
fMRI Coregistration and Spatial Normalization Methods
fMRI data analysis involves coregistration and spatial normalization to align functional and structural images, reduce variability, and prepare data for statistical analysis. Coregistration aligns images from different modalities within subjects, while spatial normalization achieves precise anatomic
3 views • 35 slides

Coregistration and Spatial Normalization in fMRI Analysis
Coregistration and Spatial Normalization are essential steps in fMRI data preprocessing to ensure accurate alignment of functional and structural images for further analysis. Coregistration involves aligning images from different modalities within the same individual, while spatial normalization aim
6 views • 42 slides

Progress Update on Demographic Accounts Project for June 2022 Delivery
The update covers the progress of the Demographic Accounts project, including proof-of-concept milestones, annual local authority level estimations, model approaches, and data preprocessing. The project aims to deliver demographic accounts by age, sex, and local authority, incorporating data from va
0 views • 15 slides

Comprehensive Guide to Data Cleaning and Preprocessing Techniques
Understanding the crucial concepts of data cleaning such as Garbage In, Garbage Out principle (GIGO), Non-Linear and Geographic data inspection, handling NaN values, feature scaling, PCA, correlations, and more. Explore the steps involved in cleaning and preprocessing data for data science and machi
0 views • 12 slides

Developing Agricultural Simulation System Using Data Mining Techniques
Development of an agricultural simulation system involves identifying data sources, collecting and integrating data, preprocessing, applying data mining techniques, developing simulation models, calibration, validation, and optimization for performance. User interface development and deployment are
0 views • 4 slides

Text Analytics and Machine Learning System Overview
The course covers a range of topics including clustering, text summarization, named entity recognition, sentiment analysis, and recommender systems. The system architecture involves Kibana logs, user recommendations, storage, preprocessing, and various modules for processing text data. The clusterin
0 views • 54 slides

Wavelet-based Scaleograms and CNN for Anomaly Detection in Nuclear Reactors
This study utilizes wavelet-based scaleograms and a convolutional neural network (CNN) for anomaly detection in nuclear reactors. By analyzing neutron flux signals from in-core and ex-core sensors, the proposed methodology aims to identify perturbations such as fuel assembly vibrations, synchronized
3 views • 11 slides

Searching for Nearest Neighbors and Aggregate Distances in Plane Algorithms
This overview discusses different algorithms related to nearest neighbor searching and aggregate distances in the plane. It covers concepts like aggregate-max, group nearest neighbor searching, applications in meeting location optimization, and previous heuristic algorithm work. Results include prep
0 views • 25 slides

Finite Element Analysis Using Abaqus: Basics and Methods
Learn about the basics and methods of Finite Element Analysis using Abaqus. Explore topics such as preprocessing, interactive mode, analysis input files, components modeling, FEM modeling, and more. Understand the advantages and disadvantages of using GUI versus Python scripting, and how to create F
0 views • 33 slides

Understanding Text Representation and Mining in Business Intelligence and Analytics
Text representation and mining play a crucial role in Business Intelligence and Analytics. Dealing with text data, understanding why text is difficult, and the importance of text preprocessing are key aspects covered in this session. Learn about the goals of text representation, the concept of Bag o
0 views • 27 slides

Overview of Compiler Technology and Related Terminology
Compiler technology involves software that translates high-level language programs into lower-level languages, such as machine or assembly language. It also covers decompilers, assemblers, interpreters, linkers, loaders, language rewriters, and preprocessing steps used in compilation. Understanding
0 views • 29 slides

Understanding Automated Speech Recognition Technologies
Explore the world of Automated Speech Recognition (ASR), including setup, basics, observations, preprocessing, language modeling, acoustic modeling, and Hidden Markov Models. Learn about the process of converting speech signals into transcriptions, the importance of language modeling in ASR accuracy
0 views • 28 slides

Faster Algorithms for Distance Sensitivity Oracles
Hanlin Ren and Yong Gu from the University of Oxford presented faster algorithms for Distance Sensitivity Oracles (DSOs), a well-studied problem in graph algorithms. They discussed previous work, techniques like bootstrapping and hitting sets, and their innovative results with improved preprocessing
0 views • 17 slides

Divide-and-Conquer Algorithm for Two-Point Shortest Path Queries in Polygonal Domains
In this research presented at SoCG 2019, a new divide-and-conquer algorithm is proposed for efficiently handling two-point shortest path queries in polygonal domains. The algorithm offers significant improvements in preprocessing space and query time compared to previous methods, making it a valuabl
1 views • 19 slides
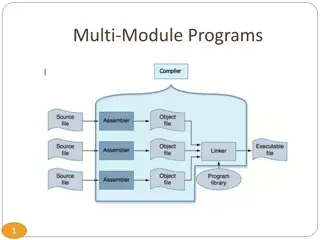
Understanding Multi-Module Programming in C: Modularizing, Compiling, and External Variables
Learn how to enhance your C programs by modularizing code into smaller modules, compiling multiple files, and managing external variables for better structure and organization. Dive into the details of preprocessing, assembling, linking, and declaring global variables in separate files.
0 views • 14 slides

Enhancing Machine Learning Algorithms with Heterogeneous Computing
Team 5 is working on expanding a prior initiative by developing code to simultaneously run three different machine learning algorithms - Preprocessing, Blink Detection, and Eye Tracking. Their project involves implementing these algorithms on a Xilinx Kria evaluation board using process and memory i
0 views • 6 slides

PySAT Point Spectra Tool: Spectral Analysis and Regression Software
PySAT is a Python-based spectral analysis tool designed for point spectra processing and regression tasks. It offers various features such as preprocessing, data manipulation, multivariate regression, K-fold cross-validation, plotting capabilities, and more. The tool's modular interface allows users
0 views • 6 slides

Authorship Verification and Identification through Stylometry Analysis
Utilizing methods like word frequency clustering and machine learning classifiers, this project aims to verify authorship and determine the writers of various texts by renowned authors such as Charles Dickens, George Eliot, and William Makepeace Thackeray. By analyzing writing samples and employing
0 views • 25 slides

An Overview of Data Mining in Financial Applications with Ninja Trader
This presentation delves into the utilization of data mining techniques in financial applications, particularly with Ninja Trader software. It covers the motivation behind using data mining in financial scenarios, the nature of financial data, dataset analysis approaches, trading rules generation, a
0 views • 9 slides

Data Processing and Preprocessing Summary
In this document, Aymeric Sauvageon from CEA/DRF/Irfu/DAp presents a detailed overview of the preprocessing steps involved in data processing from L0 to L1. It covers the definition of L0/L1 and coding, utilization of the database for processing, input file specifications from China, packet content
0 views • 11 slides

Data Preprocessing Techniques in Python
This article covers various data preprocessing techniques in Python, including standardization, normalization, missing value replacement, resampling, discretization, feature selection, and dimensionality reduction using PCA. It also explores Python packages and tools for data mining, such as Scikit-
0 views • 14 slides

Importance of Data Preprocessing in Real-World Data Analysis
Data preprocessing is essential due to the inherent dirtiness of real-world data, such as incompleteness, noisiness, and inconsistencies. This process involves cleaning, integration, transformation, and reduction of data to ensure quality for effective data mining and decision-making. The need arise
0 views • 46 slides

Data Preprocessing: Enhancing Data Quality for Effective Knowledge Discovery
Data preprocessing is crucial for preparing raw data in real-world applications, ensuring consistency, completeness, and accuracy. It involves steps like data cleaning, dealing with missing values, and smoothing out noise to improve the quality of data for better decision-making and knowledge discov
0 views • 35 slides
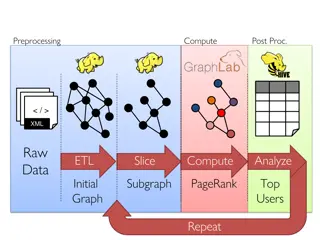
Data Processing and Analysis for Graph-Based Algorithms
This content delves into the preprocessing, computing, post-processing, and analysis of raw XML data for graph-based algorithms. It covers topics such as data ETL, graph analytics, PageRank computation, and identifying top users. Various tools and frameworks like GraphX, Spark, Giraph, and GraphLab
0 views • 8 slides

Weak Visibility Queries of Line Segments in Simple Polygons - Overview
This information discusses weak visibility queries of line segments in simple polygons, focusing on topics such as visibility of line segments, visibility polygons, visibility graphs, and related previous work on preprocessing and data structures for visibility queries in simple polygons.
0 views • 26 slides

Task-Aware Materialization for Fast Data Analytics at University of Wisconsin-Madison
Data-driven pipelines play a crucial role in modern applications, and optimizing common tasks can significantly speed up these pipelines. The talk at University of Wisconsin-Madison explores smart materialization algorithms and data structures to enhance the performance of data analytics application
1 views • 20 slides

Enhancing Arabic Sentiment Analysis Using Fuzzy Logic Approach
Presenter Mariam Biltawi from Princess Sumaya University for Technology in Jordan discusses a research project on enhancing automatic polarity classification of Arabic text using a lexicon-based approach with fuzzy logic. The project utilizes a large-scale Arabic book reviews dataset and a sentiment
1 views • 30 slides

Comprehensive Guide to Elasticsearch Indexing and Retrieval
Learn how to index, retrieve, and preprocess content with Elasticsearch. Explore techniques such as crawling with Heritrix, accessing Kibana, defining text preprocessing, testing Lucene analyzers, using file system (FS) crawler for indexing, and configuring FS crawler for efficient data ingestion in
0 views • 10 slides

Spiking Neural Network with Fixed Synaptic Weights for Classification
This study presents a spiking neural network with fixed synaptic weights based on logistic maps for a classification task. The model incorporates a leaky integrate-and-fire neuron model and explores the use of logistic maps in synaptic weight initialization. The work aims to investigate the effectiv
0 views • 8 slides