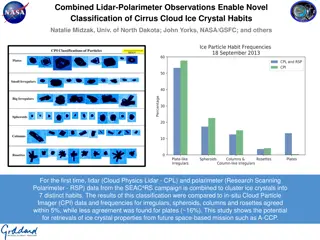
Classification of Lidar Measurements Using Machine Learning Methods
This study focuses on classifying lidar measurements using supervised and unsupervised machine learning methods. By utilizing machine learning, specifically supervised learning, the researchers trained a prediction function to automatically label unlabeled lidar scans. They conducted steps to implement machine learning, selected data from different lidar channels, and evaluated the results. Additionally, the study introduced decision trees and gradient boosting trees as ML algorithms for classification tasks, emphasizing the importance of accurate identification of raw lidar profiles.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
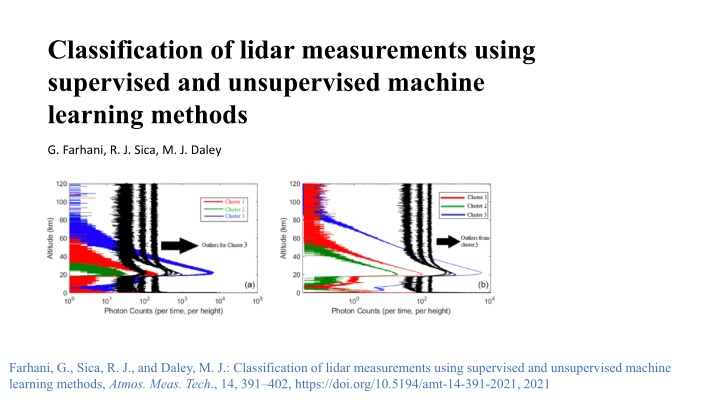
Classification of lidar measurements using supervised and unsupervised machine learning methods G. Farhani, R. J. Sica, M. J. Daley Farhani, G., Sica, R. J., and Daley, M. J.: Classification of lidar measurements using supervised and unsupervised machine learning methods, Atmos. Meas. Tech., 14, 391 402, https://doi.org/10.5194/amt-14-391-2021, 2021
Motivation What s the problem? Correctly identifying raw bad profiles . Why machine learning (ML)? We are not seeking deep understanding of the physics but want identification. What lidar are you using? ML as a data driven approach can be adapted to different lidar systems.
Supervised learning We have a set of scans (x), and we have them labeled (y). We (humans) look at these scans and their labels, and we automatically label the unlabeled scans. We want a machine to Learn a prediction function f ? :? ? where x is vector of features and y is vector of target values 3
Steps we took to implement ML We chose 4500 profiles from the (low Rayleigh) LR, (high Rayleigh) HR, and the nitrogen vibrational Raman channels. Select (enough) labeled data from each class We used 70 % of our data for the training phase and we kept 30 % of data for the test phase. In order to overcome the overfitting issue, we used the k-fold cross-validation technique, in which the data set is divided into k equal subsets. In this work we used 5-fold cross-validation. Choose a model and train Evaluate. Is the result good? 4
Introducing an ML algorithm: decision trees Outlook Temp Windy Play Rainy High False Yes Sunny Normal False Yes x Sunny Low False No Sunny High True No Root Rainy Low True No Rainy High True No 0 1 Sunny Normal True Yes Sunny High False Yes 1 0 1 Using a decision tree, we want to see under what circumstances we can play soccer? 0 0 1 0 1 1 0 1 0 leaf leaf leaf leaf leaf leaf leaf leaf
Gradient Boosting Trees: A sequence of trees. X Train The new tree is built with the goal of reducing the residual In the sequence, each tree is really simple Details on the algorithm is available: Schapire, R. E.: The strength of weak learnability, Machine Learn., 5, 197 227, 1990. a 6
Confusion matrix: an evaluation matric for classification Fig is taken from : Analyzing the Leading Causes of Traffic Fatalities Using XGBoost and Grid-Based Analysis: A City Management Perspective, DOI:10.1109/ACCESS.2019.2946401
Evaluation of our model: HR channel LR channel Nitrogen channel Accuracy: 95% Accuracy: 95% Accuracy: 98%
Unsupervised Approach: Clustering In the unsupervised ML approach, by looking at the similarities between the two profiles and defining a distance scale, similar profiles will be grouped together. All 339 profiles collected by the PCL system LR channel on the night of 15 May 2012.
Detecting anomalies: Profiles for the nitrogen channel for the nights of June 2002 were clustered into four different groups. The small cluster in cyan indicates the group of profiles that do not belong to any of the other clusters.
Summary and conclusion We tested different supervised ML algorithms, among the GBT performed better, with a success rate above 90 % for the PCL system. The unsupervised algorithm can successfully cluster profiles on nights with both consistent and varying lidar profiles due to both atmospheric conditions and system alignment and performance. The unsupervised algorithm has the potential of detecting anomalies in big lidar data sets.
Recommendations for NDACC users We recommend, using machine learning based approaches for parts of data pre-processing. As well as as an approach to identify anomalies in lidar raw data. We used Python Scikit-learn machine learning library for most parts of the machine learning implementation. Thus, there is no need for heavy coding!
Supervised Learning: Attributes for scan number 1: X1 , X2, , Xn-1 Label for scan number 1 X1 1 X21X31 Xn-11 0 1 X1 X2X3 Xn-1 3er455555cccc 2 Attributes for scan number m: X1 , X2, , Xn-1 Label for scan number m 3 X1m X2mX3m Xn-1m Supplementary material 14
Another example for clustering the data: Nitrogen channel for night of May 15 2012 Supplementary material