Leveraging Massive Data for Enhanced Recommendations

 undefined
undefined


Mining of Massive Datasets
Jure Leskovec, Anand Rajaraman, Jeff Ullman
Stanford University
http://www.mmds.org

N
o
t
e
t
o
o
t
h
e
r
t
e
a
c
h
e
r
s
a
n
d
u
s
e
r
s
o
f
t
h
e
s
e
s
l
i
d
e
s
:
W
e
w
o
u
l
d
b
e
d
e
l
i
g
h
t
e
d
i
f
y
o
u
f
o
u
n
d
t
h
i
s
o
u
r
m
a
t
e
r
i
a
l
u
s
e
f
u
l
i
n
g
i
v
i
n
g
y
o
u
r
o
w
n
l
e
c
t
u
r
e
s
.
F
e
e
l
f
r
e
e
t
o
u
s
e
t
h
e
s
e
s
l
i
d
e
s
v
e
r
b
a
t
i
m
,
o
r
t
o
m
o
d
i
f
y
t
h
e
m
t
o
f
i
t
y
o
u
r
o
w
n
n
e
e
d
s
.
I
f
y
o
u
m
a
k
e
u
s
e
o
f
a
s
i
g
n
i
f
i
c
a
n
t
p
o
r
t
i
o
n
o
f
t
h
e
s
e
s
l
i
d
e
s
i
n
y
o
u
r
o
w
n
l
e
c
t
u
r
e
,
p
l
e
a
s
e
i
n
c
l
u
d
e
t
h
i
s
m
e
s
s
a
g
e
,
o
r
a
l
i
n
k
t
o
o
u
r
w
e
b
s
i
t
e
:
gro.sdmm.www//:ptth




J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
2




Customer X
Buys Metallica CD
Buys Megadeth CD
Customer Y
Does search on Metallica
Recommender system
suggests Megadeth from
data collected about
customer
X



J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
3





Items


Products, web sites,
blogs, news items, …
4
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org




Examples:



Shelf space is a scarce commodity for
traditional retailers
Also: TV networks, movie theaters,…
Web enables near-zero-cost dissemination
of information about products
From scarcity to abundance
More choice necessitates better filters
Recommendation engines
How
Into Thin Air
made
Touching the Void
a bestseller:
http://www.wired.com/wired/archive/12.10/tail.html
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
5
Source: Chris Anderson (2004)
6
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
7
R
e
a
d
h
t
t
p
:
/
/
w
w
w
.
w
i
r
e
d
.
c
o
m
/
w
i
r
e
d
/
a
r
c
h
i
v
e
/
1
2
.
1
0
/
t
a
i
l
.
h
t
m
l
t
o
l
e
a
r
n
m
o
r
e
!
Editorial and hand curated
List of favorites
Lists of “essential” items
Simple aggregates
Top 10, Most Popular, Recent Uploads
Tailored to individual users
Amazon, Netflix, …
8
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
X
= set of
Customers
S
= set of
Items
Utility function
u
:
X
×
S
R
R
= set of ratings
R
is a totally ordered set
e.g.,
0-5
stars, real number in
[0,1]
9
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Avatar
Avatar
LOTR
LOTR
Matrix
Matrix
Pirates
Pirates
Alice
Alice
Bob
Bob
Carol
Carol
David
David
10
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
(1)
Gathering “known” ratings for matrix
How to collect the data in the utility matrix
(2)
Extrapolate unknown ratings from the
known ones
Mainly interested in high unknown ratings
We are not interested in knowing what you don’t like
but what you like
(3)
Evaluating extrapolation methods
How to measure success/performance of
recommendation methods
11
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Explicit
Ask people to rate items
Doesn’t work well in practice – people
can’t be bothered
Implicit
Learn ratings from user actions
E.g., purchase implies high rating
What about low ratings?
12
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Key problem:
Utility matrix
U
is
sparse
Most people have not rated most items
Cold start:
New items have no ratings
New users have no history
Three approaches to recommender systems:
1)
Content-based
2)
Collaborative
3)
Latent factor based
13
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
T
o
d
a
y
!
Main idea:
Recommend items to customer
x
similar to previous items rated highly by
x
Example:
Movie recommendations
Recommend movies with same actor(s),
director, genre, …
Websites, blogs, news
Recommend other sites with “similar” content
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
15
l
i
k
e
s
I
t
e
m
p
r
o
f
i
l
e
s
R
e
d
C
i
r
c
l
e
s
T
r
i
a
n
g
l
e
s
U
s
e
r
p
r
o
f
i
l
e
m
a
t
c
h
r
e
c
o
m
m
e
n
d
b
u
i
l
d
16
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
For each item, create an
item profile
Profile is a set (vector) of features
Movies:
author, title, actor, director,…
Text:
Set of “important” words in document
How to pick important features?
Usual heuristic from text mining is
TF-IDF
(Term frequency * Inverse Doc Frequency)
Term
…
Feature
Document
…
Item
17
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
f
ij
= frequency of term (feature)
i
in doc (item)
j
n
i
= number of docs that mention term
i
N
= total number of docs
TF-IDF score:
w
ij
= TF
ij
× IDF
i
Doc profile =
set of words with highest
TF-IDF
scores, together with their scores
18
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
N
o
t
e
:
w
e
n
o
r
m
a
l
i
z
e
T
F
t
o
d
i
s
c
o
u
n
t
f
o
r
“
l
o
n
g
e
r
”
d
o
c
u
m
e
n
t
s
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
19
+: No need for data on other users
No cold-start or sparsity problems
+: Able to recommend to users with
unique tastes
+: Able to recommend new & unpopular items
No first-rater problem
+: Able to provide explanations
Can provide explanations of recommended items by
listing content-features that caused an item to be
recommended
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
20
–: Finding the appropriate features is hard
E.g., images, movies, music
–: Recommendations for new users
How to build a user profile?
–: Overspecialization
Never recommends items outside user’s
content profile
People might have multiple interests
Unable to exploit quality judgments of other users
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
21
Harnessing quality judgments of other users
Consider user
x
Find set
N
of other
users whose ratings
are “
similar
” to
x
’s ratings
Estimate
x
’s ratings
based on ratings
of users in
N
23
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
x
N
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
24
r
x
=
[
*
,
_
,
_
,
*
,
*
*
*
]
r
y
=
[
*
,
_
,
*
*
,
*
*
,
_
]
r
x
,
r
y
a
s
s
e
t
s
:
r
x
=
{1
,
4
,
5
}
r
y
=
{1
,
3
,
4
}
r
x
,
r
y
a
s
p
o
i
n
t
s
:
r
x
=
{1
,
0
,
0
,
1
,
3
}
r
y
=
{1
,
0
,
2
,
2
,
0
}
r
x
,
r
y
…
a
v
g
.
r
a
t
i
n
g
o
f
x
,
y
Intuitively we want:
sim(
A
,
B
) > sim(
A
,
C
)
Jaccard similarity:
1/5
<
2/4
Cosine similarity:
0.386
>
0.322
Considers missing ratings as “negative”
Solution: subtract the (row) mean
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
25
s
i
m
A
,
B
v
s
.
A
,
C
:
0
.
0
9
2
>
-
0
.
5
5
9
Notice cosine sim. is
correlation when
data is centered at 0
C
o
s
i
n
e
s
i
m
:
26
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
So far:
User-user collaborative filtering
Another view:
Item-item
For item
i
, find other similar items
Estimate rating for item
i
based
on ratings for similar items
Can use same similarity metrics and
prediction functions as in user-user model
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
27
s
i
j
…
s
i
m
i
l
a
r
i
t
y
o
f
i
t
e
m
s
i
a
n
d
j
r
x
j
…
r
a
t
i
n
g
o
f
u
s
e
r
u
o
n
i
t
e
m
j
N
(
i
;
x
)
…
s
e
t
i
t
e
m
s
r
a
t
e
d
b
y
x
s
i
m
i
l
a
r
t
o
i
users
movies
28
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
users
-
e
s
t
i
m
a
t
e
r
a
t
i
n
g
o
f
m
o
v
i
e
1
b
y
u
s
e
r
5
29
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
movies
users
N
e
i
g
h
b
o
r
s
e
l
e
c
t
i
o
n
:
I
d
e
n
t
i
f
y
m
o
v
i
e
s
s
i
m
i
l
a
r
t
o
m
o
v
i
e
1
,
r
a
t
e
d
b
y
u
s
e
r
5
30
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
movies
1
.
0
0
-
0
.
1
8
0
.
4
1
-
0
.
1
0
-
0
.
3
1
0
.
5
9
s
i
m
(
1
,
m
)
H
e
r
e
w
e
u
s
e
P
e
a
r
s
o
n
c
o
r
r
e
l
a
t
i
o
n
a
s
s
i
m
i
l
a
r
i
t
y
:
1
)
S
u
b
t
r
a
c
t
m
e
a
n
r
a
t
i
n
g
m
i
f
r
o
m
e
a
c
h
m
o
v
i
e
i
m
1
=
(
1
+
3
+
5
+
5
+
4
)
/
5
=
3
.
6
r
o
w
1
:
[
-
2
.
6
,
0
,
-
0
.
6
,
0
,
0
,
1
.
4
,
0
,
0
,
1
.
4
,
0
,
0
.
4
,
0
]
2
)
C
o
m
p
u
t
e
c
o
s
i
n
e
s
i
m
i
l
a
r
i
t
i
e
s
b
e
t
w
e
e
n
r
o
w
s
users
C
o
m
p
u
t
e
s
i
m
i
l
a
r
i
t
y
w
e
i
g
h
t
s
:
s
1
,
3
=
0
.
4
1
,
s
1
,
6
=
0
.
5
9
31
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
movies
1
.
0
0
-
0
.
1
8
0
.
4
1
-
0
.
1
0
-
0
.
3
1
0
.
5
9
s
i
m
(
1
,
m
)
users
P
r
e
d
i
c
t
b
y
t
a
k
i
n
g
w
e
i
g
h
t
e
d
a
v
e
r
a
g
e
:
r
1
.
5
=
(
0
.
4
1
*
2
+
0
.
5
9
*
3
)
/
(
0
.
4
1
+
0
.
5
9
)
=
2
.
6
32
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
movies
Define
similarity
s
ij
of items
i
and
j
Select
k
nearest neighbors
N(i; x)
Items most similar to
i
, that were rated by
x
Estimate rating
r
xi
as the weighted average:
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
33
baseline estimate for
r
xi
μ
= overall mean movie rating
b
x
= rating deviation of user
x
= (
avg. rating of user
x
)
–
μ
b
i
= rating deviation of movie
i
B
e
f
o
r
e
:
Avatar
Avatar
LOTR
LOTR
Matrix
Matrix
Pirates
Pirates
Alice
Alice
Bob
Bob
Carol
Carol
David
David
34
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
In practice, it has been observed that
item-item
often works better than user-user
Why?
Items are simpler, users have multiple tastes
+ Works for any kind of item
No feature selection needed
- Cold Start:
Need enough users in the system to find a match
- Sparsity:
The user/ratings matrix is sparse
Hard to find users that have rated the same items
- First rater:
Cannot recommend an item that has not been
previously rated
New items, Esoteric items
- Popularity bias:
Cannot recommend items to someone with
unique taste
Tends to recommend popular items
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
35
Implement two or more different
recommenders and combine predictions
Perhaps using a linear model
Add content-based methods to
collaborative filtering
Item profiles for new item problem
Demographics to deal with new user problem
36
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
- Evaluation
- Error metrics
- Complexity / Speed
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
37
movies
users
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
38
Test Data Set
users
movies
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
39
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
40
Narrow focus on accuracy sometimes
misses the point
Prediction Diversity
Prediction Context
Order of predictions
In practice, we care only to predict high
ratings:
RMSE might penalize a method that does well
for high ratings and badly for others
41
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Expensive step is finding
k
most similar
customers:
O(|X|)
Too expensive to do at runtime
Could pre-compute
Naïve pre-computation takes time
O(k ·|X|)
X … set of customers
We already know how to do this!
Near-neighbor search in high dimensions (
LSH
)
Clustering
Dimensionality reduction
42
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Leverage all the data
Don’t try to reduce data size in an
effort to make fancy algorithms work
Simple methods on large data do best
Add more data
e.g., add IMDB data on genres
More data beats better algorithms
http://anand.typepad.com/datawocky/2008/03/more-data-usual.html
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
43
The slides provide valuable insights into utilizing massive datasets for improving recommendation systems. Topics covered include high-dimensional data, customer behavior analysis, examples of application in search and recommendations, scarcity to abundance in retail, and the importance of recommendation engines in the digital age.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Note to other teachers and users of these slides: We would be delighted if you found this our material useful in giving your own lectures. Feel free to use these slides verbatim, or to modify them to fit your own needs. If you make use of a significant portion of these slides in your own lecture, please include this message, or a link to our web site: http://www.mmds.org Mining of Massive Datasets Jure Leskovec, Anand Rajaraman, Jeff Ullman Stanford University http://www.mmds.org
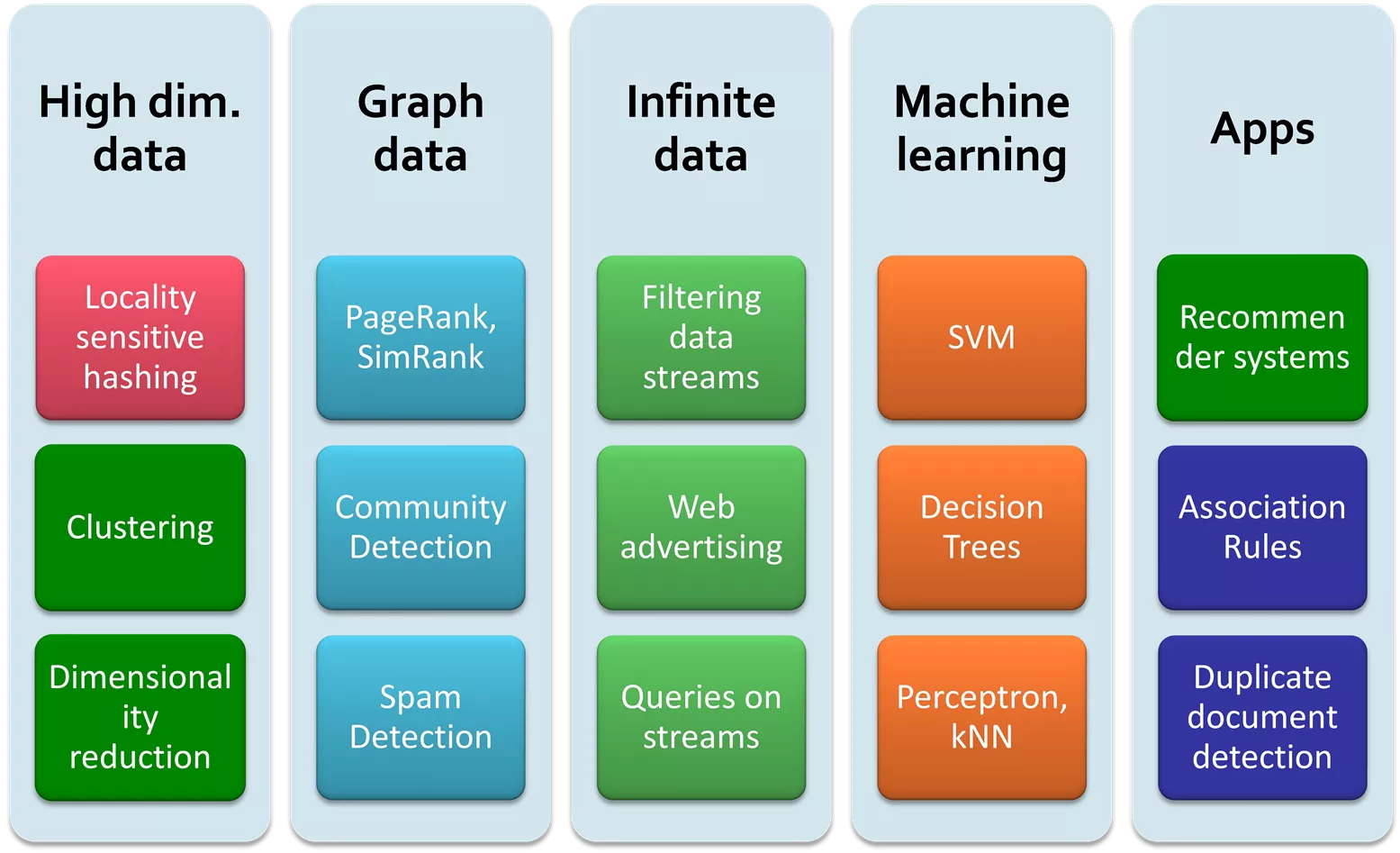
High dim. data Graph data Infinite data Machine learning Apps Locality sensitive hashing Filtering data streams PageRank, SimRank Recommen der systems SVM Community Detection Web Decision Trees Association Rules Clustering advertising Dimensional ity reduction Duplicate document detection Spam Detection Queries on streams Perceptron, kNN J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 2
Customer Y Does search on Metallica Recommender system suggests Megadeth from data collected about customer X Customer X Buys Metallica CD Buys Megadeth CD J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 3
Examples: Search Recommendations Products, web sites, blogs, news items, Items J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 4
Shelf space is a scarce commodity for traditional retailers Also: TV networks, movie theaters, Web enables near-zero-cost dissemination of information about products From scarcity to abundance More choice necessitates better filters Recommendation engines How Into Thin Air made Touching the Void a bestseller: http://www.wired.com/wired/archive/12.10/tail.html J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 5
Source: Chris Anderson (2004) J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 6
Read http://www.wired.com/wired/archive/12.10/tail.html to learn more! J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 7
Editorial and hand curated List of favorites Lists of essential items Simple aggregates Top 10, Most Popular, Recent Uploads Tailored to individual users Amazon, Netflix, J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 8
X = set of Customers S = set of Items Utility functionu: X S R R= set of ratings R is a totally ordered set e.g., 0-5 stars, real number in [0,1] J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 9
Avatar LOTR Matrix Pirates 1 0.2 Alice 0.5 0.3 Bob 0.2 1 Carol 0.4 David J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 10
(1) Gathering known ratings for matrix How to collect the data in the utility matrix (2) Extrapolate unknown ratings from the known ones Mainly interested in high unknown ratings We are not interested in knowing what you don t like but what you like (3) Evaluating extrapolation methods How to measure success/performance of recommendation methods J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 11
Explicit Ask people to rate items Doesn t work well in practice people can t be bothered Implicit Learn ratings from user actions E.g., purchase implies high rating What about low ratings? J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 12
Key problem: Utility matrix U is sparse Most people have not rated most items Cold start: New items have no ratings New users have no history Three approaches to recommender systems: 1) Content-based 2) Collaborative 3) Latent factor based Today! J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 13
Main idea: Recommend items to customer x similar to previous items rated highly by x Example: Movie recommendations Recommend movies with same actor(s), director, genre, Websites, blogs, news Recommend other sites with similar content J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 15
Item profiles likes build recommend Red Circles Triangles match User profile J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 16
For each item, create an item profile Profile is a set (vector) of features Movies:author, title, actor, director, Text:Set of important words in document How to pick important features? Usual heuristic from text mining is TF-IDF (Term frequency * Inverse Doc Frequency) Term Feature Document Item J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 17
fij = frequency of term (feature) i in doc (item) j Note: we normalize TF to discount for longer documents ni = number of docs that mention term i N = total number of docs TF-IDF score:wij = TFij IDFi Doc profile = set of words with highest TF-IDF scores, together with their scores J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 18
User profile possibilities: Weighted average of rated item profiles Variation: weight by difference from average rating for item Prediction heuristic: Given user profile x and item profile i, estimate ?(?,?) = cos(?,?) = ? ? | ? | | ? | J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 19
+: No need for data on other users No cold-start or sparsity problems +: Able to recommend to users with unique tastes +: Able to recommend new & unpopular items No first-rater problem +: Able to provide explanations Can provide explanations of recommended items by listing content-features that caused an item to be recommended J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 20
: Finding the appropriate features is hard E.g., images, movies, music : Recommendations for new users How to build a user profile? : Overspecialization Never recommends items outside user s content profile People might have multiple interests Unable to exploit quality judgments of other users J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 21
Consider user x Find set N of other users whose ratings are similar to x s ratings x N Estimate x s ratings based on ratings of users in N J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 23
rx = [*, _, _, *, ***] ry = [*, _, **, **, _] Let rx be the vector of user x s ratings Jaccard similarity measure Problem: Ignores the value of the rating Cosine similarity measure rx, ry as sets: rx = {1, 4, 5} ry = {1, 3, 4} rx, ry as points: rx = {1, 0, 0, 1, 3} ry = {1, 0, 2, 2, 0} ?? ?? sim(x, y) = cos(rx, ry) = Problem:Treats missing ratings as negative Pearson correlation coefficient Sxy = items rated by both users x and y ? ?????? ?? ||??|| ||??|| ??? ?? ??? ?,? = ? ? ? ?????? ?? ? ?????? ?? rx, ry avg. rating of x, y J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 24
Cosine sim: ???? ??? ???(?,?) = ? ? ???? ???? Intuitively we want: sim(A, B) > sim(A, C) Jaccard similarity: 1/5 < 2/4 Cosine similarity: 0.386 > 0.322 Considers missing ratings as negative Solution: subtract the (row) mean sim A,B vs. A,C: 0.092 > -0.559 Notice cosine sim. is correlation when data is centered at 0 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 25
From similarity metric to recommendations: Let rx be the vector of user x s ratings Let N be the set of k users most similar to x who have rated item i Prediction for item s of user x: ???=1 ? ? ???? Shorthand: ???= ??? ?,? ? ???? ??? ? ???? ???= Other options? Many other tricks possible J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 26
So far:User-user collaborative filtering Another view: Item-item For item i, find other similar items Estimate rating for item i based on ratings for similar items Can use same similarity metrics and prediction functions as in user-user model = ij s s r ij xj ( ; ) j N i x r xi sij similarity of items iand j rxj rating of user u on item j N(i;x) set items rated by x similar toi j ( ; ) N i x J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 27
users 1 2 3 4 5 6 7 8 9 10 11 12 1 1 3 5 5 4 2 5 4 2 1 3 4 movies 3 2 4 1 2 3 4 3 5 4 2 4 5 4 2 5 4 3 4 2 2 5 6 1 3 3 2 4 - unknown rating - rating between 1 to 5 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 28
users 1 2 3 4 6 7 8 9 10 11 12 5 1 1 3 5 5 4 ? 2 5 4 2 1 3 4 movies 3 2 4 1 2 3 4 3 5 4 2 4 5 4 2 5 4 3 4 2 2 5 6 1 3 3 2 4 - estimate rating of movie 1 by user 5 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 29
users 1 2 3 4 6 7 8 9 10 11 12 5 sim(1,m) 1 1 3 5 5 4 ? 1.00 2 5 4 2 1 3 4 -0.18 movies 2 4 1 2 3 4 3 5 3 0.41 4 2 4 5 4 2 -0.10 5 4 3 4 2 2 5 -0.31 1 3 3 2 4 6 0.59 Here we use Pearson correlation as similarity: 1) Subtract mean rating mi from each movie i m1= (1+3+5+5+4)/5 = 3.6 row 1: [-2.6, 0, -0.6, 0, 0, 1.4, 0, 0, 1.4, 0, 0.4, 0] 2) Compute cosine similarities between rows Neighbor selection: Identify movies similar to movie 1, rated by user 5 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 30
users 1 2 3 4 5 6 7 8 9 10 11 12 sim(1,m) 1 1 3 5 5 4 ? 1.00 2 5 4 2 1 3 4 -0.18 movies 2 4 1 2 3 4 3 5 3 0.41 4 2 4 5 4 2 -0.10 5 4 3 4 2 2 5 -0.31 1 3 3 2 4 6 0.59 Compute similarity weights: s1,3=0.41, s1,6=0.59 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 31
users 1 2 3 4 5 6 7 8 9 10 11 12 1 1 3 5 5 4 2.6 2 5 4 2 1 3 4 movies 2 4 1 2 3 4 3 5 3 4 2 4 5 4 2 5 4 3 4 2 2 5 1 3 3 2 4 6 Predict by taking weighted average: ? ?(?;?)??? ??? ??? ???= r1.5 = (0.41*2 + 0.59*3) / (0.41+0.59) = 2.6 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 32
Before: s r ij s xj j ( ; ) N i x = r xi ij j ( ; ) N i x Define similarity sij of items i and j Select k nearest neighbors N(i; x) Items most similar to i, that were rated by x Estimate rating rxi as the weighted average: + = xi xi b r ( ) s r b ij xj s xj ( ; ) j N i x ij j ( ; ) N i x baseline estimate for rxi ???= ? + ??+ ?? = overall mean movie rating bx = rating deviation of user x = (avg. rating of user x) bi = rating deviation of movie i J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 33
Avatar LOTR Matrix Pirates 1 0.8 Alice 0.5 0.3 Bob 0.9 1 8 . 0 Carol 1 0.4 David In practice, it has been observed that item-item often works better than user-user Why? Items are simpler, users have multiple tastes J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 34
+ Works for any kind of item No feature selection needed - Cold Start: Need enough users in the system to find a match - Sparsity: The user/ratings matrix is sparse Hard to find users that have rated the same items - First rater: Cannot recommend an item that has not been previously rated New items, Esoteric items - Popularity bias: Cannot recommend items to someone with unique taste Tends to recommend popular items J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 35
Implement two or more different recommenders and combine predictions Perhaps using a linear model Add content-based methods to collaborative filtering Item profiles for new item problem Demographics to deal with new user problem J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 36
- Evaluation - Error metrics - Complexity / Speed J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 37
movies 1 3 4 3 5 5 4 5 5 3 users 3 2 2 2 5 2 1 1 3 3 1 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 38
movies 1 3 4 3 5 5 4 5 5 3 users 3 2 ? ? Test Data Set ? 2 1 ? 3 ? 1 J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 39
Compare predictions with known ratings Root-mean-square error (RMSE) 2 where ??? is predicted, ??? is the true rating of x on i ????? ??? Precision at top 10: % of those in top 10 Rank Correlation: Spearman s correlationbetween system s and user s complete rankings Another approach: 0/1 model Coverage: Number of items/users for which system can make predictions Precision: Accuracy of predictions Receiver operating characteristic (ROC) Tradeoff curve between false positives and false negatives J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 40
Narrow focus on accuracy sometimes misses the point Prediction Diversity Prediction Context Order of predictions In practice, we care only to predict high ratings: RMSE might penalize a method that does well for high ratings and badly for others J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 41
Expensive step is finding k most similar customers: O(|X|) Too expensive to do at runtime Could pre-compute Na ve pre-computation takes time O(k |X|) X set of customers We already know how to do this! Near-neighbor search in high dimensions (LSH) Clustering Dimensionality reduction J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 42
Leverage all the data Don t try to reduce data size in an effort to make fancy algorithms work Simple methods on large data do best Add more data e.g., add IMDB data on genres More data beats better algorithms http://anand.typepad.com/datawocky/2008/03/more-data-usual.html J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org 43





")



 Gathering “known” ratings for matrix")






 i in doc (item) j")