
Climbing to the Top of the Test Pyramid with Playwright
Playwright, a cross-browser, cross-language, and cross-platform web testing and automation framework, can help you climb to the top of the test pyramid. Automate your E2E testing with ease and eliminate flaky tests using Playwright's powerful features and web-first assertions.
1 views • 42 slides

NNbar Annihilation Detector Mechanical Design Proposal
This proposal outlines the mechanical design considerations for the NNbar Annihilation Detector, highlighting practical concerns and proposed changes to the baseline design. Topics cover the structure support, component weights, installation challenges, and optimizations for improved detector perfor
2 views • 27 slides

Static Optimizations
Explore the fundamental concepts of static optimizations in hardware architecture, focusing on compiler-driven techniques to improve performance and efficiency. Learn how compilers can enhance data locality, reduce unnecessary instructions, and minimize branches executed. Discover strategies such as
0 views • 42 slides

New Drugs and Clinical Edits Overview in MO HealthNet Pharmacy Program
Explore the latest pharmaceutical additions and clinical edits in the MO HealthNet Pharmacy Program for various conditions like Fabry disease, cystic fibrosis, generalized myasthenia gravis, and more. Discover new medications such as Elfabrio, Kalydeco, Rystiggo, and Trikafta along with their indica
1 views • 19 slides

O-RAN Software Community June 2020 Updates
The O-RAN Software Community provides updates on the Cherry Release, Bronze release preparations, key features, use cases, and ongoing collaborative discussions and plans. Topics include E2E use cases, RIC compliance, xAPP development, health checks, infrastructure design, and emulator discussions.
0 views • 11 slides

Understanding Memory Ordering in Programming
Memory ordering in programming is crucial for developers to understand, as it dictates the sequence of memory operations at different levels - source code, program order, and execution order. Compiler optimizations and reordering of memory accesses can impact how code is executed by the processor, e
1 views • 30 slides
Coexistence Challenges and Solutions in 6 GHz Networks
Various submissions address narrowband (NB) coexistence issues in the 6 GHz frequency band, focusing on Enhanced Detect and Avoid (eDAA) mechanisms to ensure harmonious coexistence between Wi-Fi and NB devices. The proposals discuss channel access rules, interference measurements, simulation results
1 views • 14 slides

E2E Test Framework 2.0 Gathering on OSC-RSAC Inputs and MVP Blueprints
This document discusses the gathering of OSC-RSAC inputs on MVP deployment blueprints and requirements for O-RAN Alliance, focusing on enabling deployments and developing critical functions for market needs. It outlines proposed agendas, candidate work items, and fits together various elements of th
2 views • 12 slides

Advisory Committee Meeting Summary for BSPTCL, BGCL & SLDC
The meeting discussed various topics including tariff petitions, business plans, network status, capacity additions, and cost optimizations for BSPTCL, BGCL, and SLDC in Bihar. Tariff projections, revenue requirements, transmission charges, and revenue surpluses were also analyzed and carried forwar
0 views • 23 slides

Efficient Gradient Boosting with LightGBM
Gradient Boosting Decision Tree (GBDT) is a powerful machine learning algorithm known for its efficiency and accuracy. However, handling big data poses challenges due to time-consuming computations. LightGBM introduces optimizations like Gradient-based One-Side Sampling (GOSS) and Exclusive Feature
0 views • 13 slides

Test Strategy and Delivery Squad Coverage Recap
Explore a comprehensive test strategy focusing on delivery squad coverage, E2E test framework utilization, Jira management, integration test gap solutions, and phased approach implementation for feature delivery squads. The strategy emphasizes validation tests, unit testing components, user-friendly
6 views • 8 slides

Optimizing Multi-Scalar Multiplication Techniques
Delve into the world of optimizing multi-scalar multiplication techniques with a focus on improving performance, especially in Zero Knowledge Proofs systems using elliptic curves. Explore algorithmic optimizations like the Bucket Method by Gus Gutowski and learn about the runtime breakdown, motivati
3 views • 52 slides

Proposal for Updating End-to-End Test Smoketests Using Python SDK
Addressing the current scenario and problems encountered in running E2E tests for VNF. Proposals for a 3-stage E2E test setup, including test preparation, vendor and LCM creation, runtime complexities, and cloud region configurations. Suggestions for utilizing SO Openstack and MultiCloud VIM adapter
1 views • 5 slides

Zero Touch Network and Service Management Architecture Overview
Explore the ETSI ZSM ISG's initiative on Zero Touch Network and Service Management, focusing on creating an automated architecture supporting legacy and virtualized networks. Learn about the framework, architecture features, and services offered within the ZSM domain. Dive into E2E service managemen
0 views • 9 slides

Understanding the Difference Between LLVM Profile-Instr-Generate and Profile-Generate Options
The profile-instr-generate and profile-generate options in LLVM instrumentation serve distinct purposes. Profile-instr-generate generates instrumentation based on profiling data during compilation, aiding in performance optimization. In contrast, profile-generate is used to generate a profile based
1 views • 20 slides

Understanding Processor Speculation and Optimization
Dive into the world of processor speculation techniques and optimizations, including compiler and hardware support for speculative execution. Explore how speculation can enhance performance by guessing instruction outcomes and rolling back if needed. Learn about static and dynamic speculation, handl
0 views • 33 slides

DRFx: A Simple and Efficient Memory Model for Concurrent Programming Languages
State-of-the-art memory model DRFx provides a solution for relaxed data race detection, addressing deficiencies of previous models like DRF0. It ensures safety, debuggability, and compiler correctness while permitting optimizations and halting programs before non-sequential consistency behavior.
3 views • 14 slides

Managing Large Graphs on Multi-Cores with Graph Awareness
This research discusses the challenges in managing large graphs on multi-core systems and introduces Grace, an in-memory graph management and processing system with optimizations for graph-specific and multi-core-specific operations. The system keeps the entire graph in memory in smaller parts and p
0 views • 14 slides

Insights into Virtual Memory Management Challenges
Exploring various aspects of virtual memory management, such as TLB misses, page table optimizations, and the role of hashed page tables, shedding light on the evolution and complexities of memory addressing in computing systems.
0 views • 51 slides

Update on ROOT I/O Workshop Efforts and Recent Additions
Efforts dedicated to improving ROOT software include memory management enhancements, caching advancements, and a new post-compile analyzer. Recent additions focus on memory leaks, TTree optimizations, and performance improvements for ROOT-based projects. Progress has been made towards zero-copy I/O
0 views • 11 slides

Introduction to TensorFlow: A Comprehensive Overview
TensorFlow, a popular open-source machine learning framework, offers various execution modes including graph and eager execution. It provides benefits such as distributed training and performance optimizations. The architecture involves assembling computational graphs and executing operations using
0 views • 77 slides

Accelerate AI Performance with DirectML on Intel Hardware by Szymon Marcinkowski
Learn about leveraging DirectML on Intel hardware to boost AI performance, including insights on Windows AI ecosystem, DirectML optimizations, scaling AI models, and tools like Windows ML, ONNX Runtime, and more.
0 views • 17 slides

Distributed Graph Coloring on Multiple GPUs: Advancements in Parallel Computation
This research introduces a groundbreaking distributed memory multi-GPU graph coloring implementation, achieving significant speedups and minimal color increase. The approach enables efficient coloring of large-scale graphs with billions of vertices and edges. Additionally, the study explores the pra
0 views • 22 slides

Architecting DRAM Caches for Low Latency and High Bandwidth
Addressing fundamental latency trade-offs in designing DRAM caches involves considerations such as memory stacking for improved latency and bandwidth, organizing large caches at cache-line granularity to minimize wasted space, and optimizing cache designs to reduce access latency. Challenges include
0 views • 32 slides

EMC FY15Q1 Upgrade Review for GFS System
Upgrade review presented by Mark Iredell on the planned system changes and expected benefits for the Global Forecast System (GFS) in December 2014. Highlights include enhancements to modeling capabilities, forecast accuracy, and system optimizations across various components like analysis, model dyn
0 views • 28 slides

Mix and Match Data Structures for Efficient Algorithms
Discover how to combine basic data structures like arrays, linked lists, and trees to create specialized data structures for various applications. Explore the concept of mix-and-match data structures with multiple organizations to implement efficient algorithms like adjacency lists and matrices for
0 views • 12 slides

A Performance Analysis Framework for GPGPU Applications
This framework, GPUPerf, focuses on identifying potential benefits in GPGPU applications through performance analysis, modeling, and user-friendly metrics. It addresses the challenges programmers face in optimizing GPGPU code, providing guidance on program analysis and performance modeling. The fram
0 views • 26 slides

Practical Implementation of Embedded Shadow Page Tables for Cross-ISA System Virtual Machines
This research focuses on the practical implementation and efficient management of embedded shadow page tables for cross-ISA system virtual machines. It discusses the framework, evaluation, and conclusions regarding system virtualization, particularly addressing memory virtualization overhead and opt
0 views • 33 slides

Innovations in Performance Computing at Carnegie Mellon
Carnegie Mellon University is at the forefront of performance computing innovations, focusing on portable tracking of evolving surfaces, parallel and heterogeneous computing, software evolution, and compiler optimizations. They delve into the slow pace of change in programming languages, popular lib
0 views • 26 slides

Enhancing Wireless Programming Tools for Improved Development Efficiency
The article discusses the challenges faced by wireless researchers in current programming tools, highlighting issues with CPU and FPGA platforms. It explores the need for better tools to address manual optimizations, code portability, and innovation hurdles in wireless programming for modern technol
0 views • 49 slides

Innovations in Wireless PHY Programming for Hardware
Programming software radios is a key aspect of wireless communication research, with recent advancements in PHY/MAC design and the use of SDR platforms like GNURadio and SORA for experimentation. Challenges include FPGA limitations and the need for hardware synthesis platforms like ZIRIA for high-le
0 views • 41 slides
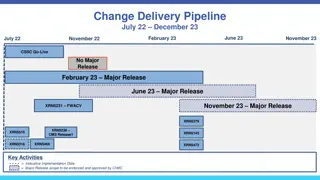
Change Delivery Pipeline Overview
This document outlines the delivery pipeline for change implementation from July 2022 to February 2023, including key activities, target implementation dates, and major releases. It provides details on various proposed changes, their impact, and funding requirements. The pipeline encompasses a range
0 views • 4 slides

Understanding Caches and the Memory Hierarchy in Computer Systems
Delve into the intricacies of memory hierarchy and caches in computer systems, exploring concepts like cache organization, implementation choices, hardware optimizations, and software-managed caches. Discover the significance of memory distance from the CPU, the impact on hardware/software interface
0 views • 84 slides

Advanced Program Optimization Techniques for Efficient Verification and Goal-Directed Search
Explore advanced program optimization techniques targeting program verification and goal-directed search, including deep assertions, inlining-based verifiers, and lazy inlining algorithms. Learn about optimizations that preserve semantics and improve execution/verification time.
0 views • 34 slides

Enhancing Cross-Layer Optimizations in Online Services
Research explores cross-layer optimizations between network and compute in online services to improve efficiency. It delves into challenges such as handling large data, network tail latency, and SLA budgets. The OLS software architecture, time-sensitive responses, and split budget strategies are dis
0 views • 29 slides

Understanding Compiler Optimizations in LLVM: Challenges and Solutions
Compiler optimizations in LLVM, such as loop vectorization, are crucial for enhancing program performance. However, understanding and addressing optimization challenges, like backward dependencies, can be complex. This article explores how LLVM values map to corresponding source-level expressions an
0 views • 41 slides

Superoptimization: Accelerating Code Performance through Conditional Correctness
Explore the concept of superoptimization, a technique to generate optimal code implementations for performance-critical systems. The process involves enumerating all possible programs, transforming them with loops, and proving equivalence with the original code. While optimizations are formally veri
0 views • 22 slides

Time-space Tradeoffs and Optimizations in BKW Algorithm
Time-space tradeoffs and optimizations play a crucial role in the BKW algorithm, particularly in scenarios like learning parity with noise (LPN) and BKW algorithm iterations. The non-heuristic approach in addressing these tradeoffs is discussed in relation to the hardness of the LPN problem and the
0 views • 14 slides

Understanding Atomics and Parallelism in Programming
Explore the world of atomics, parallelism, memory access optimizations, and sequential consistency in programming. Dive into concepts such as races in multithreading, cache optimizations, and the importance of memory access order before and after compiler optimizations. Witness live demos showcasing
0 views • 46 slides

ONE5G: Use Cases for Vertical Industries in 5G Perspective
The ONE5G project focuses on E2E optimizations and advancements for 5G network edge, beyond the initial 3GPP Release 15. It addresses advanced air-interface technologies, aiming to enhance user experience and network operator performance. TWO major scenarios analyzed are Megacities and Underserved A
0 views • 27 slides