Scalable Real-time Tweet Summarization in TREC 2016

This project focuses on real-time tweet summarization, presenting a scalable and effective approach developed by Reem Suwaileh, Maram Hasanain, and Tamer Elsayed during the TREC 2016 Real-time Summarization Track. The process involves various stages such as preprocessing, pre-filtering, relevance filtering, novelty filtering, and tweet nomination. A lightweight, conservative, yet efficient method is employed, which includes tasks like stemming, stopword removal, URL elimination, vector representation, and profile indexing to filter out low-quality content and ensure the relevance and novelty of selected tweets. The system utilizes techniques like cosine similarity and Jaccard similarity to assess the importance and freshness of tweets, resulting in a curated collection of relevant and novel content.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Light-weight, Conservative, yet Effective: Scalable Real-time Tweet Summarization Reem Suwaileh, Maram Hasanain,Tamer Elsayed TREC 2016: Real-time Summarization Track 18th Nov, 2016
MOBILE NOTIFICATION SCENARIO A
PREPROCESSING Tweet Stream Interest Profiles Title only Preprocessing stemming, stopword, URL removal, vector rep. Vector Representation Profile Index Stream Index in memory on disk
PRE-FILTERING Tweet Stream Interest Profiles Preprocessing stemming, stopword, URL removal, vector rep. Pre-Filtering drop non-matching & low quality tweets Profile Index Stream Index < 5 terms OR 1 URL OR > 2 hashtags
RELEVANCE FILTERING Tweet Stream Interest Profiles Preprocessing stemming, stopword, URL removal, vector rep. Pre-Filtering drop non-matching & low quality tweets Profile Index Stream Index RelevanceFiltering CosineSimilarity with profile vector > threshold Vector Representation fixed !
NOVELTY FILTERING Tweet Stream Interest Profiles Preprocessing stemming, stopword, URL removal, vector rep. Pre-Filtering drop non-matching & low quality tweets Profile Index Stream Index RelevanceFiltering CosineSimilarity with profile vector > threshold Pushed Tweets NoveltyFiltering JaccardSimilarity* with pushed tweets < threshold fixed ! |? ?| ???( ? , ? ) Relevant and Novel Tweets
TWEET NOMINATION Tweet Stream Interest Profiles Preprocessing stemming, stopword, URL removal, vector rep. Pre-Filtering drop non-matching & low quality tweets Profile Index Stream Index RelevanceFiltering CosineSimilarity with profile vector > threshold Pushed Tweets NoveltyFiltering JaccardSimilarity* with novel tweets < threshold TweetNomination Periodically: relevant, novel & fresh 30 min OR 20 relevant tweets since last push Relevant and Novel Tweets
PROFILE EXPANSION (TWEET STREAM) Over local stream Rocchio's Pseudo Relevance original topic vector title only! centroid of recent k relevant tweets only top m terms At least 1h AND 10 relevant tweets since last expansion
PROFILE EXPANSION (TWITTER SEARCH) Over Twitter API Rocchio's Pseudo Relevance original topic vector title only! centroid of top k Twitter search results only top m terms At least 1h AND 10 relevant tweets since last expansion
SUBMITTED RUNS Relevance threshold = 0.6 tuned over TREC 2015 QUBaseline NO expansion Novelty threshold = 0.6 tuned over TREC 2015 QUExpP Expansion over local Tweet Stream Pseudo results (k)= 20 Expansion terms (m) = 2 QUExpT Expansion over Twitter live search API Pseudo results (k)= 20 Expansion terms (m) = 1
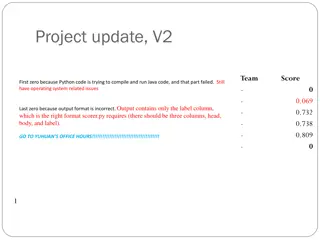
BATCH RESULTS: OFFICIAL EG-1 0.45 0.40 0.3816 0.35 0.30 0.2643 0.2552 0.2519 0.2289 0.2335 0.25 0.20 0.15 0.10 0.05 0.00 Best Median Waterloo Baseline QUBaseline QUExpP QUExpT Best: average of best per topic Median: average of medians per topic
BATCH RESULTS: OFFICIAL EG-1 Best Automatic Run! Best 3 Automatic Runs!
HUMAN EVALUATION Time Zone?
EMAIL DIGEST SCENARIO B
PREPROCESSING Tweet Stream Preprocessing stemming, stopwords, URL removal, vector rep. Stream Index
TWEET RETRIEVAL Tweet Stream Preprocessing stemming, stopwords, URL removal, vector rep. Interest Profiles TweetRetrieval Search index daily with profile title terms Retrieve tweets with score > relevance threshold Stream Index Lucene fixed !
NOVELTY FILTERING Tweet Stream Preprocessing stemming, stopwords, URL removal, vector rep. Interest Profiles TweetRetrieval Search index daily with profile title terms Retrieve tweets with score > relevance threshold Stream Index Pushed Tweets NoveltyFiltering JaccardSimilarity* with pushed tweets < threshold fixed ! |? ?| ???( ? , ? ) Relevant and Novel Tweets
TWEETS NOMINATION Tweet Stream Preprocessing stemming, stopwords, URL removal, vector rep. Interest Profiles TweetRetrieval Search index daily with profile title terms Retrieve tweets with score > relevance threshold Stream Index Pushed Tweets NoveltyFiltering JaccardSimilarity* with novel tweets < threshold TweetsNomination At the end of the day: top 100 relevant & novel Relevant and Novel Tweets
SUBMITTED RUNS Novelty threshold = 0.6 tuned over TREC 2015 QUDR8 Query-likelihood with Dirichlet smoothing. Relevance Threshold: 8 (tuned over TREC 2015) QUJM16 Query-likelihood with Jelinek Mercer smoothing. Relevance Threshold: 16 (tuned over TREC 2015) QUDRJM24 Combination of Query-likelihood with Dirichlet smoothing and Jelinek Mercer smoothing techniques. Relevance Threshold: 24 (tuned over TREC 2015)
RESULTS: SCENARIO B | OFFICIAL NDCG-1 0.50 0.4427 0.45 0.40 0.35 0.30 0.2621 0.2558 0.2352 0.25 0.2344 0.1931 0.20 0.15 0.10 0.05 0.00 Best Median Waterloo Baseline QUJM16 QUJMDR24 QUDR8 Best: average of best per topic Median: average of medians per topic
RESULTS: SCENARIO B | OFFICIAL NDCG-1 2nd Best Automatic Run!
CONCLUSION Simplicity is invaluable! Simple term weighting and straight-forward pipeline No fancy weighting, no learning, no neural, no word embedding, Conservative matching (with title only) is effective! Precision-oriented task Expansion has negative effect (so far)! Baseline non-expansion run of scenario A was the best and outperformed expansion runs
FUTURE WORK Do post-hoc/failure analysis! Explore similarity measures for relevance and novelty Investigate poor performance of PRF runs in scenario A Experiment with techniques for dynamic threshold Enhance tweet nomination strategy







")
")