Enhancing Cross-Layer Optimizations in Online Services

Research explores cross-layer optimizations between network and compute in online services to improve efficiency. It delves into challenges such as handling large data, network tail latency, and SLA budgets. The OLS software architecture, time-sensitive responses, and split budget strategies are discussed to enhance performance and meet strict deadlines.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Cross Cross- -Layer Optimizations between Layer Optimizations between Network and Compute in Online Network and Compute in Online Services Services Balajee Vamanan
Research Overview Research Overview Networking Packet classification EffiCuts (SIGCOMM 10), TreeCAM (CoNEXT 11) Datacenter networks D2TCP (SIGCOMM 12), FlowBender (CoNEXT 14) Software-defined networking Hydra* Architecture Non-volatile memory MigrantStore* Energy efficiency TimeTrader (MICRO 15) 2
Searching large data is becoming prevalent Searching large data is becoming prevalent Data is growing exponentially Complex, Unstructured Relational Online Search (OLS): Interactively query and access data Key component of many Online Services e.g., Google Search, Facebook, Twitter, advertisements 3
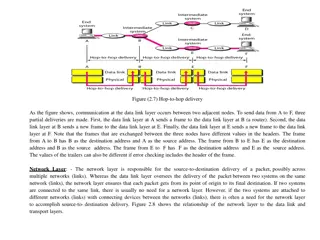
OLS software architecture OLS software architecture Highly distributed and hierarchical Partition-aggregate (tree) Query Query result Request Response Root Request-compute-reply Request: root leaf Compute: leaf node Reply: leaf root Agg m Agg 1 Leaf 1 Leaf n Leaf 1 Leaf n Root waits until deadline to generate overall response Some replies may take longer in network or compute Network queuing TCP retransmissions Imperfect sharding non-uniform compute Long tails tail latency problem 4
OLS OLStail latencies and SLA budgets tail latencies and SLA budgets Missed replies due to tail latency affect quality e.g., SLA of 1% missed replies (deadlines) Time budgets based on 99th %-ile latency of sub-queries 50 To optimize network and compute independently Split budget into network and compute e.g., total = 250 ms flow deadlines 20/30 ms 20 30 50 20 30 50 OLS applications operate under tight network and compute budgets 5
Outline Outline Introduction Background on OLS Challenges and opportunities TimeTrader: key ideas TimeTrader s design Methodology Results 6
Challenge #1: Network tail latency Challenge #1: Network tail latency OLS handles large data high fan-in trees Children respond around same time Incast Incast Packet drops Increase tail latency Hard to absorb in buffers Causes long network tails poor interactivity/quality Network must prioritize based on deadlines 7
Solution #1: D Solution #1: D2 2TCP TCP Deadline-aware datacenter TCP (D2TCP) [SIGCOMM 12] A TCP variant that is optimized for OLS High level idea: During congestion, Near deadline flows: back-off less Far deadline flows: back-off more Achieves distributed earliest-deadline first (EDF) scheduling in the network Evaluated in Google datacenters Not the focus of this talk 8
Challenge #2: Energy management Challenge #2: Energy management Traditional energy management does not work for OLS 1. Interactive, strict service-level agreements (SLAs) Cannot batch 2. Short response times and inter-arrival times (e.g., 200 ms and 1 ms for Web Search) Low-power modes (e.g., p-states) not applicable 3. Shard data over 1000s of servers each query searches all servers Cannot consolidate workload to fewer servers Must carefully slow down (not turn off) servers without violating SLAs 9
Solution #2: TimeTrader Solution #2: TimeTrader TimeTrader [MICRO 15] Idea: Carefully modulate the speed of servers as per eachquery s needs Critical query run at full speed Sub-critical query run at slower speed Learn criticality information from both network and compute Prior work [Pegasus ISCA 14] considers average datacenter load to slow down TimeTrader is the focus of this talk 10
Outline Outline Introduction Background on OLS Challenges and opportunities TimeTrader: key ideas TimeTrader s design Methodology Results 11
TimeTrader: contributions TimeTrader: contributions Each query leads to 1000s of sub-queries Each query s budget set to accommodate 99th %-ile sub-query In both network and compute parts Key observation: 80% sub-queries complete in 20% of budget 1. TimeTrader exploits both network and compute slack to save energy 12
TimeTrader: contributions (cont.) TimeTrader: contributions (cont.) 2. Uses(local) per-sub-query latencies reshapes sub- query response time distribution at all loads Baseline peak load Pegasus (low load) TimeTrader (all load) Baseline low load Fraction of sub-queries Deadline (99% at peak) A B Latency Pegasus s opportunity TimeTrader s opportunity A: median baseline at low load B: 99% baseline at low load 13
TimeTrader: contributions (cont.) TimeTrader: contributions (cont.) 3. Leverages network signals to determine slack Does not need fine-grained clock synchronization 4. Employs Earliest Deadline First (EDF) scheduling Slowing down a sub-query affects other queued sub-queries Critical sub-queries affected the most Allows critical sub-queries to bypass others TimeTrader is the first to explore cross-layer optimization between network and architecture layers; saves 15% - 40% energy at peak - 30% loads 14
Outline Outline Introduction Background on OLS Challenges and opportunities TimeTrader: High level ideas TimeTrader s design Methodology Results 15
TimeTrader: design TimeTrader: design TimeTrader exploits per-sub-query slack Sources of slack Network Request Reply (after compute, unpredictable) Compute Actual compute (query dependent) Queuing (due to local load variations) 1. Determine (a) request slack and (b) compute slack 2. Slow down based on slack and load 3. Shield critical sub-queries from slowed down sub-queries EDF implementation Intel s Running Avg. Power Limit (RAPL) to set power states 16
1(a): Determine request slack 1(a): Determine request slack Requests traverse network from root to leaf Timestamp at parent and leaf? Clock skew slack Estimate based on already-available network signals e.g., Explicit Congestion Notification (ECN) marks, TCP timeouts If a leaf doesn t see either ECN or Timeouts Request Slack = Network Budget Median Latency Else Request Slack = 0 17
1(b): Determine compute 1(b): Determine compute- -queuing slack queuing slack Exploit local load variations in each leaf server Slack calculation Details in the paper Total Slack = Request Slack + Compute-Queuing Slack 18
2: Slow down based on slack 2: Slow down based on slack Given the slack, calculate slow down factor As a fraction of compute budget But not all of the slack can be used Slack calculation assumes no queuing Need to scale slack based on load Slowdown factor = Total Slack * Scale / Compute Budget Scale depends on load Feedback controller (details in the paper) 19
3: Shield critical sub 3: Shield critical sub- -queries queries A sub-critical request could hurt another critical request If critical request is queued behind sub-critical request EDF decouples critical and sub-critical We compute the deadline at the leaf node as follows: Deadline = Compute Budget + Request Slack Key: determining slack enables EDF Implementation details in the paper 20
Outline Outline Introduction Background on OLS Challenges and opportunities TimeTrader: High level ideas TimeTrader s design Methodology Results 21
Methodology Methodology Compute Real measurements for service time, power Network Real measurements at a small scale Tails effects only in large clusters simulate with ns-3 Workload: Web Search (Search) from CloudSuite 2.0 Search index from Wikipedia 3000 queries/s at peak load 90% load Deadline budget: Overall 125 ms Network (request/reply): 25 ms Compute: 75 ms SLA of 1% missed deadlines 22
Idle and Active Energy Savings Idle and Active Energy Savings 45% Energy savings over 40% Idle Active 35% 30% baseline 25% 20% 15% 10% 5% 0% P T P T P T 90% 60% 30% Web search TimeTrader saves 15% - 40% energy over baseline (17% over Pegasus at 30% load) 23
Power state distribution Power state distribution 1.2 GHz 1.5 GHz 1.8 GHz 2.2 GHz 2.5 GHZ 100% 80% Percent of requests 60% 40% 20% 0% P T P T 90% 30% Even at the peak load, TimeTrader slows down about 80% of the time using per-query slack 24
Response time distribution Response time distribution 100% Cumulative percentile of sub-queries 90% 80% 70% 60% 50% Baseline (30%) 40% Baseline (90%) 30% 20% 10% 0% 0 20 40 60 Latency (ms) 80 100 120 140 25
Response time distribution Response time distribution 100% Cumulative percentile of sub-queries 90% 80% 70% 60% Timetrader (90%) Baseline (30%) Baseline (90%) 50% 40% 30% 20% 10% 0% 0 20 40 60 Latency (ms) 80 100 120 140 26
Response time distribution Response time distribution 100% Cumulative percentile of sub-queries 90% 80% 70% 60% Timetrader (90%) 50% Timetrader (30%) 40% Baseline (30%) 30% Baseline (90%) 20% 10% 0% 0 20 40 60 Latency (ms) 80 100 120 140 TimeTrader reshapes distribution at all loads; Slows ~80% of requests at all loads 27
Conclusion Conclusion TimeTrader Exploits sub-query slack Reshapes response time distribution at all loads Saves 15% energy at peak, 40% energy at 30% load Leverages network signals to estimate slack Employs EDF to decouple critical sub-queries from sub- critical sub-queries TimeTrader converts the performance disadvantage of latency tail into an energy advantage! 28
Thank you Thank you Collaborators Jahangir Hasan (Google Inc.) Hamza Bin Sohail (Apple Inc.) T. N. Vijaykumar (Purdue University) Sanjay Rao (Purdue University) Funding Google Faculty Research Awards Questions? 29












")
")


: Determine request slack")
: Determine compute")