
Language Teaching Techniques: GTM, Direct Method & Audio-Lingual Method
Explore the Grammar-Translation Method, Direct Method, and Audio-Lingual Method in language teaching. Understand principles, objectives, and methodologies with insights into language learning approaches. Enhance teaching skills and foster effective communication in language education.
3 views • 82 slides

Evaluation of DryadLINQ for Scientific Analyses
DryadLINQ was evaluated for scientific analyses in the context of developing and comparing various scientific applications with similar MapReduce implementations. The study aimed to assess the usability of DryadLINQ, create scientific applications utilizing it, and analyze their performance against
0 views • 20 slides

Understanding Apache Spark: Fast, Interactive, Cluster Computing
Apache Spark, developed by Matei Zaharia and team at UC Berkeley, aims to enhance cluster computing by supporting iterative algorithms, interactive data mining, and programmability through integration with Scala. The motivation behind Spark's Resilient Distributed Datasets (RDDs) is to efficiently r
0 views • 41 slides
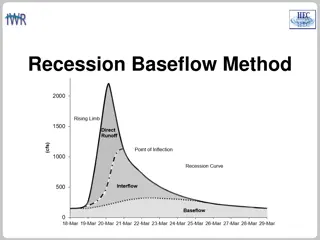
Understanding the Recession Baseflow Method in Hydrology
Recession Baseflow Method is a technique used in hydrology to model hydrographs' recession curve. This method involves parameters like Initial Discharge, Recession Constant, and Threshold for baseflow. By analyzing different recession constants and threshold types such as Ratio to Peak, one can effe
0 views • 8 slides

Understanding the Scientific Method: A Logical Framework for Problem-Solving
The Scientific Method is a systematic approach used to solve problems and seek answers in a logical step-by-step manner. By following key steps such as stating the problem, researching, forming a hypothesis, testing, analyzing data, and drawing conclusions, this method helps clarify uncertainties an
1 views • 18 slides

Introduction to Six Thinking Hats Method for Effective Group Decision Making
Explore the Six Thinking Hats method, a powerful tool for facilitating group discussions and decision-making processes. This method encourages participants to approach problems from various perspectives represented by different colored 'hats'. By simplifying thinking and fostering constructive dialo
1 views • 24 slides

Understanding Corn Growth Stages: Leaf Staging Methods and Considerations
Various leaf staging methods, including the Leaf Collar Method and Droopy Leaf Method, are used to identify corn plant growth stages. The Leaf Collar Method involves counting leaves with visible collars, while the Droopy Leaf Method considers leaves at least 40-50% exposed from the whorl. Factors li
0 views • 9 slides

Understanding Different Emasculation Techniques in Plant Breeding
Learn about the significance of emasculation in plant breeding to prevent self-pollination and facilitate controlled pollination. Explore various methods such as hand emasculation, forced open method, clipping method, emasculation with hot/cold water, alcohol, suction method, chemical emasculation,
2 views • 10 slides

Simple Average Method in Cost Accounting
Simple Average Method, introduced by M. Vijayasekaram, is a technique used for inventory valuation and delivery cost calculation. It involves calculating the average unit cost by multiplying the total unit costs with the number of receiving instances. This method simplifies calculations and reduces
2 views • 5 slides
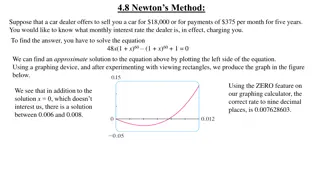
Understanding Newton's Method for Solving Equations
Newton's Method, also known as the Newton-Raphson method, is a powerful tool for approximating roots of equations. By iteratively improving initial guesses using tangent lines, this method converges towards accurate solutions. This method plays a crucial role in modern calculators and computers for
0 views • 12 slides

Understanding MapReduce and Hadoop: Processing Big Data Efficiently
MapReduce is a powerful model for processing massive amounts of data in parallel through distributed systems like Apache Hadoop. This technology, popularized by Google, enables automatic parallelization and fault tolerance, allowing for efficient data processing at scale. Learn about the motivation
2 views • 33 slides

Understanding the Conjugate Beam Method in Structural Analysis
The Conjugate Beam Method is a powerful technique in structural engineering, derived from moment-area theorems and statical procedures. By applying an equivalent load magnitude to the beam, the method allows for the analysis of deflections and rotations in a more straightforward manner. This article
1 views • 11 slides

Understanding Roots of Equations in Engineering: Methods and Techniques
Roots of equations are values of x where f(x) = 0. This chapter explores various techniques to find roots, such as graphical methods, bisection method, false position method, fixed-point iteration, Newton-Raphson method, and secant method. Graphical techniques provide rough estimates, while numerica
0 views • 13 slides

Determination of Dipole Moment in Chemistry
The determination of dipole moment in chemistry involves methods such as the Temperature Method (Vapour Density Method) and Refractivity Method. These methods rely on measuring various parameters like dielectric constants and polarizations at different temperatures to calculate the dipole moment of
1 views • 15 slides

Understanding MapReduce for Large Data Processing
MapReduce is a system designed for distributed processing of large datasets, providing automatic parallelization, fault tolerance, and clean abstraction for programmers. It allows for easy writing of distributed programs with built-in reliability on large clusters. Despite its popularity in the late
0 views • 52 slides

Understanding MapReduce in Distributed Systems
MapReduce is a powerful paradigm that enables distributed processing of large datasets by dividing the workload among multiple machines. It tackles challenges such as scaling, fault tolerance, and parallel processing efficiently. Through a series of operations involving mappers and reducers, MapRedu
7 views • 32 slides

Measurement of Flow Velocity on Frozen and Non-Frozen Slopes of Black Soil Using Leading Edge Method
This study presented a detailed methodology for measuring flow velocity on frozen and non-frozen slopes of black soil, focusing on the Leading Edge method. The significance of shallow water flow velocity in soil erosion processes was emphasized. Various methods for measuring flow velocity were compa
0 views • 23 slides

Cloud-based Geospatial Query Processing Using MapReduce and Voronoi Diagrams
This research paper presents a cloud-based approach for processing geospatial queries efficiently using MapReduce and Voronoi diagrams. The motivation behind the study, related works in the field, preliminary concepts of MapReduce, Voronoi diagram creation, query types, performance evaluation, and f
0 views • 30 slides

Introduction to Apache Pig: A High-level Overview
Apache Pig is a data flow language developed by Yahoo! and is a top-level Apache project that enables non-Java programmers to access and analyze data on a cluster. It interprets Pig Latin commands to generate MapReduce jobs, simplifying data summarization, reporting, and querying tasks. Pig operates
0 views • 57 slides

Understanding High-Level Languages in Hadoop Ecosystem
Explore MapReduce and Hadoop ecosystem through high-level languages like Java, Pig, and Hive. Learn about the levels of abstraction, Apache Pig for data analysis, and Pig Latin commands for interacting with Hadoop clusters in batch and interactive modes.
0 views • 27 slides

Understanding MapReduce System and Theory in CS 345D
Explore the fundamentals of MapReduce in this informative presentation that covers the history, challenges, and benefits of distributed systems like MapReduce/Hadoop, Pig, and Hive. Learn about the lower bounding communication cost model and how it optimizes algorithm for joins on MapReduce. Discove
0 views • 60 slides

Mathematical Modeling for Psychiatric Diagnosis in Big Data Environment
This research project led by Prof. Kazuo Ishii aims to develop a Big Data mining method and optimized algorithms for genomic Big Data, specifically targeting three major mental disorders including depression. The research process involves data analytics, mathematical modeling, and data processing te
0 views • 21 slides

Introduction to Map Reduce Paradigm in Data Science
Explore the MapReduce paradigm in data science through examples, discussions on when to use it, and implementation details. Understand how MapReduce is utilized for processing and generating big data sets efficiently.
0 views • 52 slides

Introduction to MapReduce Paradigm in Data Science
Today's lesson covered the MapReduce paradigm in data science, discussing its principles, use cases, and implementation. MapReduce is a programming model for processing big data sets in a parallel and distributed manner. The session included examples, such as WordCount, and highlighted when to use M
0 views • 48 slides

Data Processing and MapReduce: Concepts and Applications
Exploring concepts of big data processing, data-parallel computation, fault tolerance in MapReduce, generality vs. specialization in systems, and the efficiency of MapReduce for large computations such as web indexing. Understand the role of synchronization barriers, handling partial aggregation, an
0 views • 60 slides

Preliminary Steps in Setting Up a Hadoop Environment
Logging into the VM, changing passwords, transferring files to Hadoop, setting up Rstudio for MapReduce programming, and running the first MapReduce program are essential preliminary steps in establishing a Hadoop environment for data processing tasks.
0 views • 13 slides

Introduction to MapReduce: Efficient Data Processing Technique
Modern data-mining applications require managing immense amounts of data quickly, leveraging parallelism in computing clusters. MapReduce, a programming technique, enables efficient large-scale data calculations on computing clusters, reducing costs compared to special-purpose machines. MapReduce is
0 views • 72 slides

Introduction to Distributed Computing at Stanford University
A meeting at Stanford University's Gates building tonight for those interested in CS341 in the Spring. The session will cover the concept of viewing computation as a recursion on a graph, techniques like Pregel, Giraph, GraphX, and GraphLab for distributed computing, and challenges in data movement
0 views • 18 slides

MapReduce Method for Malware Detection in Parallel Systems
This paper presents a system call analysis method using MapReduce for malware detection at the IEEE 17th International Conference on Parallel and Distributed Systems. It discusses detecting malware behavior, evaluation techniques, categories of malware, and approaches like signature-based and behavi
0 views • 22 slides

Communication Steps for Parallel Query Processing: Insights from MPC Model
Revealing the intricacies of parallel query processing on big data, this content explores various computation models such as MapReduce, MUD, and MRC. It delves into the MPC model in detail, showcasing the tradeoffs between space exponent and computation rounds. The study uncovers lower bounds on spa
0 views • 25 slides

Understanding the Shoe Lace Method for Finding Polygon Areas
The Shoe Lace Method is a mathematical process used to determine the area of any polygon by employing coordinate geometry. By following specific steps, including organizing coordinates, multiplying diagonally, and adding columns in a certain manner, the method allows for a straightforward calculatio
0 views • 8 slides

Introduction to GraphLab: Large-Scale Distributed Analytics Engine
GraphLab is a powerful distributed analytics engine designed for large-scale graph-parallel processing. It offers features like in-memory processing, automatic fault-tolerance, and flexibility in expressing graph algorithms. With characteristics such as high scalability and asynchronous processing,
0 views • 26 slides

Distributed Machine Learning and Graph Processing Overview
Big Data encompasses vast amounts of data from sources like Flickr, Facebook, and YouTube, requiring efficient processing systems. This lecture explores the shift towards using high-level parallel abstractions, such as MapReduce and Hadoop, to design and implement Big Learning systems. Data-parallel
0 views • 61 slides

Fault-Tolerant MapReduce-MPI for HPC Clusters: Enhancing Fault Tolerance in High-Performance Computing
This research discusses the design and implementation of FT-MRMPI for HPC clusters, focusing on fault tolerance and reliability in MapReduce applications. It addresses challenges, presents the fault tolerance model, and highlights the differences in fault tolerance between MapReduce and MPI. The stu
1 views • 25 slides

Introduction to Apache Spark: Simplifying Big Data Analytics
Explore the advantages of Apache Spark over traditional systems like MapReduce for big data analytics. Learn about Resilient Distributed Datasets (RDDs), fault tolerance, and efficient data processing on commodity clusters through coarse-grained transformations. Discover how Spark simplifies batch p
0 views • 17 slides

Introduction to Spark: Lightning-fast Cluster Computing
Apache Spark is a fast and general-purpose cluster computing system that provides high-level APIs in Java, Scala, and Python. It supports a rich set of higher-level tools like Spark SQL for structured data processing and MLlib for machine learning. Spark was developed at UC Berkeley AMPLab in 2009 a
0 views • 100 slides

Overview of Spark SQL: A Revolutionary Approach to Relational Data Processing
Spark SQL revolutionized relational data processing by tightly integrating relational and procedural paradigms through its declarative DataFrame API. It introduced the Catalyst optimizer, making it easier to add data sources and optimization rules. Previous attempts with MapReduce, Pig, Hive, and Dr
0 views • 29 slides

Overview of Cloud Computing Technologies and Business Implications
Explore the concepts, technologies, and business implications of cloud computing through a discussion on multi-core processors, virtualization, cloud service models (IaaS, PaaS, SaaS), data processing models like MapReduce, and real-world case studies. Learn about the evolution of internet computing
0 views • 18 slides

Understanding MapReduce: A Real-World Analogy
MapReduce is a programming model used to process and generate large data sets with parallel and distributed algorithms. In this analogy, the process of depositing, categorizing, and counting coins using a machine illustrates how MapReduce works, where mappers categorize coins and reducers count them
0 views • 43 slides

Development of Log Data Management System for Monitoring Fusion Research Operations
This project focuses on creating a Log Data Management System for monitoring operations related to MDSplus database in fusion research. The system architecture is built on Big Data Technology, incorporating components such as Flume, HDFS, Mapreduce, Kafka, and Spark Streaming. Real-time and offline
0 views • 6 slides