets in the field of proteomics. It covers loading, filtering, visualization, log transformation, rearrangement of columns, and advanced analysis techniques such as scatter pl
2 views • 4 slides

Coding Simulation Studies in Stata: A Practical Approach
Understanding simulation studies and their importance in evaluating statistical methods, this presentation delves into the precise coding techniques required in Stata to generate simulated datasets, produce estimates, and analyze performance metrics. With a focus on consistent terminology, data-gene
6 views • 18 slides

Project EDDIE: Enhancing Student Quantitative Reasoning with Large Datasets
Project EDDIE focuses on improving student quantitative reasoning through inquiry-driven exploration of complex datasets. The project aims to support instructors in guiding students to enhance their understanding of scientific concepts and quantitative skills. With a commitment to community and lear
0 views • 6 slides

Advancements in Knowledge Graph Question Answering for Materials Science
Investigating natural language interfaces for querying structured MOF data stored in a knowledge graph, this project focuses on developing strategies using NLP to translate NL questions to KG queries. The MOF-KG integrates datasets, enabling query, computation, and reasoning for deriving new knowled
1 views • 13 slides

Vertical Flow Constructed Wetland Technical Specifications and Requirements
The technical specifications for a vertical flow constructed wetland include requirements for subsurface compacting, lining materials such as clay layers and plastic liners, perforation of pipes, watertight installation of underdrain pipes, central drainage channel design, and filter media compositi
0 views • 11 slides

RCRL Prospective Research Directions in Carbonate Reservoir Characterization
The RCRL group at the University of Texas at Austin specializes in research on carbonate reservoirs at various scales, from nanopores to basin architecture. They focus on developing predictive relationships and tools for reservoir characterization based on subsurface datasets and outcrop analogs. Th
1 views • 12 slides

Remote Control of ATV Team with myRIO and Shared Variables
Developing a remote control system for an ATV team using myRIO to manage functions like steering, throttle, choke, brakes, and start/stop via WiFi communication. Components like Haydon Motor Controller, Sabertooth 2x25 for steering, relays for brakes/start/stop, and shared variables enable efficient
0 views • 13 slides

Sources, Tools, and Datasets in Text Mining
Discover a plethora of sources, tools, and datasets in text mining through resources shared by Bettina Berendt and references from lectures and publications. Uncover DH-specific tools and powerful NLP tools like Ling Pipe, OpenNLP, Stanford Parser, and NLTK Toolkit for text analysis and processing.
0 views • 17 slides

Mastering Data Analysis with RCommander: A Step-by-Step Guide
Dive into the world of data analysis using RCommander with this comprehensive guide. Learn how to import, clean, and analyze data efficiently, ensuring your datasets are well-prepared for insightful insights. Follow simple steps to navigate RCommander, import Excel files, save datasets, and review v
0 views • 17 slides

Stata-Python Rosetta Stone: Side-by-side Code Examples v1.0
A comprehensive guide providing side-by-side code examples in Stata, Python, and R, facilitating easy translation between the languages. It covers setting up Python for Stata, handling dataframes, storing datasets, working with log files, merging datasets, describing and summarizing data, and more.
2 views • 21 slides

Strategies for Collective Qualitative Secondary Analysis Using Combined Datasets
Collective qualitative secondary analysis involves reusing data through a collaborative lens, embracing multiple viewpoints to gain deeper insights. The approach emphasizes the constructed nature of research data and allows for diverse interpretations and engagements. This article discusses the proc
1 views • 15 slides

Tracing Verbal Aggression and Facework Strategies Over Time
Dawn Archer and Bethan Malory explore the tracing of verbal aggression and other facework strategies over time using themes from the Historical Thesaurus of English. They utilize automated content analysis tools to analyze datasets from various historical periods and propose solutions for prioritizi
0 views • 41 slides

Dynamic Data Management Systems in Agile Views
Large, dynamic data user and enterprise-generated data are increasingly popular, leading to the need for better data management systems. Today's approaches involve handling evolving datasets, algorithmic trading, log analysis, and more. The DBToaster project focuses on lightweight systems for managi
0 views • 37 slides

Enhancing Spatial Data Analysis in QGIS
Explore the integration of relational databases with QGIS to facilitate efficient spatial data analysis. Discover the importance of recognizing spatial relationships within data sets and the solutions to enhance QGIS for relational datasets. Overcome challenges and delve into the intersection and su
0 views • 25 slides

Best Practices for Dataset Handling in Machine Learning Projects
Proper dataset handling is crucial in machine learning projects. Use publicly available datasets with train/dev/test splits or create your own. Be cautious of overfitting by utilizing independent validation and test sets. Avoid touching the test set until final evaluation to prevent overfitting. Mai
0 views • 13 slides

Ventura County ISDS Construction Examples Slideshow
This slideshow showcases different construction stages of Individual Sewage Disposal Systems (ISDS) in Ventura County, providing an overview of the types of systems allowed and general construction techniques employed. From the installation of pressurized distribution beds to completed mounds with l
0 views • 15 slides

VIIRS Land Surface Temperature (LST) Calibration Approach and Data Analysis
The VIIRS Land Surface Temperature (LST) Provisional Status project, led by Dr. Yunyue Yu, focuses on improving the LST EDR through algorithm coefficient updates and calibrations. The calibration process involves regression steps and comparisons with reference datasets like MODIS Aqua LST. Various c
1 views • 29 slides

afni_proc.py: A Powerful Tool for AFNI Data Analysis
AFNI_proc.py is a Python program that provides a flexible and compact way to process and analyze datasets in AFNI. It takes input options to describe processing steps, producing a Unix script file that runs AFNI programs for data analysis. The script not only performs data analysis but also saves di
0 views • 37 slides

International Education Data Analysis Course Overview
An introductory course designed for researchers familiar with basic statistics but new to using international education datasets such as PISA and TALIS. The course includes lectures, practical activities, and computer workshops covering survey design, cross-national comparisons, and data analysis. P
0 views • 53 slides

UCR Time Series Classification Archive Overview
The UCR Time Series Classification Archive, funded by NSF IIS-1161997 II and NSF IIS-1510741, provides valuable resources for researchers interested in time series data analysis. The archive contains datasets in TRAIN and TEST partitions, with data instances stored in ASCII format. Researchers can u
0 views • 14 slides
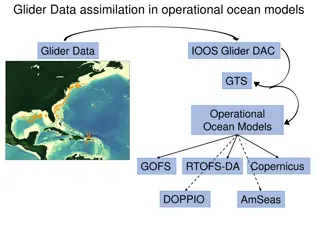
Operational Ocean Modeling and Forecasting Systems
This content provides an overview of various operational ocean modeling and forecasting systems, including data assimilation processes, glider data, surface and subsurface data sources, forecasting models for hurricanes, and NOAA's hurricane forecasting models. It covers a range of technologies and
1 views • 16 slides

Overview of Major Brain Research Datasets and Consortia
This detailed summary provides information on significant brain-related project datasets and consortia, including PsychENCODE, BrainSpan, CommonMind Consortium, AMP-AD Knowledge, and more. Each dataset or consortium focuses on specific areas such as genomics, neuropsychiatric diseases, neurodegenera
0 views • 18 slides

National Maternity and Perinatal Audit (NMPA) Data Flow Overview
The National Maternity and Perinatal Audit (NMPA) collects data extracts from various datasets in England, Wales, and Scotland to improve maternity and perinatal services. The datasets include mortality registers, birth notification datasets, maternity services data sets, and more. The collected dat
0 views • 5 slides

Workshop on Standardized Methodologies for Food Composition Databases
The workshop held in Tunisia aimed to improve national food composition datasets, focusing on countries in the Eastern Mediterranean Region and Africa. Key objectives included identifying existing data status, providing training on data compilation, and generating harmonized datasets for EuroFIR. Th
0 views • 15 slides

Guide to Setting Up Neural Network Models with CIFAR-10 and RBM Datasets
Learn how to install Apache Singa, prepare data using SINGA recognizable records, and convert programs for DataShard for efficient handling of CIFAR-10 and MNIST datasets. Explore examples on creating shards, generating records, and implementing CNN layers for effective deep learning.
0 views • 23 slides

Investigating Allelic Bias in Personal Genomes
This study delves into allelic bias in personal genomes, examining the influence of various factors such as sequencing datasets, removal of reads with allelic bias, and the impact on allele-specific single nucleotide variants (AS SNVs). The revised AlleleDB pipeline proposed includes steps for const
0 views • 6 slides

National Maternity and Perinatal Audit (NMPA) Data Flow Summary
The National Maternity and Perinatal Audit (NMPA) in England, Wales, and Scotland receives various datasets for maternal and perinatal care, including mortality data, birth notifications, maternity services data, and more. The datasets are pseudonymised and used for linkage, validation, case ascerta
0 views • 5 slides

Recommendations for Creating Identifiers in Data Catalogues
National data catalogues have specific requirements for identifiers, such as using HTTP URIs for open data datasets. While most INSPIRE datasets only have UUID identifiers, adhering to the DCAT-AP standard recommends using HTTP URIs. Recommendations for creating identifiers in the geodata sector are
0 views • 5 slides

CRDCN: Accessing Unique Data for Research
The Canadian Research Data Centre Network (CRDCN) offers researchers access to Statistics Canada microdata and a variety of other datasets through Research Data Centres (RDCs) across 33 campuses. Data accessed via the RDC is secure and protected, allowing for in-depth analysis while ensuring confide
0 views • 7 slides

Challenges in High-Value Datasets Creation and Transformation Processes
The creation and transformation process of high-value datasets, such as POP-WILDFIRE, face challenges like schema harmonisation, schema creation, and data transformation. Issues include identifying pan-European datasets, data pre-processing, aligning with INSPIRE directive, and adapting existing met
0 views • 6 slides

Fast Bayesian Optimization for Machine Learning Hyperparameters on Large Datasets
Fast Bayesian Optimization optimizes hyperparameters for machine learning on large datasets efficiently. It involves black-box optimization using Gaussian Processes and acquisition functions. Regular Bayesian Optimization faces challenges with large datasets, but FABOLAS introduces an innovative app
0 views • 12 slides

Enhancing COVID-19 Data Integration and Comparison with GeoCOVID Watch
This initiative, supported by the European Commission, focuses on addressing the challenges of data interoperability in COVID-19-related datasets. By leveraging geospatial data and cutting-edge technologies, the project aims to improve the understanding of the pandemic's impacts through standardized
0 views • 13 slides

Scientific Exploitation Report on Climate Modelling User Group (CMUG) Engagement
The scientific exploitation report highlights the engagement activities and outcomes of the Climate Modelling User Group (CMUG) through various platforms like the project website, data forum, CCI datasets, and more. It outlines future steps to gather feedback, compile reports, and enhance the use of
0 views • 4 slides

How Video Transcription Services Improve AI Training Through Annotated Datasets
Video transcription services convert unstructured video data into structured text, providing annotated datasets that significantly improve AI training. By adding elements like time stamps, speaker labels, and context, these services support various A
0 views • 5 slides