Enhancing Phylogenetic Analysis Using Divide-and-Conquer Methods

Large-scale phylogenetics presents challenges due to NP-hardness and dataset sizes. Divide-and-conquer methods like SATe, PASTA, and MAGUS enable efficient processing of large datasets by dividing, aligning, and merging subsets with accuracy. MAGUS, a variant of PASTA, utilizes a unique alignment merging technique and shows improved alignment error rates. Addressing the need for better maximum likelihood methods, Disjoint Tree Mergers offer enhancements over RAxML and IQ-TREE2, with pipelines starting from FastTree or IQ-TREE. These methods advance species tree estimation for gene duplication scenarios like MUL-trees.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
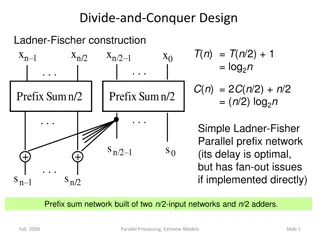
Survey of Divide-and- Conquer Methods
Large-scale phylogenetics Everything is NP-hard, there are many big datasets, and many of the most accurate methods don t run well on large datasets Divide-and-conquer makes it possible to use computationally intensive methods on large datasets Divide dataset into subsets using fast method Construct alignments on each subset using expensive but accurate method Merge the alignments together using fast method Can be combined with iteration
Using divide-and-conquer Multiple sequence alignment methods: SATe, PASTA, and MAGUS Maximum likelihood tree estimation: using Disjoint Tree Mergers Phylogenetic placement: eXtended Range (XR) Species trees in the presence of gene duplication and loss: DISCO
MAGUS MAGUS is almost identical to PASTA except: Different technique for merging disjoint alignments --- it uses Graph Clustering Merger, which in turn uses the Markov Clustering (MCL). Only does one iteration It s default subset alignment method is MAFFT, just like PASTA
Big challenge: better maximum likelihood method Best methods are RAxML and IQ-TREE 2 FastTree is very fast, sometimes as accurate, but not as robust But can we improve on RAxML? Solution: Disjoint Tree Mergers. First proposed by Erin Molloy. Here we show results using the Guide Tree Merger (Vlad Smirnov)
Disjoint Tree Merger Pipelines Starting Tree: FastTree or IQ-TREE Subset trees: IQ-TREE
Species trees from gene duplication and loss Gene family trees: multiple copies of each species ( MUL-trees ) Most species tree estimation methods cannot run on MUL-trees Options: Figure out orthology Restrict to single copy gene trees Decompose gene family trees into single copy gene trees, and then run preferred summary method (e.g., ASTRAL, ASTRID, etc.) DISCO: developed by James Willson et al., is a decomposition technique (published in Systematic Biology)
Phylogenetic Placement Input: tree T with leaves S in alignment A, and query sequence x Output: tree T on S + {x} that optimizes maximum likelihood Best methods: pplacer (likelihood-based) best accuracy, but slow (and maybe limited scalability) EPA-ng (likelihood-based) not quite as accurate, but very fast for batch processing (and maybe limited scalability) APPLES-2 (distance-based) not as accurate as pplacer, but very very fast
eXtended Range (XR) framework Stage 1 Stage 2 Stage 3
Summary Divide-and-conquer can improve accuracy and scalability, and reduce computational effort Course projects exploring using these divide-and-conquer strategies include: Using GTM with other tree estimation methods (e.g., with distance-based methods, FastTree, etc.) Modifying a divide-and-conquer strategy to further improve accuracy (e.g., modify MAGUS by replacing Markov Clustering (MCL) by another clustering method) Evaluate MAGUS with other subset aligner (e.g., ProbCons, T-Coffee, etc.)












 framework")