
NCI Data Collections BARPA & BARRA2 Overview
NCI Data Collections BARPA & BARRA2 serve as critical enablers of big data science and analytics in Australia, offering a vast research collection of climate, weather, earth systems, environmental, satellite, and geophysics data. These collections include around 8PB of regional climate simulations a
6 views • 22 slides

Revolutionizing with NLP Based Data Pipeline Tool
The integration of NLP into data pipelines represents a paradigm shift in data engineering, offering companies a powerful tool to reinvent their data workflows and unlock the full potential of their data. By automating data processing tasks, handling diverse data sources, and fostering a data-driven
9 views • 2 slides

Revolutionizing with NLP Based Data Pipeline Tool
The integration of NLP into data pipelines represents a paradigm shift in data engineering, offering companies a powerful tool to reinvent their data workflows and unlock the full potential of their data. By automating data processing tasks, handling diverse data sources, and fostering a data-driven
7 views • 2 slides

Ask On Data for Efficient Data Wrangling in Data Engineering
In today's data-driven world, organizations rely on robust data engineering pipelines to collect, process, and analyze vast amounts of data efficiently. At the heart of these pipelines lies data wrangling, a critical process that involves cleaning, transforming, and preparing raw data for analysis.
2 views • 2 slides

Data Wrangling like Ask On Data Provides Accurate and Reliable Business Intelligence
In current data world, businesses thrive on their ability to harness and interpret vast amounts of data. This data, however, often comes in raw, unstructured forms, riddled with inconsistencies and errors. To transform this chaotic data into meaningful insights, organizations need robust data wrangl
0 views • 2 slides

Know Streamlining Data Migration with Ask On Data
In today's data-driven world, the ability to seamlessly migrate and manage data is essential for businesses striving to stay competitive and agile. Data migration, the process of transferring data from one system to another, can often be a daunting task fraught with challenges such as data loss, com
1 views • 2 slides

Spatial Distortion Correction in EPI Sequences: Field Mapping Examples
Spatial distortion artifacts in EPI sequences (BOLD or DWI) due to slow sampling rates in the phase encoding direction can be corrected using B0/spatial field mapping techniques. This correction requires obtaining field maps under the same B0 shimming conditions and with identical FoV and adjustment
0 views • 4 slides

Understanding Filesystems: A Comprehensive Overview
File systems provide a structured approach to storing and organizing data on secondary storage devices. They involve logical organization of files, directories for grouping related files, sharing data between users, and managing permissions. Files contain data with attributes like size, ownership, a
3 views • 29 slides

Blood Grouping Techniques: Methods and Advantages
Various blood grouping techniques including slide or tile method and microplate technique are discussed. Advantages of microplate ABO grouping such as cost-effectiveness, automation potential, and reduction in errors are highlighted. The use of different manual methods and newer techniques in blood
0 views • 11 slides

Understanding Histograms in Displaying Quantitative Data
Learn how to create and interpret histograms in displaying quantitative data. This lesson covers making histograms, interpreting distributions, and comparing data sets. Understand the importance of grouping data values and creating equal-width intervals for a clearer visualization. Explore the proce
10 views • 16 slides

Understanding Convolutional Codes in Digital Communication
Convolutional codes provide an efficient alternative to linear block coding by grouping data into smaller blocks and encoding them into output bits. These codes are defined by parameters (n, k, L) and realized using a convolutional structure. Generators play a key role in determining the connections
0 views • 19 slides

Understanding Data Governance and Data Analytics in Information Management
Data Governance and Data Analytics play crucial roles in transforming data into knowledge and insights for generating positive impacts on various operational systems. They help bring together disparate datasets to glean valuable insights and wisdom to drive informed decision-making. Managing data ma
0 views • 8 slides

Understanding ABO Blood Grouping and Rh Groups
ABO blood grouping and Rh factor testing are crucial for blood transfusions and forensic medicine. The presence or absence of specific antigens and antibodies in human blood determines blood type. Genetic inheritance from parents establishes blood type, with codominance influencing offspring phenoty
0 views • 13 slides
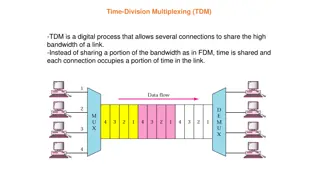
Understanding Time-Division Multiplexing (TDM) in Digital Communication
Time-Division Multiplexing (TDM) is a digital process that enables multiple connections to share the bandwidth of a link by dividing data into time slots. Synchronous TDM organizes data flows into frames with specific time slots for each input connection. Frames are crucial for grouping time slots i
0 views • 9 slides

Understanding Symbolic Interactionism in Sociology
Symbolic Interactionism is a school of thought in sociology that focuses on how individuals interact with each other through symbols, shaping social structures. It highlights the role of symbols in defining actions and meanings in social interactions. The concept explores how different socializing e
0 views • 18 slides

Understanding Pivot Tables: A Comprehensive Guide
Pivot tables are powerful tools for reorganizing and analyzing data efficiently. They help in summarizing, sorting, and grouping data to create meaningful reports quickly. Learn about the advantages of using pivot tables and how to create them effectively.
0 views • 13 slides

Importance of Data Preparation in Data Mining
Data preparation, also known as data pre-processing, is a crucial step in the data mining process. It involves transforming raw data into a clean, structured format that is optimal for analysis. Proper data preparation ensures that the data is accurate, complete, and free of errors, allowing mining
1 views • 37 slides

Enhancing English Classrooms through Flexible Grouping Strategies
Strategies for grouping students in English classrooms are explored, focusing on the benefits of flexible grouping to cater to diverse learner needs. Various grouping methods, such as mixed ability and similar ability groupings, are discussed alongside a lesson example on exploring different aspects
0 views • 32 slides

Understanding Algorithms and Programming: A Visual Introduction
Explore the fundamental concepts of algorithms and programming through visual representations and practical examples. Learn about algorithmic thinking, abstraction, recipe-like algorithms, and the importance of logical steps in accomplishing tasks. Discover how algorithms encapsulate data and instru
1 views • 17 slides

Lazy Learning Classification Using Nearest Neighbors
Lazy Learning Classification Using Nearest Neighbors explores the concept of classifying data by grouping it with similar neighbors. The chapter delves into the characteristics of nearest neighbor classifiers, their applications in various fields, and the suitability of using them based on data comp
0 views • 44 slides
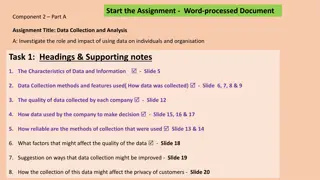
Understanding Data Collection and Analysis for Businesses
Explore the impact and role of data utilization in organizations through the investigation of data collection methods, data quality, decision-making processes, reliability of collection methods, factors affecting data quality, and privacy considerations. Two scenarios are presented: data collection
1 views • 24 slides

Understanding C Structs and Pointers for Data Organization
In C programming, structs allow the grouping of related data values together to create user-defined data types. This enables better organization and manipulation of data within a program. Structs can be initialized, assigned values, and accessed using pointers for efficient data handling.
0 views • 20 slides

Efficient Parameter-free Clustering Using First Neighbor Relations
Clustering is a fundamental pre-Deep Learning Machine Learning method for grouping similar data points. This paper introduces an innovative parameter-free clustering algorithm that eliminates the need for human-assigned parameters, such as the target number of clusters (K). By leveraging first neigh
0 views • 22 slides

Introduction to Apache Pig: A High-level Overview
Apache Pig is a data flow language developed by Yahoo! and is a top-level Apache project that enables non-Java programmers to access and analyze data on a cluster. It interprets Pig Latin commands to generate MapReduce jobs, simplifying data summarization, reporting, and querying tasks. Pig operates
0 views • 57 slides

Understanding Similarity and Distance in Data Mining
Exploring the concepts of similarity and distance in data mining is crucial for tasks like finding similar items, grouping customers, and detecting near-duplicate documents. Metrics like Jaccard similarity help quantify similarities between sets of data objects, enabling effective analysis and decis
0 views • 46 slides

Understanding Data Mining Similarity and Distance Concepts
Data mining involves quantifying the closeness of objects through similarity and distance measures. These measures are crucial for various tasks like recommending similar items, grouping customers, and detecting duplicates in web documents. Similarity metrics ensure objects are ranked correctly base
0 views • 65 slides

Introduction to Data Manipulation in R with dplyr
Explore the essential functions of dplyr for data manipulation in R, focusing on key operations like selecting variables, filtering observations, rearranging rows, summarizing data, adding new variables, and grouping operations. Discover the basic structure of dplyr code to efficiently manipulate an
0 views • 21 slides

Understanding Data Structures in High-Dimensional Space
Explore the concept of clustering data points in high-dimensional spaces with distance measures like Euclidean, Cosine, Jaccard, and edit distance. Discover the challenges of clustering in dimensions beyond 2 and the importance of similarity in grouping objects. Dive into applications such as catalo
0 views • 55 slides
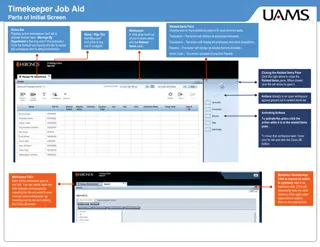
Detailed Guide on Using Timekeeper Job Aid for Efficient Work Management
Explore a comprehensive guide to efficiently navigate and utilize the features of the Timekeeper Job Aid. Learn how to manage workspaces, view timecards, handle exceptions, generate reports, and access timecard data effectively. Discover tips on sorting/grouping options, workspace tabs, and maximizi
0 views • 7 slides

Anonymization Techniques in Data Privacy
Anonymizing data is crucial to safeguard privacy, prevent data breaches, and enable sharing for various use cases, such as statistics, data science, and data release. Techniques like K-anonymity aim to protect individual identities by grouping data into subsets with shared characteristics. However,
0 views • 24 slides

Algebraic Expressions Lesson Overview
This lesson focuses on writing and reading algebraic and written expressions with grouping symbols and less than. Students will learn how to translate expressions containing groupings and less than. The lesson is designed to build on the previous day's lesson and challenge students' thinking. It set
0 views • 25 slides

Understanding SQL Aggregation and Grouping in Database Systems
SQL offers powerful aggregation functions like SUM, AVG, COUNT, MIN, and MAX to perform calculations on column data efficiently. By utilizing DISTINCT and GROUP BY clauses, you can manipulate and organize your data effectively in database systems while handling NULL values appropriately.
0 views • 54 slides

Understanding Clustering Methods for Data Analysis
Clustering methods play a crucial role in data analysis by grouping data points based on similarities. The quality of clustering results depends on similarity measures, implementation, and the method's ability to uncover patterns. Distance functions, cluster quality evaluation, and different approac
0 views • 8 slides

Optimizing Multi-Party Video Conferencing through Server Selection and Topology Control
This paper proposes innovative methods for multi-server placement and topology control in multi-party video conferences. It introduces a three-step procedure to minimize end-to-end delays between client pairs using D-Grouping and convex optimization. The study demonstrates how combining D-Grouping,
0 views • 13 slides

Understanding Data Protection Regulations and Definitions
Learn about the roles of Data Protection Officers (DPOs), the Data Protection Act (DPA) of 2004, key elements of the act, definitions of personal data, examples of personal data categories, and sensitive personal data classifications. Explore how the DPO enforces privacy rights and safeguards person
0 views • 33 slides

Understanding Data Awareness and Legal Considerations
This module delves into various types of data, the sensitivity of different data types, data access, legal aspects, and data classification. Explore aggregate data, microdata, methods of data collection, identifiable, pseudonymised, and anonymised data. Learn to differentiate between individual heal
0 views • 13 slides

Data Grouping and Representation in Statistics
In this set of data examples, a computer game company collects and groups ages of players, while the post office records the weights of letters. The challenges include creating non-overlapping groups for ages and ensuring inclusivity for continuous weight data. The visual representations aid in unde
0 views • 16 slides

Walkthrough: Creating Access Reports with Count Function
Explore the detailed process of generating Access reports using the count function. Learn how to start with the wizard, choose data tables, select fields, apply grouping, sort records, and customize the layout for the desired report look. Follow steps to modify the report in design view and create s
0 views • 19 slides

Enhancing Logical Grouping Mechanisms in Haystack Labs
Formalizing a logical grouping mechanism to standardize practices, promoting extensibility and alignment with existing work in Haystack Labs. Examples illustrate the flexibility and advantage of the system.
0 views • 9 slides

Cluster Analysis: Grouping Elements into Clusters with Similarity Measures
Given a set of elements and a similarity measure, the algorithm aims to group elements into clusters where similar elements are grouped together. Each element is represented as a point in space, and the true number of clusters is unknown. The clustering algorithm is inspired by the behavior of ants
0 views • 15 slides