
Transforming Scientific Data Standardization with Large Language Models (LLMs)
Large Language Models (LLMs) to standardize scientific data, including data format standardization, automatic extraction of metadata, data annotation, data quality assessment, data cleaning, and documentation.
2 views • 5 slides

Evaluating Gender Bias in BERTi: Insights on Large Language Models
This study delves into gender bias evaluation in BERTi, a large language model trained on South Slavic data. It explores issues in language modeling, the impact of social biases in artificial intelligence, and training processes of Large Language Models (LLMs). Additionally, it discusses how LLMs le
11 views • 16 slides

The Large Lakes Observatory and The Science of Freshwater Inland Seas
The Large Lakes Observatory (LLO) at the University of Minnesota Duluth is a leading academic program focused on limnology, oceanography, and research dedicated to inland seas. LLO's unique focus on oceanographic research methods applied to large lakes worldwide is supported by the Blue Heron resear
9 views • 28 slides

Ask On Data for Efficient Data Wrangling in Data Engineering
In today's data-driven world, organizations rely on robust data engineering pipelines to collect, process, and analyze vast amounts of data efficiently. At the heart of these pipelines lies data wrangling, a critical process that involves cleaning, transforming, and preparing raw data for analysis.
2 views • 2 slides

Data Wrangling like Ask On Data Provides Accurate and Reliable Business Intelligence
In current data world, businesses thrive on their ability to harness and interpret vast amounts of data. This data, however, often comes in raw, unstructured forms, riddled with inconsistencies and errors. To transform this chaotic data into meaningful insights, organizations need robust data wrangl
0 views • 2 slides

Understanding Computational Linguistics and Natural Language Processing
Explore the fascinating fields of Computational Linguistics and Natural Language Processing (NLP), delving into their development, applications, and significance. Learn about the study of human languages in computational models, the importance of corpora in linguistic research, and the various types
1 views • 33 slides

Understanding English Parts of Speech and Tagging
English Parts of Speech and Tagging involve analyzing syntactic functions and semantic types of words in a sentence. This process assigns POS tags to each word based on its role in the sentence, such as nouns, verbs, adjectives, adverbs, prepositions, determiners, pronouns, and conjunctions. The dis
4 views • 43 slides

Understanding Data Governance and Data Analytics in Information Management
Data Governance and Data Analytics play crucial roles in transforming data into knowledge and insights for generating positive impacts on various operational systems. They help bring together disparate datasets to glean valuable insights and wisdom to drive informed decision-making. Managing data ma
0 views • 8 slides

Understanding MapReduce for Large Data Processing
MapReduce is a system designed for distributed processing of large datasets, providing automatic parallelization, fault tolerance, and clean abstraction for programmers. It allows for easy writing of distributed programs with built-in reliability on large clusters. Despite its popularity in the late
0 views • 52 slides

Introduction to Corpora and Statistical Methods in Natural Language Processing
This course, CSA5011, delves into statistical natural language processing, covering language formalization, Java as an artificial language, natural language complexity, and levels of analysis in phonetics, morphology, syntax, and semantics.
1 views • 34 slides

Exploring Construction Grammar in Cognitive Linguistics Symposium
Delve into the realm of Construction Grammar with Martin Hilpert in the 35th year of Cognitive Linguistics. Discover the intricacies of idiomatic constructions, the distinction between constructions and constructs, coercion in neologisms, and more. Explore the relationship between Construction Gramm
1 views • 81 slides

Understanding Data Preparation in Data Science
Data preparation is a crucial step in the data science process, involving tasks such as data integration, cleaning, normalization, and transformation. Data gathered from various sources may have inconsistencies in attribute names and values, requiring uniformity through integration. Cleaning data ad
1 views • 50 slides

Understanding Terminology Finding in the Sketch Engine
Terminology finding in the Sketch Engine involves identifying terms in a corpus, determining their relevance through unithood and termhood, and utilizing grammar for analysis. The process includes assessing frequency in domain versus reference corpora, collaborating with experts, and applying keynes
2 views • 18 slides

Guidebook for Managing Data from Emerging Technologies in Transportation
This guidebook explores the challenges and benefits of managing data from emerging technologies in transportation. It discusses the significance of big data, the need for a modern approach to data management, and offers a roadmap for agencies to transition towards this data management strategy. The
2 views • 21 slides
Understanding Data Collection and Analysis for Businesses
Explore the impact and role of data utilization in organizations through the investigation of data collection methods, data quality, decision-making processes, reliability of collection methods, factors affecting data quality, and privacy considerations. Two scenarios are presented: data collection
1 views • 24 slides

Understanding Corpus Linguistics in Web Research
Explore the world of corpus linguistics through Adam Kilgarriff's research, delving into the definition of a corpus, its historical background, types, parameters, and the vastness of linguistic data available on the web since the 1960s. Discover the significance of corpora in various fields such as
0 views • 19 slides

Insights into Long-Term Archiving Challenges for Large Corpora
Delve into the complexities of preserving and managing large corpora data through Signposts for CLARIN and related resources. Explore topics such as data alterations, format conversions, and virtual collection frameworks. Further reading offers in-depth insights from experts on addressing challenges
1 views • 11 slides

Understanding Discourse Coherence and Annotation in PDTB
NLP research on discourse coherence explores relations between events and propositions expressed in text, with a focus on combining individual relations into complex coherence structures. The PDTB approach annotates low-level relations in corpora to derive emergent high-level structural representati
0 views • 40 slides

Enhancing Corpus Analysis: Text and Sub-text Level Analysis
This study delves into the importance of improving text and sub-text level analysis of corpora, highlighting traditional approaches, current tools, challenges, and the necessity for effective database design. It emphasizes the need for user-friendly solutions to enhance research capabilities.
0 views • 19 slides

Russian Anaphora and Coreference Resolution Evaluation
The Ru-Eval-2019 project evaluates anaphora and coreference resolution for Russian text. It discusses the task definition, existing corpora, and introduces a new corpus from OpenCorpora.org. The project focuses on coreference resolution to determine which mentions in a text refer to the same entity,
0 views • 21 slides

Municipal Election Laws and Procedures in Cities and Large Towns
Explore the breakdown of municipal election laws in cities and large towns, including nomination procedures, election oversight, and candidate selection methods. Learn about the differences between large towns and small towns in the election process, as well as who manages elections for cities and l
0 views • 29 slides

Understanding Advanced Parsing Techniques for NLP Evaluation
Delve into the realm of advanced parsing with a focus on evaluating natural language processing models. Learn about tree comparison, evaluation measures like Precision and Recall, and the use of corpora like Penn Treebank for standardized parsing evaluation. Gain insights on how to assess parser per
0 views • 50 slides

Dynamic Data Management Systems in Agile Views
Large, dynamic data user and enterprise-generated data are increasingly popular, leading to the need for better data management systems. Today's approaches involve handling evolving datasets, algorithmic trading, log analysis, and more. The DBToaster project focuses on lightweight systems for managi
0 views • 37 slides

Introduction to Language Technologies at Jožef Stefan International Postgraduate School
This module on Knowledge Technologies at Jožef Stefan International Postgraduate School explores various aspects of Language Technologies, including Computational Linguistics, Natural Language Processing, and Human Language Technologies. The course covers computer processing of natural language, ap
0 views • 27 slides

Understanding Regular Expressions and the Corpus Query Language
This content introduces regular expressions and the Corpus Query Language (CQL) developed by the Corpora and Lexicons Group at the University of Stuttgart. It explains how to use regular expressions and CQL to search for specific patterns in text, providing practical tools and examples.
0 views • 41 slides

Practical Tools for Corpus Search Using Regular Expressions and Query Languages
These notes explore practical tools for corpus search including regular expressions and the corpus query language (CQL/CQP). They provide an introduction to using corpora effectively for pattern identification, with examples and explanations. The guide includes information on levels of annotation an
0 views • 47 slides

Understanding COCA: Corpus of Contemporary American English Workshop Overview
COCA (Corpus of Contemporary American English) is a valuable resource for researchers and linguists containing a vast database of text types from various registers such as spoken, fiction, magazines, newspapers, and academic sources. This overview discusses the collection timeframe, interface, searc
0 views • 16 slides

Latest Developments in GrETEL: An Overview of CLARIN, DARIAH, and CLARIAH Projects
GrETEL, a linguistic research tool, showcases the latest advancements in the field of humanities research, particularly within the CLARIN, DARIAH, and CLARIAH projects. It offers functionalities for linguistic research, treebank searching, and user-generated corpus analysis. The tool continues to ev
0 views • 30 slides
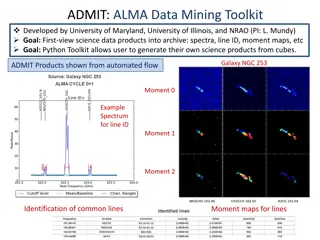
Automated Data Mining Toolkit for ALMA Science Products
The ADMIT (ALMA Data Mining Toolkit) developed by the University of Maryland, University of Illinois, and NRAO enables the generation of science products from data cubes. It supports first-view data products like spectra, line identification, and moment maps, facilitating analysis for galaxies like
0 views • 5 slides

Big Data and Ethical Considerations in Data Analysis
Big data involves analyzing and extracting information from large and complex datasets that traditional software cannot handle. AI algorithms play a crucial role in processing big data to find patterns that humans may overlook. Ethical considerations arise in defining what is "interesting" in the da
0 views • 25 slides

Invitation for Study of Enets Prosody: Phonology and Intonation Insights
Explore Enets phonology and intonation with Olesya Khanina from the Institute of Linguistics, Russian Academy of Sciences. Discover the unique set of phonemes, patterns of variation, and stress patterns at the word level. Uncover interesting questions about Enets prosody through digital corpora anal
0 views • 21 slides

Measuring Distance Between Language Varieties by Adam Kilgarriff
Adam Kilgarriff provides insights on comparing language varieties through qualitative and quantitative methods, corpus comparisons, and qualitative analysis using keyword lists and corpora contrast. The study explores techniques to evaluate language corpora scientifically and outlines the role of co
0 views • 24 slides

Introduction to arTenTen: A New Vast Corpus for Arabic Linguistic Processing
arTenTen is a new corpus for Arabic containing a vast array of text types, rich metadata, and clean linguistic processing capabilities. It offers a significant improvement over existing Arabic corpora, presenting a larger dataset with a variety of linguistic features. The corpus is fully processed,
0 views • 8 slides

Understanding Word Sense Disambiguation in Computational Lexical Semantics
Word Sense Disambiguation (WSD) is a crucial task in Computational Lexical Semantics, aiming to determine the correct sense of a word in context from a fixed inventory of potential word senses. This process involves various techniques such as supervised machine learning, unsupervised methods, thesau
0 views • 67 slides

Effective Data Transport Strategies for Large-Scale Operations
Explore strategies for efficient data transport in large-scale operations, emphasizing moving towards more extensive data types, ensuring security, transparency, and manageability. Detailing transport options like (S)FTP(s) and HTTP(s) while prioritizing simplicity and flexibility. Considerations fo
0 views • 32 slides

Insights into Academic Speaking: Interdisciplinary Perspectives
Explore the differences between spoken academic English and conversational English, examine discipline-specific constraints, and delve into corpus analysis findings that shape EAP materials. Discover the evolution of ESP/EAP traditions, the availability of spoken academic corpora like MICASE, and in
0 views • 27 slides

Evaluation of Information Retrieval Systems and User Satisfaction
Information Retrieval Systems are evaluated based on aspects like query assistance, speed, resources, and relevancy. Measuring user satisfaction often relies on the relevance of search results, which requires benchmark collections, query suites, and binary relevance assessments. Human-labeled corpor
0 views • 24 slides

Unsupervised Machine Translation Research Overview
Delve into the world of unsupervised machine translation research focusing on the challenges of low-resource languages, lack of parallel corpora hindering system development, and the solutions and efficient approaches adapted by researchers. Explore the agenda covering semi-supervised and unsupervis
0 views • 28 slides

Fast Bayesian Optimization for Machine Learning Hyperparameters on Large Datasets
Fast Bayesian Optimization optimizes hyperparameters for machine learning on large datasets efficiently. It involves black-box optimization using Gaussian Processes and acquisition functions. Regular Bayesian Optimization faces challenges with large datasets, but FABOLAS introduces an innovative app
0 views • 12 slides

Exploring Extended Uses of the Quotative Verb "ge" in Khalkha Mongolian
This research delves into the extended uses of the quotative verb "ge" in Khalkha Mongolian through evidence from corpora, sentence data, and elicitation methods. It highlights various types of functions such as minimal extensions, topicalization, clause connection, additive focus with "gese," inten
0 views • 37 slides