Understanding Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks
Explore the Set Transformer framework that introduces advanced methods for handling set-input problems and achieving permutation invariance in neural networks. The framework utilizes self-attention mechanisms and pooling architectures to encode features and transform sets efficiently, offering insights into tasks like 3D shape recognition and sequence ordering.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
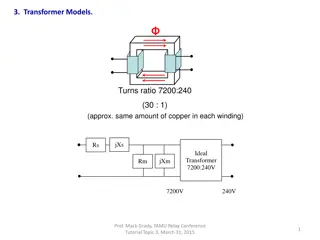
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks Ki-Ryum Moon 2023.04.28 RTOS Lab Department of Computer Science Kyonggi University
Introduction Set-input problem Set-input problem Multiple instance learning . (instance) , . , 3D shape recognition, sequence ordering( ) . 3D shape recognition 2
Introduction Set-input problem Set-input problem . (permutation invariant) . . . (ex. Feed forward network, RNN, etc) 3
Introduction Set-input problem , Set pooling neural network 2017 . (Edwards & Storkey (2017) and Zaheer et al. (2017)) Set . feature space embedding , , pooling . embedding vector ( ) . , set , . 4
Introduction Set-input problem , set . , . pooling . 5
Introduction Transformer set structure data . Set Transformer . self-attention , set . self-attention , . 6
Background about set transformer Pooling Architecture for Sets (permutation invariance) . , set embedding pooling network . pool , ?,? . 7
Background about set transformer Pooling Architecture for Sets Set transformer . ? ??? encoder , ?(???? decoder . ) Encoding feature Decoder 8
Background about set transformer Pooling Architecture for Sets layer encoder . 9
Set Transformer Set Transformer MAB(Multi Head Attention Block) X,Y multi head Attention . X,Y , . 10
Set Transformer Set Transformer SAB(Set Attention Block) MAB Set X Attention . X . , SAB Encoding . 11
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (1) , SAB . ?(?2), . Induced points vector . set X . Ex) ViT CLS TOKEN . 12
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (2) . (X) (H) . , ISAB , X Feature Query patch . 13
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (3) , 2D Amortized Clustering . 2D induced points Encoder X embedding embedding Induced points , . 14
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (4) ISAB m(m << m) n Attention , ? ?? . permutation equivariant . 15
Set Transformer Set Transformer Pooling by Multi head Attention (1) Permutation invariant (aggregation) or . Set transformer k muti head attention . Z . 16
Set Transformer Set Transformer Pooling by Multi head Attention (2) PMA k item . , k = 1 . , k amortized clustering k . k (cluster) SAB . 17
Set Transformer Set Transformer Overall Architecture (1) Encoder, decoder set transformer . 18
Experiments Max regression task 19
Experiments Meta clustering 20
Conclusion Encoding feature aggregation attention . . 21