
How To Create BI Reports That Actually Get Read_ A Step-by-Step Guide
Discover the art of creating BI reports that command attention and spark decisive action with our comprehensive step-by-step guide. Delve into strategies for understanding your audience, setting clear objectives, selecting the right data, and designing reports for clarity and impact.
1 views • 5 slides

Engaging Sentence Starters and Stories from 2016-2017
Explore a collection of intriguing sentence starters and short stories from 2016-2017, featuring everyday situations that spark curiosity and imagination. Follow along as these narratives unfold, each presenting a unique scenario that captivates the reader's attention through vivid descriptions and
0 views • 218 slides

Imperatives for Restoring Nigeria on the Path of Sustainable Economic Growth and Development by Professor Prince Michael Sunday Ikupolati
Professor Ikupolati presents key imperatives for restoring Nigeria's economic growth and development, addressing the country's challenges and opportunities. Emphasizing the need for industrialization, the lecture aims to spark discussion on propelling Nigeria towards becoming a first-world country.
0 views • 73 slides

Unraveling the Humor: Exploring the Depths of Comedy
Comedy, a genre designed to elicit laughter and mirth, transcends cultural boundaries with its diverse forms like romantic comedy, horror comedy, and political comedy. What makes us laugh varies across individuals and contexts, often rooted in incongruity theory where unexpected twists spark joy. Co
0 views • 23 slides

Exploring PEXchange: A Journey in Philanthropy Infrastructure
Embark on a collective adventure with PEXchange, a community promoting explorer identities in philanthropy infrastructure. Discover how aligning on universal values can spark transformative change and explore the PEX origin story from seed to ecosystem flourishing. Join the movement towards equity,
4 views • 29 slides

Evolution of 5G Networks: 3GPP's Vision for Advanced Connectivity
5G Advanced, driven by 3GPP Release 18 and beyond, represents a significant milestone in mobile communication, blending digital and physical realms seamlessly. This transformative era integrates XR, Integrated Sensing, Communication, AI, and ML to redefine connectivity and spark innovation. The tran
5 views • 12 slides

Get Ready to Pass the Databricks Developer for Apache Spark - Scala Exam
Begin your preparation journey here: \/\/bit.ly\/3W0ZIga. Discover comprehensive details on the Data Engineer Associate certification exam, including tutorials, practice tests, books, study materials, exam questions, and the syllabus. Solidify your understanding of Data Engineering and prepare to su
4 views • 14 slides

Optimizing Memory Usage on GPUs Through a Marie Kondo Approach
Learn how to apply Marie Kondo's "spark joy" rule to optimize memory on GPUs by evaluating the necessity of data reads, reducing memory usage, and encoding images efficiently. Explore challenges and examples in memory optimization on the GPU for better performance.
6 views • 41 slides

Teaching Observation Process and Best Practices
Explore the teaching observation process with a focus on fostering faculty success and improving teaching practices. Learn about pre-observation meetings, separating observation from evaluation, and utilizing observations to spark dialogue about effective teaching. Access resources such as the Teach
7 views • 20 slides

AI in Healthcare- The Spark of Rebellion
Discover how AI is reshaping patient care, diagnosing illnesses faster, and bridging critical healthcare gaps.
5 views • 6 slides

Stunning Slides Showcasing Creative Visuals
Dive into a captivating collection of visually striking slides that will spark your creativity and inspire your next design project. Each image offers a unique perspective and a burst of color, setting the stage for imaginative exploration. Let these beautiful visuals ignite your imagination and ele
0 views • 14 slides

Understanding Spark Containers and Layouts in Flex 4
Learn about Spark Containers in Flex 4, their types, differences from MX Containers, assignable layouts, what containers can hold, and more. Explore how components are sized and positioned using layout objects in Spark.
3 views • 30 slides

Understanding Apache Spark: Fast, Interactive, Cluster Computing
Apache Spark, developed by Matei Zaharia and team at UC Berkeley, aims to enhance cluster computing by supporting iterative algorithms, interactive data mining, and programmability through integration with Scala. The motivation behind Spark's Resilient Distributed Datasets (RDDs) is to efficiently r
0 views • 41 slides

Introduction to Spark Streaming for Large-Scale Stream Processing
Spark Streaming, developed at UC Berkeley, extends the capabilities of Apache Spark for large-scale, near-real-time stream processing. With the ability to scale to hundreds of nodes and achieve low latencies, Spark Streaming offers efficient and fault-tolerant stateful stream processing through a si
0 views • 30 slides

Spark: Revolutionizing Big Data Processing
Learn about Apache Spark and RDDs in this lecture by Kishore Pusukuri. Explore the motivation behind Spark, its basics, programming, history of Hadoop and Spark, integration with different cluster managers, and the Spark ecosystem. Discover the key ideas behind Spark's design focused on Resilient Di
0 views • 59 slides

Understanding the Ignition System in Internal Combustion Engines
The ignition system in spark ignition engines initiates combustion through electric discharge across the spark plug electrodes. It ensures proper ignition timing for efficient engine operation at various speeds and loads. Modern ignition systems include battery, magneto, and electronic ignition type
0 views • 21 slides

4-H Spark Achievement Program Overview
The 4-H Spark Achievement Program empowers youth through meaningful partnerships, goal setting, and inspiring change. Members can earn different levels by completing various activities and can participate in leadership roles to enhance their skills. The program encourages community service and self-
0 views • 24 slides

Muriel Spark: A Literary Journey Through Time
Explore the life and works of acclaimed author Muriel Spark, from her Edinburgh upbringing to her prolific writing career. Delve into her novels, themes of duality, and narrative techniques that challenge traditional realism, all set against the backdrop of post-war Britain.
0 views • 13 slides

Understanding RICE MACT and its Impact on Air Quality
The RICE MACT (Maximum Achievable Control Technology) regulation aims to reduce emissions of Hazardous Air Pollutants (HAPs) from reciprocating internal combustion engines. It applies to major industrial sources emitting significant amounts of HAPs and outlines emission requirements for different ty
0 views • 26 slides

Introduction to Distributed Computing at Stanford University
A meeting at Stanford University's Gates building tonight for those interested in CS341 in the Spring. The session will cover the concept of viewing computation as a recursion on a graph, techniques like Pregel, Giraph, GraphX, and GraphLab for distributed computing, and challenges in data movement
0 views • 18 slides

Spark & MongoDB Integration for LSST Workshop
Explore the use of Spark and MongoDB for processing workflows in the LSST workshop, focusing on parallelism, distribution, intermediate data handling, data management, and distribution methods. Learn about converting data formats, utilizing GeoSpark for 2D indexing, and comparing features with QServ
0 views • 22 slides

Introduction to Apache Spark: Simplifying Big Data Analytics
Explore the advantages of Apache Spark over traditional systems like MapReduce for big data analytics. Learn about Resilient Distributed Datasets (RDDs), fault tolerance, and efficient data processing on commodity clusters through coarse-grained transformations. Discover how Spark simplifies batch p
0 views • 17 slides

Introduction to Spark: Lightning-Fast Cluster Computing
Spark is a parallel computing system developed at UC Berkeley that aims to provide lightning-fast cluster computing capabilities. It offers a high-level API in Scala and supports in-memory execution, making it efficient for data analytics tasks. With a focus on scalability and ease of deployment, Sp
0 views • 17 slides

Evolution of Database Systems: A Spark SQL Perspective
Explore the evolution of database systems, specifically focusing on Spark SQL, NoSQL, and column stores for OLAP. Learn about the history of parallel DB systems, common complaints, the story of NoSQL, and the advantages of column stores for data aggregation and compression in OLAP scenarios.
0 views • 25 slides

Introduction to Map-Reduce and Spark in Parallel Programming
Explore the concepts of Map-Reduce and Apache Spark for parallel programming. Understand how to transform and aggregate data using functions, and work with Resilient Distributed Datasets (RDDs) in Spark. Learn how to efficiently process data and perform calculations like estimating Pi using Spark's
0 views • 11 slides

Analyzing Break-In Attempts Across Multiple Servers using Apache Spark
Exploring cyber attacks on West Chester University's servers by analyzing security logs from five online servers using Apache Spark for large-scale data analysis. Uncovering attack types, frequency patterns, and sources to enhance security measures. Discover insights on break-in attempts and potenti
0 views • 19 slides

Efficient Spark ETL on Hadoop: SETL Approach
An overview of how SETL offers an efficient approach to Spark ETL on Hadoop, focusing on reducing memory footprint, file size management, and utilizing low-level file-format APIs. With significant performance improvements, including reducing task hours by 83% and file count by 87%, SETL streamlines
0 views • 17 slides

Introduction to Spark in The Hadoop Stack
Introduction to Spark, a high-performance in-memory data analysis system layered on top of Hadoop to overcome the limitations of the Map-Reduce paradigm. It discusses the importance of Spark in addressing the expressive limitations of Hadoop's Map-Reduce, enabling algorithms that are not easily expr
0 views • 16 slides

Introduction to Interactive Data Analytics with Spark on Tachyon
Explore the collaboration between Baidu and Tachyon Nexus in advancing interactive data analytics with Spark on Tachyon. Learn about the team, Tachyon's history, features, and why it's a fast-growing open-source project. Discover how Tachyon enables efficient memory-centric distributed storage and i
0 views • 44 slides

Introduction to Spark: Lightning-fast Cluster Computing
Apache Spark is a fast and general-purpose cluster computing system that provides high-level APIs in Java, Scala, and Python. It supports a rich set of higher-level tools like Spark SQL for structured data processing and MLlib for machine learning. Spark was developed at UC Berkeley AMPLab in 2009 a
0 views • 100 slides

Understanding Oregon's Quality Rating and Improvement System (QRIS) Training Overview
This training provides an in-depth look at Oregon's Quality Rating and Improvement System (QRIS), covering topics such as the Quality Improvement Plan, participation in Spark, program supports and incentives, portfolio submission, Spark partners, and more. Gain valuable knowledge and tools to enhanc
0 views • 45 slides

Understanding Apache Spark: A Comprehensive Overview
Apache Spark is a powerful open-source cluster computing framework known for its in-memory analytics capabilities, contrasting Hadoop's disk-based paradigm. Spark applications run independently on clusters, coordinated by SparkContext. Resilient Distributed Datasets (RDDs) form the core of Spark's d
0 views • 16 slides

Distributed Volumetric Data Analytics Toolkit on Apache Spark
This paper discusses the challenges, methodology, experiments, and conclusions of implementing a distributed volumetric data analytics toolkit on Apache Spark to address the performance of large distributed multi-dimensional arrays on big data analytics platforms. The toolkit aims to handle the expo
0 views • 33 slides

Comprehensive Guide to Setting Up Apache Spark for Data Processing
Learn how to install and configure Apache Spark for data processing with single-node and multiple-worker setups, using both manual and docker approaches. Includes steps for installing required tools like Maven, JDK, Scala, Python, and Hadoop, along with testing the Wordcount program in both Scala an
0 views • 53 slides

Overview of Spark SQL: A Revolutionary Approach to Relational Data Processing
Spark SQL revolutionized relational data processing by tightly integrating relational and procedural paradigms through its declarative DataFrame API. It introduced the Catalyst optimizer, making it easier to add data sources and optimization rules. Previous attempts with MapReduce, Pig, Hive, and Dr
0 views • 29 slides
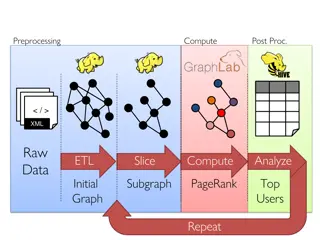
Data Processing and Analysis for Graph-Based Algorithms
This content delves into the preprocessing, computing, post-processing, and analysis of raw XML data for graph-based algorithms. It covers topics such as data ETL, graph analytics, PageRank computation, and identifying top users. Various tools and frameworks like GraphX, Spark, Giraph, and GraphLab
0 views • 8 slides

Overview of Delta Lake, Apache Spark, and Databricks Pricing
Delta Lake is an open-source storage layer that enables ACID transactions in big data workloads. Apache Spark is a unified analytics engine supporting various libraries for large-scale data processing. Databricks offers a pricing model based on DBUs, providing support for AWS and Microsoft Azure. Ex
0 views • 16 slides

Connecting Spark to Files Containing Data - Overview of RDD Model Expansion
Today's lecture explores the evolution of Spark from its inception at Berkeley to its widespread adoption globally. The focus is on the RDD model, which has transitioned into a full programming language resembling SQL, Python, or Scala. Examples of RDD programming at Cornell and in industry settings
0 views • 53 slides

Understanding Topological Sorting in Spark GraphX
Explore the essential concepts of Topological Sorting in Spark GraphX, including necessary background knowledge, stand-alone versus distributed implementations, and practical examples. Delve into Spark GraphX's capabilities, such as RDD manipulation, high-level tools, and graph parallel computation.
0 views • 56 slides

Making Sense of Spark Performance at UC Berkeley
PhD student at UC Berkeley presents an overview of Spark performance, discussing measurement techniques, performance bottlenecks, and in-depth analysis of workloads using a performance analysis tool. Various concepts such as caching, scheduling, stragglers, and network performance are explored in th
0 views • 34 slides