Overview of Synthetic Models in Transcriptional Data Analysis

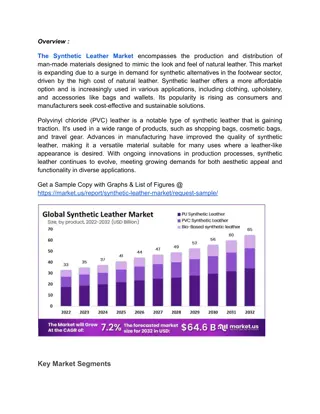
This content showcases various synthetic models for analyzing transcriptome data, including integrative models, trait prediction, and deep Boltzmann machines. It explores the generation of synthetic transcriptome data and the training processes involved in these models. The use of Restricted Boltzmann Machines and Deep Boltzmann Machines for data analysis and prediction is detailed. Additionally, the content discusses error rates in prediction and imputation tasks, providing insights into the evaluation of model performance in transcriptional data analysis.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Synthetic/CMC testing of Integrative model JW, 11/08/17 1
Generating synthetic transcriptome data (Model 1) Trait (1) Modules (10 X 3) Enhancers (5) Genes (10) SNPs (10) 2
Generating synthetic transcriptome data (Model 2) Trait (1) Modules (4 X 1) Genes (10) SNPs (10) 3
Restricted Boltzmann Machine Hidden Units Visible Units 4
Restricted Boltzmann Machine Training by Contrastive Divergence Model stats Data stats h_1 h_0 v_1 v_0 5
Trait prediction from Model 1 data from transcriptome Prediction Error (training) Prediction Error (testing) Reconstruction Error 0.6 0.5 1400 0.48 1300 0.55 0.46 1200 0.44 1100 0.5 0.42 1000 0.45 0.4 900 800 0.38 0.4 700 0.36 600 0.34 0.35 500 0.32 0.3 400 0.3 0 100 200 300 400 500 600 700 800 900 1000 0 100 200 300 400 500 600 700 800 900 1000 0 100 200 300 400 500 600 700 800 900 1000 Training epoch 6
Trait prediction and imputation from Model 2 data 0.54 x axis = Training epoch 0.56 0.54 0.52 Prediction Error Prediction Error 0.52 0.5 0.5 (training) 0.48 (testing) 0.48 0.46 0.46 0.44 0.44 0.42 0.42 0.4 0.4 0.38 0.38 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 0.54 0.58 0.53 0.56 Imputation Error Imputation Error 0.52 0.54 0.51 (training) (testing) 0.52 0.5 0.49 0.5 0.48 0.48 0.47 0.46 0.46 7 0.45 0.44 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500
Deep Boltzmann Machine Class Indicator Model: Hidden Units (2) Hidden Units (1) Visible Units 8
Deep Boltzmann Machine Trait Model: ? ?,??,??;?,? 1 ?(?,?)exp( ? ?,??,??;?,? ) Modules (2) = Modules (1) Transcriptome Genome 9
Deep Boltzmann Machine Training First, use Restricted Boltzmann Machine training, first on layers (v,h_1), and then on layers (h_1,h_2) to initialize weights (Contrastive Divergence) Then, do joint training of all weights, using a combination of mean- field and persistent MCMC to evaluate expected statistics for gradient Back-propagation can be run as a final step to optimize weights for a discriminative classifier (i.e. trait prediction) 10
Deep Boltzmann machine training on synthetic data Reconstruction Error Prediction Error (training) Prediction Error (testing) 340 0.45 0.48 0.4 335 0.47 0.35 330 0.46 0.3 Model 1 325 0.45 0.25 0.2 320 0.44 0.15 315 0.43 0.1 310 0.42 0.05 305 0 0.41 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 414 0.35 0.49 412 0.3 410 0.485 0.25 408 Model 2 406 0.48 0.2 404 0.15 402 0.475 400 0.1 398 0.47 0.05 396 394 0 0.465 0 100 200 Training epoch 300 400 500 600 700 800 900 1000 0 100 200 300 400 500 600 700 800 900 1000 0 100 200 300 400 500 600 700 800 900 1000 11 Training epoch Training epoch
RBM, CMC data, SCZ vs Control Prediction Error (training) Prediction Error (testing) Reconstruction Error 104 6.5 0.55 0.52 6 0.5 0.5 5.5 0.48 0.45 5 0.46 0.4 4.5 0.44 0.35 4 0.42 0.3 3.5 0.4 0.25 3 0.38 0.2 2.5 0.36 2 0.15 0.34 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 Training epoch 12
DBM, CMC data, SCZ vs Control Prediction Error (training) Prediction Error (testing) Reconstruction Error 104 1.87 0.45 0.46 1.86 0.4 0.45 1.85 0.35 0.44 1.84 0.3 0.43 1.83 0.25 0.42 1.82 0.2 0.41 1.81 0.15 0.4 1.8 0.1 0.39 1.79 1.78 0.05 0.38 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 0 50 100 150 200 250 300 350 400 450 500 Training epoch 13
To incorporate: Known modules Imputation / eQTLs GRN connectivity PEER normalized input data Enhancer / cQTL data Backpropagation fine-tuning Other conditions / traits (Autism, Bipolar, Male/Female) 14

")
")