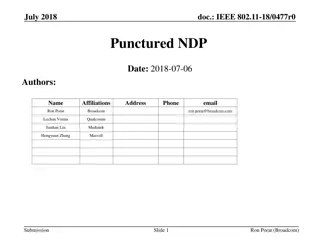
Enhancing Library Data Intelligence with LEADS-4-NDP Program


LEADS-4-NDP
Carly Schanock, Project
Manager

What does LEADS 4 NDP stand
for?
L-
Library and Information
Science (LIS)
E-
Education
A-
and
D-
Data
S-
Science
4-
For
N-
National
D-
Digital
P-
Platform
National Digital Platform: combination of
software applications, social and technical
infrastructure, and staff expertise that
provides content and services to all users in
the United States
What is NDP?
IMPROVING LIBRARY DATA INTELLIGENCE THROUGH THE LEADS PROGRAM
ABOUT LEADS
Carly Schanock; Jane Greenberg; Weimao Ke; Xia Lin; Il-Yeol Song; Jake Williams
Metadata Research Center | Drexel University, College of Computing and Informatics
The LEADS-4-NDP program is supported by Institute of
Library and Museum Services (IMLS) Laura Bush 21st
Century Librarian Program. LEADS-4-NDP, will prepare next
generation LIS faculty so they may meaningfully integrate
data science and LIS education. This program gathers PhD
students from across the United States and they then are
partnered with a NDP site. These fellows and a mentor at
their NDP site work together on a project. Some NDP sites
include the Digital Public Library of America (DPLA), the
OCLC, and University of Pennsylvania. Besides an in-person
boot camp that takes place at the beginning of summer, the
10 week fellowship is done completely virtually
Homepage:
https://cci.drexel.edu/mrc/research/leads/
Project Outcomes
QUAD Slide
•
At the end of the
fellowship, fellows were
asked to create a
"QUAD"slide which
required them to share 1)
Description, 2) Objectives,
3) Outcomes, and 4)
Visualizations
My LEAD's experience
•
Maintain 3 listservs: Mentors, Advisory Board, and
Fellows. And facilitate communication amongst them
and the PIs
•
Create a blackboard shell for the educational boot
camp and the schedule. Also attended the camp
•
Design in HTML and maintain a wordpress site
hosted on the Drexel CCI website
•
Help write reports on the program
•
Attended International Data Week in Botswana,
Africa in November 2018
Changes for 2019/2020
Microsoft may join as a partner
New cohort of fellows
New PI (Erjia Yan)
Leaving position and training a new project manager
The LEADS-4-NDP program, supported by IMLS, aims to integrate data science into LIS education. PhD students from across the US collaborate with NDP sites like DPLA and OCLC on projects. Activities include metadata enhancement, keyword assignment, data pipeline development, and visualization creation to improve library services and access to historic data.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Carly Schanock, Project Manager
L- Library and Information Science (LIS) E- Education A- and D- Data S- Science 4- For N- National D- Digital P- Platform What is NDP? National Digital Platform: combination of software applications, social and technical infrastructure, and staff expertise that provides content and services to all users in the United States
IMPROVING LIBRARY DATA INTELLIGENCE THROUGH THE LEADS PROGRAM Carly Schanock; Jane Greenberg; Weimao Ke; Xia Lin; Il-Yeol Song; Jake Williams Metadata Research Center | Drexel University, College of Computing and Informatics ABOUT LEADS The LEADS-4-NDP program is supported by Institute of Library and Museum Services (IMLS) Laura Bush 21st Century Librarian Program. LEADS-4-NDP, will prepare next generation LIS faculty so they may meaningfully integrate data science and LIS education. This program gathers PhD students from across the United States and they then are partnered with a NDP site. These fellows and a mentor at their NDP site work together on a project. Some NDP sites include the Digital Public Library of America (DPLA), the OCLC, and University of Pennsylvania. Besides an in-person boot camp that takes place at the beginning of summer, the 10 week fellowship is done completely virtually Homepage: https://cci.drexel.edu/mrc/research/leads/
Project Outcomes Project/Host Making a Metadata Meritocracy / California Digital Library, University of California,Office of the President Project Outcome Cleaned Yamz code to be PEP8 and Flake8 compliant Verified installation documentation for several environments Investigated standalone gunicorn deployment Explored federal records using ElasticSearch Extracted dates from known date fields using regular expressions Built machine learning pipeline with DateMatcher ( ) annotation Content-based Learning on Temporal Materials / Digital Curation Innovation Center (DCIC), University of Maryland s iSchool DPLA Resources and Vocabulary Enrichment for Analytics/ Digital Public Library of America (DPLA) Semi-automatically Assigning Keywords to Medieval Manuscripts on OPenn / Digital Research Services, University Penn Libraries Data Informed Decision Making In The 21st Century Library /Free Library of Philadelphia Supports controlled vocabulary use and currency detection Leverages existing controlled vocabularies Enables optimal application of semantic networks Data pipeline written in R CSVs to map keywords to target files Visualization created of data shared between departments (including data format and flow of information) Narrative / analysis of potential next steps A D3-generated map using sample data that displays students connected to a school with modern street map and rollover A plan for modernizing and geocoding historical addresses for entire dataset Enhancing Access to Historic Biographical Data Through Visualization Tools / Historical Society of Pennsylvania Created a gold standard data with a Kappa value of 0.96 between annotators; Using a k-NN classifier and a selection of features, predicted the publisher clusters with 97% accuracy; ISBN prefix was not one of the most important features; and Stopword removal did not have any significant effect on the results. Automatic Identification of Publisher Entities to Support Discovery and Navigation / OCLC Assessment and recommendations NER and visualization prototype Annotated test corpus Connections made for possible collaboration and citizen science Used R to: bypass TEI tags in XML files; run code through multiple Excel sheets; eliminate NULLS; intersect 4 lists of entry terms to determine which terms appear in all 4 editions of the encyclopedia; create TXT files for each entry Ran sample TXT files through HIVE to generate automatic indexing results Identified challenges & next steps for optimizing RAKE algorithm parameters & addition of historical controlled vocabularies to HIVE Mining Geo-references from Biodiversity Literature, Smithsonian Libraries Language and User Navigation / Temple University
QUAD Slide At the end of the fellowship, fellows were asked to create a "QUAD"slide which required them to share 1) Description, 2) Objectives, 3) Outcomes, and 4) Visualizations
Maintain 3 listservs: Mentors, Advisory Board, and Fellows. And facilitate communication amongst them and the PIs Create a blackboard shell for the educational boot camp and the schedule. Also attended the camp Design in HTML and maintain a wordpress site hosted on the Drexel CCI website Help write reports on the program Attended International Data Week in Botswana, Africa in November 2018
Microsoft may join as a partner New cohort of fellows New PI (Erjia Yan) Leaving position and training a new project manager