
Data Cleaning
Data cleaning is the process of fixing or removing incorrect, duplicate, or incomplete data within a dataset. It improves data quality, ensuring accurate and reliable information for decision-making. Learn why data cleaning is necessary and the essential reasons to clean your data.
4 views • 35 slides

HyPoradise: Open Baseline for Generative Speech Recognition
Learn about HyPoradise, a dataset with 334K+ hypotheses-transcription pairs for speech recognition. Discover how large language models are used for error correction in both zero-shot and fine-tuning scenarios.
4 views • 16 slides

Python-Based Model for SQL Injection and Web Application Security
The research focuses on combating SQL injection attacks in web applications using a Python-based neural network model. By training the model on a dataset and conducting blind testing, it achieved up to 81% accuracy in detecting malicious network traffic. This innovative approach aims to enhance cybe
2 views • 10 slides

Veterans Covenant Healthcare Alliance (VCHA) Initiative Overview
The Veterans Covenant Healthcare Alliance (VCHA) is collaborating with the Defence Medical Welfare Service (DMWS) to improve healthcare access and outcomes for the armed forces community. The initiative aims to establish a core reporting dataset, reduce variation, and enhance service quality in line
0 views • 24 slides

Understanding UKMOD: UKHLS Input Data Analysis
UKMOD-UKHLS is a versatile dataset derived from the UK Household Longitudinal Study (UKHLS) for policy years 2010-2019. It aims to provide valuable insights for longitudinal analysis in the UK. The dataset undergoes meticulous processing to align with policy years, address data gaps, and deliver acc
0 views • 12 slides

Understanding Supervised Learning Algorithms and Model Evaluation
Multiple suites of supervised learning algorithms are available for modeling prediction systems using labeled training data for regression or classification tasks. Tuning features can significantly impact model results. The training-testing process involves fitting the model on a training dataset an
3 views • 74 slides

Understanding Pattern Recognition in Data Science
Explore the concept of pattern recognition through chapters on pattern representation, learning objectives, KDD process, and classification. Dive into the Iris dataset and learn how patterns are represented and classified based on their attributes.
6 views • 66 slides

Do Input Gradients Highlight Discriminative Features?
Instance-specific explanations of model predictions through input gradients are explored in this study. The key contributions include a novel evaluation framework, DiffROAR, to assess the impact of input gradient magnitudes on predictions. The study challenges Assumption (A) and delves into feature
0 views • 32 slides
Tracking the Spread of Invasive Spotted Lanternfly: A Project Proposal Presentation
The project aims to monitor and predict the spread of the invasive Spotted Lanternfly in the United States using dataset lydemapr and process-based modeling. The impact of SLF on plant species and outdoor activities is significant, making it crucial to implement proactive measures. Machine learning
0 views • 8 slides

Knowledge Distillation for Streaming ASR Encoder with Non-streaming Layer
The research introduces a novel knowledge distillation (KD) method for transitioning from non-streaming to streaming ASR encoders by incorporating auxiliary non-streaming layers and a special KD loss function. This approach enhances feature extraction, improves robustness to frame misalignment, and
0 views • 34 slides
How Does Movie Reviews Data Scraping Help in Sentiment Analysis (2)
Movie reviews data scraping provides a vast dataset for sentiment analysis, offering insights into audience opinions and reactions effectively.\n\nknow more>>\/\/ \/movie-reviews-data-scraping-help-in-analysis.php\n\n
1 views • 7 slides

Advancements in AI for Neurocognitive Disorders: Proposal for Early Detection of Dementia
This presentation highlights the urgent need for early detection and classification of dementia, a global public health priority. It discusses utilizing machine learning-based diagnostics with real-world brain imaging and genetic data to address Alzheimer's disease and related neurocognitive disorde
3 views • 19 slides

Understanding Frequent Patterns and Association Rules in Data Mining
Frequent pattern mining involves identifying patterns that occur frequently in a dataset, such as itemsets and sequential patterns. These patterns play a crucial role in extracting associations, correlations, and insights from data, aiding decision-making processes like market basket analysis. Minin
1 views • 95 slides

Analyzing Trends in Student Placement for Autism and Intellectual Disability in California
Explore the project's goal of examining trends and factors influencing the placement of students with autism and intellectual disability in California over a 5-year period. Data obtained from the California Department of Education underwent complex data organization to build an analyzable dataset. M
1 views • 24 slides

Understanding Measures of Central Tendency in Statistics
Measures of central tendency, such as mean, median, and mode, provide a way to find the average or central value in a statistical series. These measures help in simplifying data analysis and drawing meaningful conclusions. The arithmetic mean, median, and mode are commonly used to represent the over
0 views • 11 slides

Understanding Measures of Central Tendency in Statistics
Measures of central tendency, such as mean, median, and mode, play a crucial role in statistical analysis by describing the central position in a dataset. Mean represents the average, median is the middlemost value, while mode is the most frequent value. Learn about their significance, calculation m
2 views • 12 slides

Understanding Partition Values in Statistics
Partition values such as quartiles, deciles, and percentiles play a crucial role in dividing a dataset into various segments for analysis. Quartiles split the data into 4 equal parts, deciles into 10 parts, and percentiles into 100 parts. These values help in understanding the distribution of data a
0 views • 7 slides

Korean Peninsula Issues and US National Security Polling Findings
This polling dataset explores various questions related to the Korean Peninsula issues and US national security. It delves into topics such as the stances of the Biden and Moon administrations towards the Kim regime, potential agreements to address North Korea's nuclear issues, success of the Korea
0 views • 16 slides

Setting up and Running Postal Code Conversion File Plus (PCCF+) - Step-by-Step Guide
In this detailed guide prepared by Statistics Canada, you will learn how to set up and run the Postal Code Conversion File Plus (PCCF+). The process involves creating an input file with unique identifiers and postal codes, producing a new dataset, saving it for import, importing the data to SAS, tra
0 views • 21 slides

Coreference Resolution System Architecture and Inference Methods
This research focuses on coreference resolution within the OntoNotes-4.0 dataset, utilizing inference methods such as Best-Link and All-Link strategies. The study investigates the contributions of these methods and the impact of constraints on coreference resolution. Mention detection and system arc
0 views • 18 slides

Active Object Recognition Using Vocabulary Trees: Experiment Details and COIL Dataset Visualizations
This presentation explores active object recognition using vocabulary trees by Natasha Govender, Jonathan Claassens, Philip Torr, Jonathan Warrell, and presented by Manu Agarwal. It delves into various aspects of the experiment, including uniqueness scores, textureness versus uniqueness, and the use
0 views • 49 slides

Machine Learning Techniques: K-Nearest Neighbour, K-fold Cross Validation, and K-Means Clustering
This lecture covers important machine learning techniques such as K-Nearest Neighbour, K-fold Cross Validation, and K-Means Clustering. It delves into the concepts of Nearest Neighbour method, distance measures, similarity measures, dataset classification using the Iris dataset, and practical applic
1 views • 14 slides

Enhancing Image Disease Localization with K-Fold Semi-Supervised Self-Learning Technique
Utilizing a novel self-learning semi-supervised technique with k-fold iterative training for cardiomegaly localization from chest X-ray images showed significant improvement in validation loss and labeled dataset size. The model, based on a VGG-16 backbone, outperformed traditional methods, resultin
0 views • 5 slides

General Medical Imaging Dataset for Two-Stage Transfer Learning
This project aims to provide a comprehensive medical imaging dataset for two-stage transfer learning, facilitating the evaluation of architectures utilizing this approach. Transfer learning in medical imaging involves adapting pre-trained deep learning models for specific diagnostic tasks, enhancing
0 views • 16 slides

Best Practices for Dataset Handling in Machine Learning Projects
Proper dataset handling is crucial in machine learning projects. Use publicly available datasets with train/dev/test splits or create your own. Be cautious of overfitting by utilizing independent validation and test sets. Avoid touching the test set until final evaluation to prevent overfitting. Mai
0 views • 13 slides

Insights from Avengers Dataset
Dataset analysis of Avengers' appearances, gender, status, and years since joining. Obtained from data.world, the dataset consists of 173 records capturing various details about Avengers characters. Methods for examining appearances, gender distribution, status types, and years since joining were ap
0 views • 14 slides

Understanding Measures of Central Tendency in Math
In mathematics, the average, median, mode, and range are essential measures of central tendency used to organize and summarize data for better understanding. The mean refers to the middle value of a dataset without outliers, while the median is the middle number when the data is ordered. The mode re
0 views • 14 slides

WikiQA Dataset: Open-Domain Question Answering Challenges
WikiQA Dataset provides a challenge for open-domain question answering, focusing on identifying answers from large-scale knowledge bases such as Freebase and high-quality text sources like Wikipedia. The dataset includes questions sampled from search engine query logs, with candidate sentences sourc
0 views • 24 slides

Open-Domain Question Answering Dataset WikiQA Overview
This content discusses the WikiQA dataset, a challenge dataset for open-domain question answering. It covers topics such as question answering with knowledge base, answer sentence selection, QA sentence dataset, issues with QA sentence dataset, and WikiQA dataset details. Various aspects of open-dom
0 views • 24 slides

Understanding YouTube Video Trends: Dataset Analysis by Grace Dimmer
Explore the factors influencing YouTube video trends through the analysis of the dataset compiled by Grace Dimmer. The project delves into the challenges, insights, and future possibilities associated with deciphering the dynamics of trending videos on YouTube. From data overview to analysis techniq
0 views • 9 slides

Early Drowsiness Detection Dataset and Baseline Model
This study introduces a realistic dataset and temporal baseline model for early drowsiness detection, addressing the critical issue of drowsy driving that leads to numerous accidents and fatalities each year. By analyzing physiological measurements and human behavior, the research aims to improve de
0 views • 21 slides

Association Between Maternal Education and Maternal Age in GLM Analysis
In this lecture on Generalized Linear Models in R, the focus is on examining the association between maternal education and maternal age using a dataset on births. The process involves creating a factor variable for maternal education levels, filtering a smaller dataset, visualizing the univariate r
0 views • 43 slides

Detecting Performance Anomalies in Cellular Networks via Regression Analysis
The study focuses on detecting performance anomalies in cellular networks using regression analysis. It addresses challenges such as labeling, rare anomalies, and correlated factors. The tool CellPAD is introduced for anomaly detection, supporting various prediction algorithms and offering insights
0 views • 19 slides

Research Progress and Results in Image Dataset Analysis
Research progress and results in image dataset analysis including experiment outcomes, discussion on model performance, dataset analysis, and model training. The study covers topics such as analysis of kiwi leaf trips and spots, model ensemble techniques, teacher-student learning, and the effectiven
0 views • 12 slides
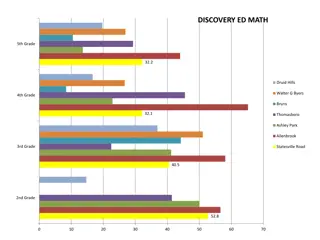
Educational Data Analysis in North Carolina Elementary Schools
This dataset provides comprehensive information about math, reading, and science performance in various elementary schools in North Carolina. It includes data on grades, schools, and composite scores for different subjects. The images associated with the data show detailed breakdowns of performance
0 views • 6 slides

Understanding mean, median, and mode in statistics
In statistics, the mean represents the average value, the median is the middle value that divides a dataset into two halves, and the mode is the most frequent value. This guide explains how to calculate these statistical measures and provides examples. Additionally, it demonstrates how to estimate t
0 views • 11 slides

Multi-class Skin Lesion Segmentation for Cutaneous T-cell Lymphomas
This research focuses on developing a multi-class skin lesion segmentation method specifically for Cutaneous T-cell Lymphomas using high-resolution clinical images. The study introduces a new dataset, a novel method called Multi-Knowledge Learning Network (MKLN), and achieves state-of-the-art result
0 views • 15 slides

World of Warcraft Character Analysis Dataset by Jinyuan Qiu
Explore trends in character levels, classes, and races in World of Warcraft using a dataset collected by Jinyuan Qiu in January 2009. The dataset covers character attributes such as level, race, class, and zone, allowing for analysis of gameplay patterns and common traits among characters.
0 views • 5 slides

Human Activity Recognition from Millimeter-Wave Radar Point Clouds
Accurate human activity recognition (HAR) is crucial for context-aware applications. This study presents a framework utilizing mmWave radar-generated point clouds for HAR, addressing challenges related to privacy and sensors. Different machine learning approaches were evaluated, and a new open-sourc
0 views • 11 slides

From Data Collection to Text Recognition: The OCR Training Dataset Journey
The journey of building an OCR training dataset\u2014from data collection to model training\u2014is essential for creating reliable and efficient text recognition systems. With accurate annotations and stringent quality control, businesses can unlock
1 views • 5 slides