
727003-B21 HP BL460C G9 E5-2695 V3 14-CORE PROCESSOR KIT
Refurbished | HP 727003-B21 | BL460C G9 E5-2695 V3 14-CORE PROCESSOR KIT | \u2713 FREE and FAST Ground Shipping across the U.S. | Best Price Guaranteed\n\n\/\/ \/727003-b21-hp-bl460c-g9-e5-2695-v3-14-core-processor-kit\/
0 views • 1 slides

Evolution of IBM System/360 Architecture and Instruction Set Architectures
The IBM System/360 (S/360) mainframe computer system family, introduced in 1964, revolutionized computing by offering forward and backward compatibility, a unified instruction set architecture (ISA), and a balance between scientific and business efficiency. The critical elements of this architecture
3 views • 18 slides

Understanding Cache and Virtual Memory in Computer Systems
A computer's memory system is crucial for ensuring fast and uninterrupted access to data by the processor. This system comprises internal processor memories, primary memory, and secondary memory such as hard drives. The utilization of cache memory helps bridge the speed gap between the CPU and main
2 views • 47 slides

Understanding Superscalar Processors in Processor Design
Explore the concept of superscalar processors in processor design, including the ability to execute instructions independently and concurrently. Learn about the difference between superscalar and superpipelined approaches, instruction-level parallelism, and the limitations and design issues involved
1 views • 55 slides

Understanding Basic Input/Output Operations in Computer Organization
Basic Input/Output Operations are essential functions in computer systems that involve transferring data between processors and external devices like keyboards and displays. This task requires synchronization mechanisms due to differences in processing speeds. The process involves reading characters
0 views • 11 slides

Buy 872012-B21 HPE BL460C GEN10 XEON-S 4110 PROCESSOR KIT
Refurbished | HPE 872012-B21 | BL460C GEN10 XEON-S 4110 PROCESSOR KIT | \u2713 FREE and FAST Ground Shipping across the U.S. | Best Price Guaranteed\n\n\/\/ \/872012-b21-hpe-bl460c-gen10-xeon-s-4110-processor-kit\/
0 views • 1 slides

Processor Control Unit and ALU Implementation Overview
In Chapter 4, the processor's control unit and ALU are detailed in a simple implementation scheme. The ALU performs operations based on opcode values, while the control unit provides signals for various functions such as load/store, compare, and branch. Decoding techniques and control signal generat
1 views • 21 slides

Understanding Shared Memory Architectures and Cache Coherence
Shared memory architectures involve multiple CPUs sharing one memory with a global address space, with challenges like the cache coherence problem. This summary delves into UMA and NUMA architectures, addressing issues like memory latency and bandwidth, as well as the bus-based UMA and NUMA shared m
0 views • 27 slides
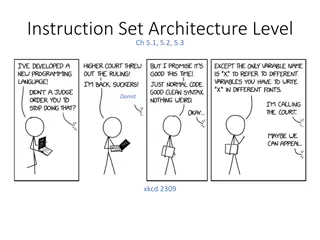
Understanding Instruction Set Architecture and Data Types in Computer Systems
In computer architecture, the Instruction Set Architecture (ISA) level is crucial in defining how a processor executes instructions. This includes the formal defining documents, memory models, registers, and various data types that can be supported. The ISA level specifies the capabilities of a proc
3 views • 13 slides

Understanding Computer System Architectures
Computer systems can be categorized into single-processor and multiprocessor systems. Single-processor systems have one main CPU but may also contain special-purpose processors. Multiprocessor systems have multiple processors that share resources, offering advantages like increased throughput, econo
2 views • 25 slides

Techniques for Reducing Connected-Standby Energy Consumption in Mobile Devices
Mobile devices spend a significant amount of time in connected-standby mode, leading to energy inefficiency in the Deepest-Runtime-Idle-Power State (DRIPS). This study introduces Optimized DRIPS (ODRIPS) to address this issue by offloading wake-up timer events, powering off IO signals, and transferr
1 views • 31 slides

Understanding Processor Interrupts and Exception Handling in Zynq Systems
Learn about interrupts, exceptions, and their handling in Zynq Systems. Explore concepts like interrupt sources, Cortex-A9 processor interrupts, interrupt terminology, and the difference between pooling and hardware interrupts. Gain insights into interrupt service routines, interrupt pins, interrupt
1 views • 60 slides

In-Depth Look at Pentium Processor Features
Explore the advanced features of the Pentium processor, including separate instruction and data caches, dual integer pipelines, superscalar execution, support for multitasking, and more. Learn about its 32-bit architecture, power management capabilities, internal error detection features, and the ef
0 views • 24 slides

Trends in Computer Organization and Architecture
This content delves into various aspects of computer organization and architecture, covering topics such as multicore computers, alternative chip organization, Intel hardware trends, processor trends, power consumption projections, and performance effects of multiple cores. It also discusses the sca
5 views • 28 slides

Understanding Shared Memory Architectures and Cache Coherence
Shared memory architectures involve multiple CPUs accessing a common memory, leading to challenges like the cache coherence problem. This article delves into different types of shared memory architectures, such as UMA and NUMA, and explores the cache coherence issue and protocols. It also highlights
2 views • 27 slides

Parallel Processing and SIMD Architecture Overview
Parallel processors in advanced computer systems utilize multiple processing units connected through an interconnection network. This enables communication via shared memory or message passing methods. Multiprocessors offer increased speed and cost-effectiveness compared to single-processor systems
3 views • 24 slides

Understanding Processor Speculation and Optimization
Dive into the world of processor speculation techniques and optimizations, including compiler and hardware support for speculative execution. Explore how speculation can enhance performance by guessing instruction outcomes and rolling back if needed. Learn about static and dynamic speculation, handl
0 views • 33 slides

Understanding Pipelined Control in Processor Architecture
Explore the intricacies of pipelined control in processor design, detailing the control signals required at each stage of the pipeline. Learn about data hazards, forwarding, and stalling techniques to ensure efficient instruction execution. Dive into the concept of optimized control values for strea
0 views • 16 slides
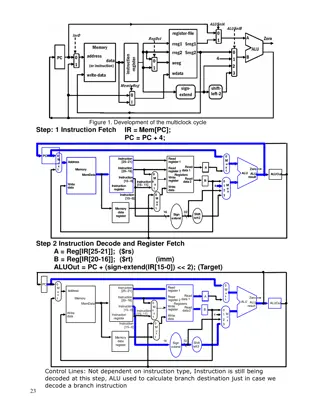
Development of Multiclock Cycle in Processor
The development process of the multiclock cycle in a processor is explained in detail through different steps, including instruction fetch, decode, register fetch, execution, and write-back for R-type instructions. Control lines and branching execution are also covered in the description. The conten
0 views • 5 slides

Overview of Inter-Processor Communication (IPC) in Processor Communication Link
Overview of Inter-Processor Communication (IPC) entails communication between processors, synchronization methods, and supported device types. The IPC architecture supports diverse use cases with various thread combinations and messaging types, catering to multi- or uni-processor environments. The A
0 views • 110 slides

Variations in Computer Architectures: RISC, CISC, and ISA Explained
Delve into the realm of computer architectures with a detailed exploration of Reduced Instruction Set Computing (RISC), Complex Instruction Set Computing (CISC), and Instruction Set Architecture (ISA) variations explained by Prof. Kavita Bala and Prof. Hakim Weatherspoon at Cornell University. Explo
0 views • 55 slides

Research Insights on Future Internet Architectures
This survey explores key research topics in designing future internet architectures, focusing on innovations, content/data-oriented paradigms, mobility challenges, cloud-computing architectures, security considerations, and experimental testbeds. The study emphasizes the need for collaborative proje
0 views • 43 slides

Exploring Instruction Level Parallel Architectures in Embedded Computer Architecture
Delve into the intricacies of Instruction Level Parallel Architectures, including topics such as Out-Of-Order execution, Hardware speculation, Branch prediction, and more. Understand the concept of Speculation in Hardware-based execution and the role of Reorder Buffer in managing instruction results
0 views • 51 slides

Embedded Computer Architecture - Instruction Level Parallel Architectures Overview
This material provides an in-depth look into Instruction Level Parallel (ILP) architectures, covering topics such as hazards, out-of-order execution, branch prediction, and multiple issue architectures. It compares Single-Issue RISC with Superscalar and VLIW architectures, discussing their differenc
0 views • 49 slides

Understanding Processor Hazards and Pipeline Stalls
Explore processor hazards like load-use and data hazards, along with strategies to avoid stalls in the pipeline. Discover how to detect and handle hazards efficiently for optimal performance in computer architecture. Learn about forwarding conditions, datapath design, and the impact of hazards on in
0 views • 30 slides

Out-of-Order Processor Design Exploration
Explore the design of an Out-of-Order (OOO) processor with an architectural register file, aggressive speculation, and efficient replay mechanisms. Understand the changes to renaming, dispatch, wakeup, bypassing, register writes, and commit stages. Compare Processor Register File (PRF) based design
1 views • 29 slides

Enhancing Processor Performance Through Rollback-Free Value Prediction
Mitigating memory and bandwidth walls, this research extends rollback-free value prediction to GPUs, achieving up to 2x improvement in energy and performance while maintaining 10% quality degradation. Utilizing microarchitecturally-triggered approximation to predict missed loads, this work focuses o
0 views • 7 slides

Understanding OpenMP Programming on NUMA Architectures
In NUMA architectures, data placement and thread binding significantly impact application performance. OpenMP plays a crucial role in managing thread creation/termination and variable sharing in parallel regions. Programmers must consider NUMA architecture when optimizing for performance. This invol
0 views • 18 slides
Understanding Processor Cycles and Machine Cycles in 8085 Microprocessor
Processor cycles in microprocessors like 8085 involve executing instructions through machine cycles that are essential operations performed by the processor. In the 8085 microprocessor, there are seven basic machine cycles, each serving a specific purpose such as fetching opcodes, reading from memor
0 views • 17 slides
Understanding Computer Systems and Operating System Architectures
An exploration of computer systems and operating system architectures, covering topics such as CPU modes, monolithic and layered architectures, microkernel architecture, Linux and Windows kernel architectures, as well as devices and their terminology. The content delves into the roles, structures, a
0 views • 57 slides

Understanding Shared Memory, Distributed Memory, and Hybrid Distributed-Shared Memory
Shared memory systems allow multiple processors to access the same memory resources, with changes made by one processor visible to all others. This concept is categorized into Uniform Memory Access (UMA) and Non-Uniform Memory Access (NUMA) architectures. UMA provides equal access times to memory, w
0 views • 22 slides
IPC Lab 2 MessageQ Client/Server Example
This MessageQ example demonstrates the client/server pattern using SYS/BIOS heap for message pool, anonymous message queue, and return address implementation. The example involves two processors - HOST and DSP, where the DSP processor acts as the server creating a named message queue, and the HOST p
0 views • 12 slides

Exploring Efficient Hardware Architectures for Deep Neural Network Processing
Discover new hardware architectures designed for efficient deep neural network processing, including SCNN accelerators for compressed-sparse Convolutional Neural Networks. Learn about convolution operations, memory size versus access energy, dataflow decisions for reuse, and Planar Tiled-Input Stati
0 views • 23 slides

Trends in Implicit Parallelism and Microprocessor Architectures
Explore the implications of implicit parallelism in microprocessor architectures, addressing performance bottlenecks in processor, memory system, and datapath components. Prof. Vijay More delves into optimizing resource utilization, diverse architectural executions, and the impact on current compute
0 views • 47 slides

Understanding Processor Organization in Computer Architecture
Processor organization involves key tasks such as fetching instructions, interpreting instructions, processing data, and storing temporary data. The CPU consists of components like the ALU, control unit, and registers. Register organization plays a crucial role in optimizing memory usage and control
0 views • 21 slides

Understanding Processor Structure and Function in Computing
Explore the key components and functions of processors in computing, including user-visible and control status registers, instruction cycle, instruction pipelining, processor tasks like data processing and instruction interpretation, and the roles of arithmetic and logic units and control units. Lea
0 views • 61 slides

Understanding Processor Generations and VM Sizing for Azure Migration
Exploring the impact of processor generations on CPU performance, factors like clock speed, instruction set, and cache size are crucial. Choosing the right-sized VM plays a vital role in optimizing Azure migration. Passmark CPU Benchmark results provide insights on Intel processor generations for Az
0 views • 9 slides

Performance Comparison of 40G NFV Environments
This study compares the performance of 40G NFV environments focusing on packet processing architectures and virtual switches. It explores host architectures, NFV related work, evaluation of combinations of PM and VM architectures with different vswitches, and the impact of packet processing architec
0 views • 24 slides

Overview of Parallel Processing Architectures
This comprehensive overview delves into the taxonomy of parallel processor architectures, including SISD, SIMD, MISD, and MIMD configurations. It explores the characteristics of each architecture type, such as single vs. multiple instruction streams and data streams. The images provided visually rep
0 views • 76 slides

Flynn's Taxonomy: Classification of Computer Architectures
Michael Flynn's 1966 classification divides computer architectures into SISD, SIMD, MISD, and MIMD based on the number of instruction streams and data streams. SISD corresponds to traditional single-processor systems, SIMD involves multiple processors handling different data streams, MISD has multip
0 views • 10 slides