
Balanced Graph Edge Partition and Its Practical Applications
Balanced graph edge partitioning is a crucial problem in graph computation, machine learning, and graph databases. It involves partitioning a graph's vertices or edges into balanced components while minimizing cut costs. This process is essential for various real-world applications such as iterative
4 views • 17 slides

Analyzing Big Graphs with Pregelix Dataflow Engine
Explore how Pregelix on a dataflow engine enables efficient processing of large graphs, providing insights on its system architecture, experimental results, and related work in graph analytics. Understand Pregel semantics, programming model, APIs, and graph mutations for effective analysis of big da
1 views • 38 slides

Query-Centric Framework for Big Graph Querying
A comprehensive exploration of Google's Pregel system, outlining its design, programming interfaces, vertex partitioning, vertex states, and practical examples like Breadth-First Search. The framework provides insights into large-scale graph processing by thinking like a vertex and leveraging messag
0 views • 30 slides

Introduction to Distributed Computing at Stanford University
A meeting at Stanford University's Gates building tonight for those interested in CS341 in the Spring. The session will cover the concept of viewing computation as a recursion on a graph, techniques like Pregel, Giraph, GraphX, and GraphLab for distributed computing, and challenges in data movement
0 views • 18 slides

Introduction to Google's Pregel Distributed Analytics Framework
Google's Pregel is a large-scale graph-parallel distributed analytics framework designed for graph processing tasks. It offers high scalability, fault tolerance, and flexibility in expressing graph algorithms. Inspired by the Bulk Synchronous Parallel (BSP) model, Pregel operates in super-steps, ena
0 views • 38 slides

Introduction to GraphLab: Large-Scale Distributed Analytics Engine
GraphLab is a powerful distributed analytics engine designed for large-scale graph-parallel processing. It offers features like in-memory processing, automatic fault-tolerance, and flexibility in expressing graph algorithms. With characteristics such as high scalability and asynchronous processing,
1 views • 26 slides

Introduction to Spark: Lightning-Fast Cluster Computing
Spark is a parallel computing system developed at UC Berkeley that aims to provide lightning-fast cluster computing capabilities. It offers a high-level API in Scala and supports in-memory execution, making it efficient for data analytics tasks. With a focus on scalability and ease of deployment, Sp
0 views • 17 slides
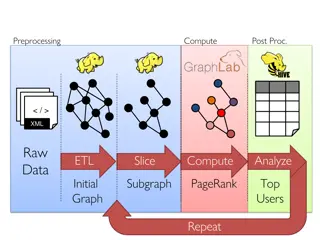
Data Processing and Analysis for Graph-Based Algorithms
This content delves into the preprocessing, computing, post-processing, and analysis of raw XML data for graph-based algorithms. It covers topics such as data ETL, graph analytics, PageRank computation, and identifying top users. Various tools and frameworks like GraphX, Spark, Giraph, and GraphLab
0 views • 8 slides

Overview of Pregel, a Large-Scale Distributed Analytics Framework
Pregel is a powerful distributed analytics framework designed for large-scale graph processing. It offers high scalability, fault tolerance, and flexibility in expressing graph algorithms through a message-passing programming model. Inspired by the Bulk Synchronous Parallel model, Pregel operates in
0 views • 15 slides

Pregel Algorithms for Graph Connectivity Problems
This comprehensive work explores Pregel algorithms for graph connectivity problems with performance guarantees. Covering topics such as large-scale graph analytics, distributed graph processing systems, iterative computing, and vertex state management, this study delves into practical applications a
0 views • 35 slides

Pregel: A System for Large-Scale Graph Processing
Learn about Pregel, a system designed to tackle large-scale graph processing challenges by providing scalability, fault-tolerance, and flexibility for implementing various graph algorithms efficiently.
0 views • 76 slides