
Understanding BI Tools for Financial Analytics with Stefano Grazioli
Explore the world of Business Intelligence (BI) tools and Financial Analytics through Excel's Pivot Table functionalities with insights from Stefano Grazioli. Delve into critical thinking and easy methodologies in BI, examining the big picture of transactions, operations, ETL technologies, and more.
0 views • 10 slides

How NLP Enhances ETL Processes for Unstructured Data know with Ask On Data
In today's data-driven landscape, unstructured data poses a significant challenge for organizations seeking to extract meaningful insights. Traditional ETL (Extract, Transform, Load) processes struggle to handle the diverse and complex nature of unstructured data, limiting the ability to harness its
2 views • 1 slides

How NLP Enhances ETL Processes for Unstructured Data know with Ask On Data
In today's data-driven landscape, unstructured data poses a significant challenge for organizations seeking to extract meaningful insights. Traditional ETL (Extract, Transform, Load) processes struggle to handle the diverse and complex nature of unstructured data, limiting the ability to harness its
1 views • 1 slides

Optimizing Workflows with an NLP Based ETL Tool
Ask On Data is a powerful NLP-based ETL tool that enables organizations to optimize workflows, extract valuable insights, and drive growth effectively. With its advanced capabilities and user-friendly interface, Ask On Data is the ideal solution for scaling operations and maximizing productivity in
0 views • 1 slides

Understanding Spark Containers and Layouts in Flex 4
Learn about Spark Containers in Flex 4, their types, differences from MX Containers, assignable layouts, what containers can hold, and more. Explore how components are sized and positioned using layout objects in Spark.
3 views • 30 slides

Data Migration vs ETL Key Difference
In the realm of data management, \"data migration\" and \"ETL\" (Extract, Transform, Load) are often used interchangeably, yet they represent distinct processes with specific use cases. Understanding the differences between these two concepts is crucial for businesses looking to optimize their data
0 views • 2 slides

Understand Role of ETL in Data Migration Extract, Transform, Load
Data migration is a critical process for businesses looking to upgrade their systems, move to the cloud, or integrate new applications. Central to this process is ETL: Extract, Transform, Load. This methodology is fundamental to ensuring that data is
0 views • 2 slides

Understanding Apache Spark: Fast, Interactive, Cluster Computing
Apache Spark, developed by Matei Zaharia and team at UC Berkeley, aims to enhance cluster computing by supporting iterative algorithms, interactive data mining, and programmability through integration with Scala. The motivation behind Spark's Resilient Distributed Datasets (RDDs) is to efficiently r
0 views • 41 slides

Introduction to Spark Streaming for Large-Scale Stream Processing
Spark Streaming, developed at UC Berkeley, extends the capabilities of Apache Spark for large-scale, near-real-time stream processing. With the ability to scale to hundreds of nodes and achieve low latencies, Spark Streaming offers efficient and fault-tolerant stateful stream processing through a si
0 views • 30 slides

Deep Dive into ETL Workflow for Integrating OMOP Data Models
This content delves into the process of ETL (Extract, Transform, Load) for integrating OMOP (Observational Medical Outcomes Partnership) data models, focusing on mapping ALPHA residencies to the OMOP person table. It covers loading data, data profiling, and mapping strategies in a detailed demonstra
1 views • 9 slides

Spark: Revolutionizing Big Data Processing
Learn about Apache Spark and RDDs in this lecture by Kishore Pusukuri. Explore the motivation behind Spark, its basics, programming, history of Hadoop and Spark, integration with different cluster managers, and the Spark ecosystem. Discover the key ideas behind Spark's design focused on Resilient Di
0 views • 59 slides

Ask On Data Uses NLP to Simplify ETL
In today\u2019s data-driven world, managing and processing vast amounts of information is crucial for businesses to make informed decisions. Traditionally, Extract, Transform, Load (ETL) processes have been the backbone of data integration, enabling
1 views • 3 slides

Unlocking the Power of Data with NLP Based ETL Tools like Ask On Data
In today\u2019s data-driven world, businesses face the challenge of managing, processing, and analyzing vast amounts of data. Traditional ETL (Extract, Transform, Load) tools have long been the backbone of data integration and processing, enabling or
0 views • 3 slides

Understanding the Importance of ETL in Modern Business Operations
ETL (Extract, Transform, Load) plays a crucial role in enabling organizations to effectively analyze and utilize their data for making informed business decisions. By extracting data from various sources, performing necessary transformations, and loading it into a central Data Warehouse, ETL facilit
0 views • 31 slides

Overview of Modernizing Analytics Infrastructure at Ebates
Ebates, under the leadership of Mark Stange-Tregear, embarked on a journey to modernize its analytics infrastructure by transitioning from on-premise setups to cloud-based solutions. Through the adoption of guiding principles like minimizing ETL steps and siloing, consolidating business logic, and f
0 views • 14 slides

Understanding the Ignition System in Internal Combustion Engines
The ignition system in spark ignition engines initiates combustion through electric discharge across the spark plug electrodes. It ensures proper ignition timing for efficient engine operation at various speeds and loads. Modern ignition systems include battery, magneto, and electronic ignition type
0 views • 21 slides

4-H Spark Achievement Program Overview
The 4-H Spark Achievement Program empowers youth through meaningful partnerships, goal setting, and inspiring change. Members can earn different levels by completing various activities and can participate in leadership roles to enhance their skills. The program encourages community service and self-
0 views • 24 slides

Muriel Spark: A Literary Journey Through Time
Explore the life and works of acclaimed author Muriel Spark, from her Edinburgh upbringing to her prolific writing career. Delve into her novels, themes of duality, and narrative techniques that challenge traditional realism, all set against the backdrop of post-war Britain.
0 views • 13 slides

Transforming Data Engineering The Rise of NLP Based ETL Tools like Ask On Data
In the era of big data, organizations are inundated with vast amounts of information generated from various sources. Extracting meaningful insights from this data requires robust ETL (Extract, Transform, Load) processes. Traditionally, ETL tools have
0 views • 2 slides

Understanding RICE MACT and its Impact on Air Quality
The RICE MACT (Maximum Achievable Control Technology) regulation aims to reduce emissions of Hazardous Air Pollutants (HAPs) from reciprocating internal combustion engines. It applies to major industrial sources emitting significant amounts of HAPs and outlines emission requirements for different ty
0 views • 26 slides

Spark & MongoDB Integration for LSST Workshop
Explore the use of Spark and MongoDB for processing workflows in the LSST workshop, focusing on parallelism, distribution, intermediate data handling, data management, and distribution methods. Learn about converting data formats, utilizing GeoSpark for 2D indexing, and comparing features with QServ
0 views • 22 slides

Introduction to Apache Spark: Simplifying Big Data Analytics
Explore the advantages of Apache Spark over traditional systems like MapReduce for big data analytics. Learn about Resilient Distributed Datasets (RDDs), fault tolerance, and efficient data processing on commodity clusters through coarse-grained transformations. Discover how Spark simplifies batch p
0 views • 17 slides

Introduction to Spark: Lightning-Fast Cluster Computing
Spark is a parallel computing system developed at UC Berkeley that aims to provide lightning-fast cluster computing capabilities. It offers a high-level API in Scala and supports in-memory execution, making it efficient for data analytics tasks. With a focus on scalability and ease of deployment, Sp
0 views • 17 slides

Evolution of Database Systems: A Spark SQL Perspective
Explore the evolution of database systems, specifically focusing on Spark SQL, NoSQL, and column stores for OLAP. Learn about the history of parallel DB systems, common complaints, the story of NoSQL, and the advantages of column stores for data aggregation and compression in OLAP scenarios.
0 views • 25 slides

Introduction to Map-Reduce and Spark in Parallel Programming
Explore the concepts of Map-Reduce and Apache Spark for parallel programming. Understand how to transform and aggregate data using functions, and work with Resilient Distributed Datasets (RDDs) in Spark. Learn how to efficiently process data and perform calculations like estimating Pi using Spark's
0 views • 11 slides

Analyzing Break-In Attempts Across Multiple Servers using Apache Spark
Exploring cyber attacks on West Chester University's servers by analyzing security logs from five online servers using Apache Spark for large-scale data analysis. Uncovering attack types, frequency patterns, and sources to enhance security measures. Discover insights on break-in attempts and potenti
0 views • 19 slides

Efficient Spark ETL on Hadoop: SETL Approach
An overview of how SETL offers an efficient approach to Spark ETL on Hadoop, focusing on reducing memory footprint, file size management, and utilizing low-level file-format APIs. With significant performance improvements, including reducing task hours by 83% and file count by 87%, SETL streamlines
0 views • 17 slides

Introduction to Spark in The Hadoop Stack
Introduction to Spark, a high-performance in-memory data analysis system layered on top of Hadoop to overcome the limitations of the Map-Reduce paradigm. It discusses the importance of Spark in addressing the expressive limitations of Hadoop's Map-Reduce, enabling algorithms that are not easily expr
0 views • 16 slides

Introduction to Interactive Data Analytics with Spark on Tachyon
Explore the collaboration between Baidu and Tachyon Nexus in advancing interactive data analytics with Spark on Tachyon. Learn about the team, Tachyon's history, features, and why it's a fast-growing open-source project. Discover how Tachyon enables efficient memory-centric distributed storage and i
0 views • 44 slides

Introduction to Spark: Lightning-fast Cluster Computing
Apache Spark is a fast and general-purpose cluster computing system that provides high-level APIs in Java, Scala, and Python. It supports a rich set of higher-level tools like Spark SQL for structured data processing and MLlib for machine learning. Spark was developed at UC Berkeley AMPLab in 2009 a
0 views • 100 slides

Understanding Oregon's Quality Rating and Improvement System (QRIS) Training Overview
This training provides an in-depth look at Oregon's Quality Rating and Improvement System (QRIS), covering topics such as the Quality Improvement Plan, participation in Spark, program supports and incentives, portfolio submission, Spark partners, and more. Gain valuable knowledge and tools to enhanc
0 views • 45 slides

Understanding Apache Spark: A Comprehensive Overview
Apache Spark is a powerful open-source cluster computing framework known for its in-memory analytics capabilities, contrasting Hadoop's disk-based paradigm. Spark applications run independently on clusters, coordinated by SparkContext. Resilient Distributed Datasets (RDDs) form the core of Spark's d
0 views • 16 slides

Distributed Volumetric Data Analytics Toolkit on Apache Spark
This paper discusses the challenges, methodology, experiments, and conclusions of implementing a distributed volumetric data analytics toolkit on Apache Spark to address the performance of large distributed multi-dimensional arrays on big data analytics platforms. The toolkit aims to handle the expo
0 views • 33 slides

Comprehensive Guide to Setting Up Apache Spark for Data Processing
Learn how to install and configure Apache Spark for data processing with single-node and multiple-worker setups, using both manual and docker approaches. Includes steps for installing required tools like Maven, JDK, Scala, Python, and Hadoop, along with testing the Wordcount program in both Scala an
0 views • 53 slides

Overview of Spark SQL: A Revolutionary Approach to Relational Data Processing
Spark SQL revolutionized relational data processing by tightly integrating relational and procedural paradigms through its declarative DataFrame API. It introduced the Catalyst optimizer, making it easier to add data sources and optimization rules. Previous attempts with MapReduce, Pig, Hive, and Dr
0 views • 29 slides
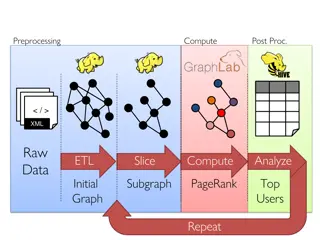
Data Processing and Analysis for Graph-Based Algorithms
This content delves into the preprocessing, computing, post-processing, and analysis of raw XML data for graph-based algorithms. It covers topics such as data ETL, graph analytics, PageRank computation, and identifying top users. Various tools and frameworks like GraphX, Spark, Giraph, and GraphLab
0 views • 8 slides

Overview of Delta Lake, Apache Spark, and Databricks Pricing
Delta Lake is an open-source storage layer that enables ACID transactions in big data workloads. Apache Spark is a unified analytics engine supporting various libraries for large-scale data processing. Databricks offers a pricing model based on DBUs, providing support for AWS and Microsoft Azure. Ex
0 views • 16 slides

Connecting Spark to Files Containing Data - Overview of RDD Model Expansion
Today's lecture explores the evolution of Spark from its inception at Berkeley to its widespread adoption globally. The focus is on the RDD model, which has transitioned into a full programming language resembling SQL, Python, or Scala. Examples of RDD programming at Cornell and in industry settings
0 views • 53 slides

Understanding Topological Sorting in Spark GraphX
Explore the essential concepts of Topological Sorting in Spark GraphX, including necessary background knowledge, stand-alone versus distributed implementations, and practical examples. Delve into Spark GraphX's capabilities, such as RDD manipulation, high-level tools, and graph parallel computation.
0 views • 56 slides

Making Sense of Spark Performance at UC Berkeley
PhD student at UC Berkeley presents an overview of Spark performance, discussing measurement techniques, performance bottlenecks, and in-depth analysis of workloads using a performance analysis tool. Various concepts such as caching, scheduling, stragglers, and network performance are explored in th
0 views • 34 slides