Accelerator Integration Trends and Solutions
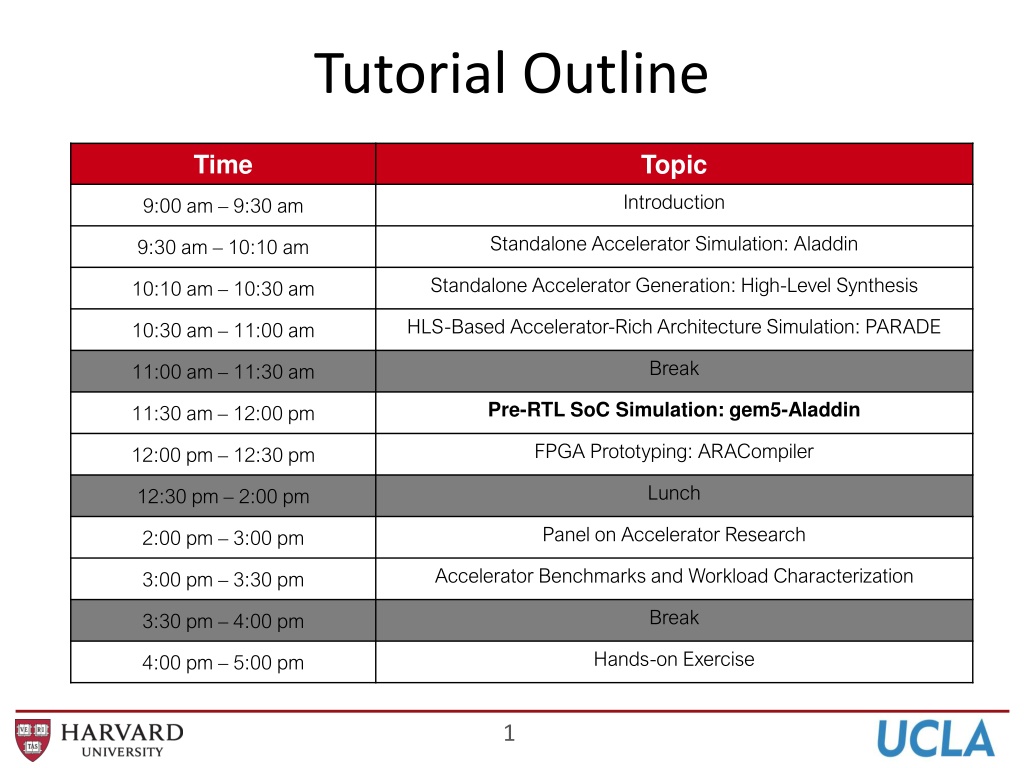




Tutorial Outline
1

Integration for Heterogeneous SoC Modeling
Yakun Sophia Shao, Sam Xi,
Gu-Yeon Wei, David Brooks
Harvard University



2
Accelerator-CPU Integration:
Today’s Conventional SoCs
3
•
Easy to integrate lots of IP, simple accelerator
design
•
Hard to program and share data
Accelerator Integration Trend
•
Users design application-specific hardware accelerators.
•
System vendors provide Host Service Layer with virtual
memory and cache coherence support
–
Intel QuickAssist QPI-Based FPGA Accelerator Platform (QAP)
–
IBM POWER8’s Coherent Accelerator Processor Interface
(CAPI)
4
Core
L2 $
…
L3 $
Core
L2 $
Acc
Agent
Host Service Layer
Accelerator
Main CPU/SoC
FPGA or user-defined ASIC
•
Example of state-of-the-art:
–
IBM POWER8’s Coherent Accelerator
Processor Interface (CAPI)
•
Virtual Addressing & Data Caching
•
Easier, Natural Programming Model
5
IBM CAPI: Two part solution
•
Coherent Accelerator Processor Proxy (CAPP)
–
Snoops PowerBus on behalf of accelerator
•
Power Service Layer (PSL)
–
Performs address translations, page table walker support
–
Provides cache and interface logic
IBM CAPI: Two part solution
Core
Core
L2 $
L2 $
On-Chip Coherent PowerBus
Memory
CAPP
Accelerator
…
PCIe
PSL
Cache
TLB
…
L3 $
6
But… accelerators are
not one size fits all
•
Problem: PSL layer consumes
~20-30% of FPGA resources…
for one accelerator
•
Applications have drastically
different requirements.
•
Memory design customization
is often
more important
than
datapath customization
7
gem5-Aladdin Integration
CPU
DMA
Engine
Scratch
pad
TLB
DRAM
LLC
Cache
Cache
Acc Datapath
8
Code example: Sift
void
imsmooth(F2D* array,
float
sigma, F2D* product);
void
sift() {…
imsmooth(I, temp, gss[0]);
mapArrayToAccelerator(imsmooth, “array”, (
void
*)I,
sizeof
(I));
mapArrayToAccelerator(imsmooth, “product”, (
void
*)product,
sizeof
(product));
invokeAcceleratorAndBlock(imsmooth);
…
}
9
Code example: Sift
void
imsmooth(F2D* array,
float
sigma, F2D* product);
void
sift() {…
// imsmooth(I, temp, gss[0]);
mapArrayToAccelerator
(imsmooth, “array”, (
void
*)I,
sizeof
(I));
mapArrayToAccelerator
(imsmooth, “product”, (
void
*)product,
sizeof
(product));
invokeAccelerator
(imsmooth);
…
}
S
t
a
r
t
A
l
a
d
d
i
n
S
i
m
u
l
a
t
i
o
n
10
Simulating Accelerator with Memory
System using Aladdin
11
Acc
Cache
Memory
Acc
Cache
Memory
CPU
Cache
Memory
12
Modeling Accelerators in an
SoC-like Environment
Acc
Core
Cache
Memory
13
Acc
Core
Cache
Memory
Modeling Accelerators in an
SoC-like Environment
14
Aladdin
gem5-Aladdin
FPGA
Prototyping
Modeling
High-Level Synthesis
PARADE
Accelerator Research Infrastructure
15
Standalone
System Integration
RTL
Tutorial References
•
Y.S. Shao and D. Brooks, “ISA-Independent Workload Characterization and its
Implications for Specialized Architectures,” ISPASS’13.
•
B. Reagen, Y.S. Shao, G.-Y. Wei, D. Brooks, “Quantifying Acceleration:
Power/Performance Trade-Offs of Application Kernels in Hardware,” ISLPED’13.
•
Y.S. Shao, B. Reagen, G.-Y. Wei, D. Brooks, “Aladdin: A Pre-RTL, Power-Performance
Accelerator Simulator Enabling Large Design Space Exploration of Customized
Architectures,” ISCA’14.
•
B. Reagen, B. Adolf, Y.S. Shao, G.-Y. Wei, D. Brooks, “MachSuite: Benchmarks for
Accelerator Design and Customized Architectures,” IISWC’14.
16
Amortize optimization phase
Please do not distribute
GYW
This tutorial outlines various aspects of accelerator integration in modern computing systems, including standalone accelerator simulations, high-level synthesis, FPGA prototyping, and system-on-chip modeling. It explores trends in hardware acceleration, integration challenges, and state-of-the-art solutions like IBM's CAPI technology. The session covers topics such as heterogeneous SoC modeling, accelerator-CPU integration in conventional SoCs, and the current landscape of application-specific hardware accelerators. Attendees will gain insights into optimizing hardware acceleration for efficient computing.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
You are allowed to download the files provided on this website for personal or commercial use, subject to the condition that they are used lawfully. All files are the property of their respective owners.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author.
E N D
Presentation Transcript
Tutorial Outline Time Topic Introduction 9:00 am 9:30 am Standalone Accelerator Simulation: Aladdin 9:30 am 10:10 am Standalone Accelerator Generation: High-Level Synthesis 10:10 am 10:30 am HLS-Based Accelerator-Rich Architecture Simulation: PARADE 10:30 am 11:00 am Break 11:00 am 11:30 am Pre-RTL SoC Simulation: gem5-Aladdin 11:30 am 12:00 pm FPGA Prototyping: ARACompiler 12:00 pm 12:30 pm Lunch 12:30 pm 2:00 pm Panel on Accelerator Research 2:00 pm 3:00 pm Accelerator Benchmarks and Workload Characterization 3:00 pm 3:30 pm Break 3:30 pm 4:00 pm Hands-on Exercise 4:00 pm 5:00 pm 1
Integration for Heterogeneous SoC Modeling Yakun Sophia Shao, Sam Xi, Gu-Yeon Wei, David Brooks Harvard University 2
Accelerator-CPU Integration: Today s Conventional SoCs Easy to integrate lots of IP, simple accelerator design Hard to program and share data Core L2 $ Core L2 $ Acc #1 Acc #n Scratchpad Scratchpad L3 $ On-Chip System Bus DMA 3
Accelerator Integration Trend Users design application-specific hardware accelerators. System vendors provide Host Service Layer with virtual memory and cache coherence support Intel QuickAssist QPI-Based FPGA Accelerator Platform (QAP) IBM POWER8 s Coherent Accelerator Processor Interface (CAPI) Main CPU/SoC FPGA or user-defined ASIC Core L2 $ Core L2 $ Accelerator Acc Agent Host Service Layer L3 $ 4
IBM CAPI: Two part solution Example of state-of-the-art: IBM POWER8 s Coherent Accelerator Processor Interface (CAPI) Virtual Addressing & Data Caching Easier, Natural Programming Model 5
IBM CAPI: Two part solution Coherent Accelerator Processor Proxy (CAPP) Snoops PowerBus on behalf of accelerator Power Service Layer (PSL) Performs address translations, page table walker support Provides cache and interface logic Core L2 $ Core L2 $ Accelerator PCIe PSL CAPP L3 $ On-Chip Coherent PowerBus Cache TLB Memory 6
But accelerators are not one size fits all Problem: PSL layer consumes ~20-30% of FPGA resources for one accelerator Applications have drastically different requirements. Memory design customization is often more important than datapath customization 7
gem5-Aladdin Integration Acc Datapath CPU TLB Scratch pad DMA Engine Cache Cache LLC DRAM 8
Code example: Sift void imsmooth(F2D* array, float sigma, F2D* product); void sift() { imsmooth(I, temp, gss[0]); mapArrayToAccelerator(imsmooth, array , (void *)I, sizeof(I)); mapArrayToAccelerator(imsmooth, product , (void *)product, sizeof(product)); invokeAcceleratorAndBlock(imsmooth); } 9
Code example: Sift void imsmooth(F2D* array, float sigma, F2D* product); void sift() { // imsmooth(I, temp, gss[0]); mapArrayToAccelerator(imsmooth, array , (void *)I, sizeof(I)); mapArrayToAccelerator(imsmooth, product , (void *)product, sizeof(product)); Start Aladdin Start Aladdin Simulation Simulation invokeAccelerator(imsmooth); } 10
Simulating Accelerator with Memory System using Aladdin Acc Cache Memory 11
Acc Cache Memory CPU Cache Memory 12
Modeling Accelerators in an SoC-like Environment Acc Core Core Cache Memory 160 160 block=16 block=16 block=32 140 140 120 120 Without Memory Contention Without Memory Contention Power (mW) Power (mW) 100 100 80 80 60 60 40 40 20 20 0 0 0 0 0.5 0.5 1.0 1.5 1.5 2.0 2.0 2.5 2.5 3.0 3.0 1.0 Time (Million Cycles) Time (Million Cycles) 13
Modeling Accelerators in an SoC-like Environment Acc Core Cache Memory 160 block=16 block=32 140 120 With Memory Contention Power (mW) 100 80 60 40 20 0 0 0.5 1.0 Time (Million Cycles) 1.5 2.0 2.5 3.0 14
Accelerator Research Infrastructure System Integration Standalone Modeling Aladdin gem5-Aladdin High-Level Synthesis PARADE RTL Prototyping FPGA 15
Tutorial References Y.S. Shao and D. Brooks, ISA-Independent Workload Characterization and its Implications for Specialized Architectures, ISPASS 13. B. Reagen, Y.S. Shao, G.-Y. Wei, D. Brooks, Quantifying Acceleration: Power/Performance Trade-Offs of Application Kernels in Hardware, ISLPED 13. Y.S. Shao, B. Reagen, G.-Y. Wei, D. Brooks, Aladdin: A Pre-RTL, Power-Performance Accelerator Simulator Enabling Large Design Space Exploration of Customized Architectures, ISCA 14. B. Reagen, B. Adolf, Y.S. Shao, G.-Y. Wei, D. Brooks, MachSuite: Benchmarks for Accelerator Design and Customized Architectures, IISWC 14. 16





































