ExTensor: An Accelerator for Sparse Tensor Algebra


E
x
T
e
n
s
o
r
:
A
n
A
c
c
e
l
e
r
a
t
o
r
f
o
r
S
p
a
r
s
e
T
e
n
s
o
r
A
l
g
e
b
r
a
K
a
r
t
i
k
H
e
g
d
e
1
,
H
a
d
i
A
s
g
h
a
r
i
-
M
o
g
h
a
d
d
a
m
1
,
M
i
c
h
a
e
l
P
e
l
l
a
u
e
r
2
,
N
e
a
l
C
r
a
g
o
2
,
A
a
m
e
r
J
a
l
e
e
l
2
,
E
d
g
a
r
S
o
l
o
m
o
n
i
k
1
,
J
o
e
l
E
m
e
r
2
,
3
,
C
h
r
i
s
t
o
p
h
e
r
W
.
F
l
e
t
c
h
e
r
1
1
UIUC
2
NVIDIA
3
MIT





T
e
n
s
o
r
A
l
g
e
b
r
a
•
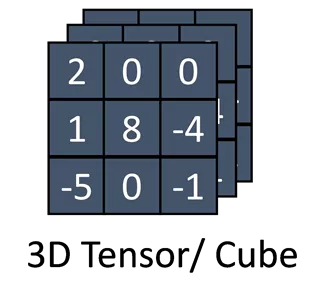
Tensor
is a multidimensional array
•
0D: Scalar
•
1D: Vector
•
2D: Matrix
•
3D or higher: …
•
Tensor algebra
kernels
are series of binary
operations between tensors
•
E.g., Matrix multiplication
2





Overview

Hierarchical Intersection

Hardware Intersection

Architecture

Evaluation
C
h
a
l
l
e
n
g
e
s
a
n
d
O
p
p
o
r
t
u
n
i
t
i
e
s
3
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
Problem domains are in
[dense … hyper-sparse]
E
x
T
e
n
s
o
r
C
o
n
t
r
i
b
u
t
i
o
n
s
•
ExTensor
: The first accelerator for sparse tensor algebra
•
Key Idea:
Hierarchical Intersection
Removing operations by exploiting sparsity
•
Novel intersection algorithm and hardware design
4
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
I
n
t
e
r
s
e
c
t
i
o
n
O
p
p
o
r
t
u
n
i
t
i
e
s
K
e
y
I
d
e
a
•
Basic Opportunity: x * 0 = 0 for all x
•
Skipping ineffectual operations
•
Case 1: x is a scalar
•
Case 2: x is a tile/tensor
•
Case 3: x is an un-evaluated tensor
x
*
0
=
0
6
Overview
Hierarchical Intersection
Hardware Implementation
Architecture
Evaluation
Savings
Reduce storage
Eliminate compute
Coordinates
O
p
p
o
r
t
u
n
i
t
i
e
s
f
r
o
m
E
x
p
l
o
i
t
i
n
g
S
p
a
r
s
i
t
y
1
.
S
c
a
l
a
r
I
n
t
e
r
s
e
c
t
i
o
n
Example: Inner product (A B)
+
Eliminate data fetches
7
Overview
Hierarchical Intersection
Hardware Implementation
Architecture
Evaluation
Reduce storage
Eliminate compute
Example: Sparse Matrix Multiply (A x B)
Savings
A
B
O
p
p
o
r
t
u
n
i
t
i
e
s
f
r
o
m
E
x
p
l
o
i
t
i
n
g
S
p
a
r
s
i
t
y
2
.
T
i
l
e
/
T
e
n
s
o
r
I
n
t
e
r
s
e
c
t
i
o
n
+
Eliminate data fetches
+
Eliminate metadata fetches
8
Overview
Hierarchical Intersection
Hardware Implementation
Architecture
Evaluation
Row
Coordinate
Column
Coordinate
Reduce storage
Eliminate compute
Suppose B = C x D
Savings
O
p
p
o
r
t
u
n
i
t
i
e
s
f
r
o
m
E
x
p
l
o
i
t
i
n
g
S
p
a
r
s
i
t
y
3
.
U
n
e
v
a
l
u
a
t
e
d
T
e
n
s
e
r
Example: Sampled Dense Matrix Multiply (A (C x D))
+
Eliminate data fetches
+
Eliminate metadata fetches
+
Eliminate sub-tensor kernels
9
Overview
Hierarchical Intersection
Hardware Implementation
Architecture
Evaluation
T
a
k
e
a
w
a
y
Opportunities are all intersections between
sets of coordinates
10
0
2
Coordinate
H
a
r
d
w
a
r
e
f
o
r
O
p
t
i
m
i
z
e
d
I
n
t
e
r
s
e
c
t
i
o
n
S
c
a
n
n
e
r
:
P
r
o
d
u
c
i
n
g
C
o
o
r
d
i
n
a
t
e
S
t
r
e
a
m
12
0
2
0
Scanner
0
0
2
2
Coordinate
A
I
n
t
e
r
s
e
c
t
i
o
n
U
n
i
t
:
I
n
t
e
r
s
e
c
t
C
o
o
r
d
i
n
a
t
e
S
t
r
e
a
m
s
Scanner
B
Scanner
A
Control
Intersect
•
Scanners produce streams of
coordinates
•
Intersect unit finds matching
coordinates
1
5
6
7
8
2
3
4
5
9
5
1
5
6
Coordinates:
A
7
8
2
3
4
Coordinates:
B
5
9
13
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
Current intersection time:
9 cycles
Theoretical lower-bound time:
1 common coordinate -> 1 cycle
S
k
i
p
-
B
a
s
e
d
I
n
t
e
r
s
e
c
t
i
o
n
:
O
p
t
i
m
i
z
e
d
D
e
s
i
g
n
Observation:
•
Consecutive coordinates can be
interpreted as a
range
of ineffectual
coordinates in other stream
Coordinates:
A
2
3
4
5
9
1
5
6
7
8
B
2
3
4
5
9
(5,9)
1
5
6
7
8
(1,5)
Solution:
•
Iterate both A and B.
•
Propagate
Skip(begin, end)
signals all-to-all
•
Skip() jumps stream ahead in its iteration
14
5
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
E
x
t
e
n
s
o
r
:
A
c
c
e
l
e
r
a
t
o
r
b
a
s
e
d
o
n
H
i
e
r
a
r
c
h
i
c
a
l
I
n
t
e
r
s
e
c
t
i
o
n
E
x
T
e
n
s
o
r
A
r
c
h
i
t
e
c
t
u
r
e
DRAM
Last Level Buffer
(LLB)
Two levels of buffering
•
Last Level Buffer (LLB)
•
PE buffer
Scanners
•
Dataflow
•
Tensor kernel
•
Representation
16
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
E
v
a
l
u
a
t
i
o
n
M
e
t
h
o
d
o
l
o
g
y
•
Evaluations are based on Cycle-
accurate Simulation
•
Datasets:
•
FROSTT Tensors
•
Florida Sparse Matrices
•
Kernels Evaluated:
•
SpMSpM
•
TTV/TTM
•
SDDMM
Experimental Setup:
iso memory/DRAM-bandwidth
18
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
P
e
r
f
o
r
m
a
n
c
e
F
o
r
S
p
M
S
p
M
Sparse matrixes x sparse matrix (SpMSpM)
•
3.4x ↑
(up-to
6.2x ↑
)
faster than CPU (Intel MKL)
•
3.1x ↑
higher bandwidth utilization
•
Skip-based intersection unit is
3x
↑
faster than no-skip
Performance
Relative to CPU
Roofline Analysis
3.4x
↑
Roofline
Analysis
19
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
•
TTV (3D-Tensor Times Vector)
•
TTM (3D-Tensor Times Matrix)
•
SDDMM (Sampled dense-dense matrix multiplication)
2.8x
↑
24.9x
↑
2.7x
↑
P
e
r
f
o
r
m
a
n
c
e
F
o
r
H
i
g
h
e
r
-
O
r
d
e
r
T
e
n
s
o
r
s
2.8x
↑
24.9x
↑
2.7x
↑
20
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
C
o
n
c
l
u
s
i
o
n
•
Sparse Tensor Algebra is growing in importance across domains
•
Variety of kernels featuring a range of sparsity
•
ExTensor is:
•
A programmable accelerator for Sparse Tensor Algebra
•
Based on
hierarchical intersection
to eliminate ineffectual work
•
Demonstrated significant speed-up over state-of-the-art approaches
•
SpMSpM:
3.4x ↑
over CPU
21
Overview
Hierarchical Intersection
Hardware Intersection
Architecture
Evaluation
Questions
22
B
a
c
k
u
p
S
l
i
d
e
s
Cutting-edge accelerator designed for sparse tensor algebra operations. It introduces hierarchical intersection architecture for efficient handling of sparse tensor kernels, unlocking potential in diverse domains like deep learning, computational chemistry, and more."

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
ExTensor ExTensor: An Accelerator for Sparse : An Accelerator for Sparse Tensor Algebra Tensor Algebra Kartik Hegde1, Hadi Jaleel2, Edgar Solomonik1, Joel Emer2,3, Christopher W. Fletcher1 Moghaddam1 1, Michael Pellauer2, Neal Crago2, Aamer Hadi Asghari Asghari- -Moghaddam 1UIUC 2NVIDIA 3MIT
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Tensor Algebra Tensor Algebra 9 1 0 -5 3 2 1D Tensor/ vector Tensor is a multidimensional array 0D: Scalar 1D: Vector 2D: Matrix 3D or higher: 0D Tensor/ Scalar 2 0 0 1 8 -4 -5 0 -1 -5 0 -1 -5 0 -1 2 0 0 1 8 -4 1 8 -4 2 0 0 1 8 -4 -5 0 -1 2 0 0 2D Tensor/ Matrix 3D Tensor/ Cube Tensor algebra kernelsare series of binary operations between tensors E.g., Matrix multiplication 5D Tensor 4D Tensor 2
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Challenges and Opportunities Challenges and Opportunities Inner Product Problem domains are in [dense hyper-sparse] Matrix multiplication is not the only kernel Challenges GEMV MTTKRP TTM GEMM Convolution Efficient handling regardless of the density Efficient processing of all tensor algebra kernels Opportunities TTV SDDMM Internet & Social media Circuit Simulation Recommendation systems Computational Chemistry Problems in Statistics Deep Learning Density: (log scale) 10-4% >10-6% 1% 10-2% 100% 3
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation ExTensor ExTensor Contributions Contributions ExTensor: The first accelerator for sparse tensor algebra Key Idea: Hierarchical Intersection Removing operations by exploiting sparsity Novel intersection algorithm and hardware design 4
Intersection Opportunities Intersection Opportunities
Overview Hierarchical Intersection Hardware Implementation Architecture Evaluation Key Idea Key Idea Basic Opportunity: x * 0 = 0 for all x Skipping ineffectual operations x 0 0 = * Matrix A Case 1: x is a scalar Case 2: x is a tile/tensor X is a tile X is a scalar Case 3: x is an un-evaluated tensor X is a tensor 6
Overview Hierarchical Intersection Hardware Implementation Architecture Evaluation Opportunities from Exploiting Sparsity Opportunities from Exploiting Sparsity 1. Scalar Intersection 1. Scalar Intersection Example: Inner product (A B) Savings A B Coordinates Reduce storage Eliminate compute + Eliminate data fetches Coordinate 0 1 2 3 0 0 a 0 b 0 0 1 A 0 2 2 3 2 3 a b c d B 0 0 c d Opportunities exploited by other sparse accelerators (e.g., EIE, SCNN) Only perform J x b 2 c 2 ExTensor 7
Overview Hierarchical Intersection Hardware Implementation Architecture Evaluation Opportunities from Exploiting Sparsity Opportunities from Exploiting Sparsity 2. Tile/Tensor Intersection 2. Tile/Tensor Intersection Example: Sparse Matrix Multiply (A x B) Savings 0 1 A B 0 a Reduce storage Eliminate compute + Eliminate data fetches + Eliminate metadata fetches Row A Coordinate 0 0 1 c d Column Coordinate 0 1 0 0 1 1 0 1 0 1 0 e f a c d e f B 1 8
Overview Hierarchical Intersection Hardware Implementation Architecture Evaluation Opportunities from Exploiting Sparsity Opportunities from Exploiting Sparsity 3. Unevaluated Tenser 3. Unevaluated Tenser Example: Sampled Dense Matrix Multiply (A (C x D)) Savings Reduce storage Eliminate compute + Eliminate data fetches + Eliminate metadata fetches + Eliminate sub-tensor kernels A B 0 1 2 3 0 0 a 0 b 0 A 0 2 0 1 2 3 a b ? ? ? ? Suppose B = C x D 9
Takeaway Takeaway Opportunities are all intersections between sets of coordinates Coordinate 0 2 10
Hardware for Optimized Intersection Hardware for Optimized Intersection
Scanner: Scanner: Producing Coordinate Stream Producing Coordinate Stream A 0 2 0 Coordinate 0 2 Scanner 2 0 12
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Intersection Unit: Intersection Unit: Intersect Coordinate Streams Intersect Coordinate Streams Scanners produce streams of coordinates A Control Coordinates: 1 5 6 7 8 9 Intersect unit finds matching coordinates 8 5 7 B 4 6 Scanner A Scanner B 3 5 Coordinates: 2 3 4 5 9 2 1 Current intersection time: 9 cycles Theoretical lower-bound time: 1 common coordinate -> 1 cycle Intersect 5 13
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Skip Skip- -Based Intersection: Based Intersection: Optimized Design Optimized Design Observation: Consecutive coordinates can be interpreted as a range of ineffectual coordinates in other stream Control A 1 8 5 6 7 8 9 7 5 Coordinates: Scanner A Scanner B 6 4 2 3 4 5 9 5 3 1 2 B Solution: Iterate both A and B. Propagate Skip(begin, end) signals all-to-all Skip() jumps stream ahead in its iteration Intersect (1,5) (5,9) 5 14
Extensor: Accelerator based on Extensor: Accelerator based on Hierarchical Intersection Hierarchical Intersection
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation ExTensor ExTensor Architecture Architecture Efficient Intersection at: Savings from Intersection: Two levels of buffering Last Level Buffer (LLB) PE buffer DRAM Skip loading L1 tile data+metadata DRAM -> LLB Scanners Last Level Buffer (LLB) LLB (L2) Scanners Dataflow Tensor kernel Representation Skip loading L1 tile data Scanners LLB -> PE PEs: PE buffer datapath PE Array Scanner + PE Buffers (L1) x Skip compute PE level & | buffer 16
Evaluation Evaluation
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Methodology Methodology Evaluations are based on Cycle- accurate Simulation Parameter ExTensor CPU (Xeon E5- 2687W v4) Num Cores 128 PEs 12C/24T Datasets: FROSTT Tensors Florida Sparse Matrices Frequency 1 GHz 3 GHz (3.5GHz Turbo) DRAM Bandwidth 68.256 GB/s 68.256 GB/s On-chip Buffer 30MB 30MB Kernels Evaluated: SpMSpM TTV/TTM SDDMM Experimental Setup: iso memory/DRAM-bandwidth 18
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Performance For Performance For SpMSpM SpMSpM Sparse matrixes x sparse matrix (SpMSpM) 3.4x (up-to 6.2x ) faster than CPU (Intel MKL) 3.1x higher bandwidth utilization Skip-based intersection unit is 3x faster than no-skip 8 Speed-up Over CPU MKL ExTensor-No-Skip ExTensor-Skip 6 Performance Relative to CPU 4 3.4x 2 0 geomean Roofline Analysis Roofline Analysis 19
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Performance For Higher Performance For Higher- -Order Tensors Order Tensors TTV (3D-Tensor Times Vector) TTM (3D-Tensor Times Matrix) SDDMM (Sampled dense-dense matrix multiplication) 2.8x 24.9x 2.7x 2.8x 24.9x 2.7x 20
Overview Hierarchical Intersection Hardware Intersection Architecture Evaluation Conclusion Conclusion Sparse Tensor Algebra is growing in importance across domains Variety of kernels featuring a range of sparsity ExTensor is: A programmable accelerator for Sparse Tensor Algebra Based on hierarchical intersection to eliminate ineffectual work Demonstrated significant speed-up over state-of-the-art approaches SpMSpM: 3.4x over CPU 21
Questions 22
Backup Slides Backup Slides












































