Understanding Communication Networks: Transport and Protocols

 undefined
undefinedcs/ee/ids 143 Communication Networks
Chapter 4 Transport


Text: Walrand & Parakh, 2010
Steven Low
CMS, EE, Caltech
Agenda
Internetworking
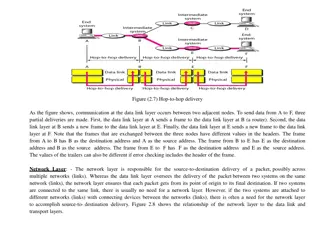
Routing across LANs, layer2-layer3
DHCP
NAT
Transport layer
Connection setup
Error recovery: retransmission
Congestion control
Transport services
UDP
•
Datagram service
•
No congestion control
•
No error/loss recovery
•
Lightweight
TCP
•
Connection oriented service
•
Congestion control
•
Error/loss recovery
•
Heavyweight
UDP
UDP header
1 ~ 65535 (2
16
-1)
≤ 65535 Bytes – 8 Bytes (UDP header) – 20 Bytes (IP header)
Usually smaller to avoid IP fragmentation (e.g., Ethernet MTU 1500 Bytes)
TCP
TCP header
Example TCP states
3-way handshake
4-way handshake
P
o
s
s
i
b
l
e
i
s
s
u
e
:
S
Y
N
f
l
o
o
d
a
t
t
a
c
k
Result in large numbers of half-open connections and no new
connections can be made.
Window Flow Control
~ W packets per RTT
Lost packet detected by missing ACK
time
time
Source
Destination
ARQ (Automatic Repeat Request)
Go-back-N
Selective repeat
T
C
P
•
Sender & receiver negotiate whether or
not to use Selective Repeat (SACK)
•
Can ack up to 4 blocks of contiguous
bytes that receiver got correctly
e.g. [3; 10, 14; 16, 20; 25, 33]
Window control
Limit the number of packets in the
network to window W
Source rate = bps
If W too small then rate « capacity
If W too big then
rate > capacity
=>
congestion
Adapt W to network (and conditions)
TCP window control
Receiver flow control
Avoid overloading receiver
Set by receiver
awnd
: receiver (advertised) window
Network congestion control
Avoid overloading network
Set by sender
Infer available network capacity
cwnd
: congestion window
Set W = min (
cwnd
,
awnd
)
TCP congestion control
Source calculates
cwnd
from indication
of network congestion
Congestion indications
Losses
Delay
Marks
Algorithms to calculate
cwnd
Tahoe, Reno, Vegas, …
TCP Congestion Controls
Tahoe (Jacobson 1988)
Slow Start
Congestion Avoidance
Fast Retransmit
Reno (Jacobson 1990)
Fast Recovery
Vegas (Brakmo & Peterson 1994)
New Congestion Avoidance
TCP Tahoe
(Jacobson 1988)
SS
time
window
CA
: Slow Start
: Congestion Avoidance
: Threshold
Slow Start
Start with
cwnd := 1
(slow start)
On each successful ACK increment cwnd
cwnd
:=
cnwd + 1
Exponential growth
of cwnd
each RTT:
cwnd
:=
2 x cwnd
Enter
CA
when
cwnd >= ssthresh
Congestion Avoidance
Starts when
cwnd
>=
ssthresh
On each successful ACK:
cwnd
:=
cwnd + 1/cwnd
Linear growth
of cwnd
each RTT:
cwnd
:=
cwnd + 1
Packet Loss
Assumption
: loss indicates congestion
Packet loss detected by
Retransmission TimeOuts (RTO timer)
Duplicate ACKs (at least 3)
(Fast Retransmit)
Fast Retransmit
Wait for a timeout is quite long
Immediately retransmits after 3 dupACKs
without waiting for timeout
Adjusts ssthresh
flightsize := min(awnd, cwnd)
ssthresh
:=
max(flightsize/2, 2)
Enter Slow Start
(cwnd := 1)
Summary: Tahoe
Basic ideas
Gently probe network for spare capacity
Drastically reduce rate on congestion
Windowing: self-clocking
for every ACK {if (W < ssthresh) then
W++
(SS)
else
W += 1/W
(CA)
}
for every loss {ssthresh := W/2
W := 1
}
Seems a little too conservative?
TCP Reno
(Jacobson 1990)
for every ACK {W += 1/W
(AI)
}
for every loss {W := W/2
(MD)
}
How to halve W without emptying the pipe?
Fast Recovery
Fast recovery
Idea: each dupACK represents a packet
having left the pipe (successfully
received)
Enter FR/FR after 3 dupACKs
Set
ssthresh
:=
max(flightsize/2, 2)
Retransmit lost packet
Set
cwnd
:=
ssthresh +
ndup
(window
inflation)
Wait till W := min(awnd, cwnd) is large
enough; transmit
new
packet(s)
On non-dup ACK, set
cwnd
:=
ssthresh
(window deflation)
Enter
CA
Example: FR/FR
Fast retransmit
Retransmit on 3 dupACKs
Fast recovery
Inflate window while repairing loss to fill pipe
time
S
time
R
8
cwnd
8
ssthresh
Summary: Reno
Basic ideas
dupACKs: halve W and avoid slow start
dupACKs: fast retransmit + fast recovery
Timeout: slow start
slow start
retransmit
congestion
avoidance
FR/FR
dupACKs
timeout
Multiple loss in Reno?
On 3 dupACKs, receiver has packets 2, 4, 6, 8,
cwnd=8, retransmits pkt 1, enter FR/FR
Next dupACK increment cwnd to 9
After a RTT, ACK arrives for pkts 1 & 2, exit
FR/FR, cwnd=5, 8 unack’ed pkts
No more ACK, sender must wait for
timeout
1
2
time
S
time
D
3
4
5
6
8
7
0
9
New Reno
Fall & Floyd ‘96, (RFC 2583)
Motivation: multiple losses within a window
Partial ACK
takes Reno out of FR, deflates
window
Sender may have to wait for timeout before
proceeding
Idea: partial ACK indicates lost packets
Stays in FR/FR and retransmits immediately
Retransmits 1 lost packet per RTT until
all
lost
packets from that window are retransmitted
Eliminates timeout
Delay-based TCP: Vegas
(Brakmo & Peterson 1994)
Reno with a new congestion avoidance
algorithm
Converges (provided buffer is large) !
SS
time
window
CA
for every RTT
{if W/RTT
min
– W/
RTT
<
RTT
min
then W
++
if W/RTT
min
– W/
RTT
>
RTT
min
then W
--
}
for every loss
W := W/2
Congestion avoidance
Each source estimates number of its own
packets in pipe from RTT
Adjusts window to maintain estimate #
of packets in queues between
and
Implications
Congestion measure =
end-to-end
queueing
delay
At equilibrium
Zero loss
Stable window at full utilization
Nonzero queue, larger for more sources
Convergence to equilibrium
Converges if sufficient network buffer
Oscillates like Reno otherwise
Theory-guided design: FAST
We will study them further in TCP modeling in the following
weeks
Summary
UDP header/TCP header
TCP 3-way/4-way handshake
ARQ: Go-back-N/selective repeat
Tahoe/Reno/New Reno/Vegas/FAST
-- useful details for your project
31
Why both TCP and UDP?
Most applications use TCP, as this avoids re-
inventing error recovery in every application
But some applications do not need TCP
For example: Voice applications
Some packet loss is fine.
Packet retransmission introduces too much delay.
For example: an application that sends just one
message, like DNS/SNMP/RIP.
TCP sends several packets before the useful one.
We may add reliability at application layer instead.
Mathematical model
TCP/AQM
Congestion control is a distributed asynchronous algorithm to
share bandwidth
It has two components
TCP: adapts sending rate (window) to congestion
AQM: adjusts & feeds back congestion information
They form a distributed feedback control system
Equilibrium & stability depends on both TCP and AQM
And on delay, capacity, routing, #connections
p
l
(t)
TCP:
Reno
Vegas
FAST
AQM:
DropTail
RED
REM/PI
AVQ
Network model
Network
Links
l
of capacities
c
l
and congestion measure
p
l
(t)
Sources
i
Source rates
x
i
(t)
Routing matrix
R
Network model
Examples
Derive (
F
i
,
G
l
) model for
Reno/RED
Vegas/Droptail
FAST/Droptail
Focus on Congestion Avoidance
Model: Reno
for every ack (
ca)
{W += 1/W }
for every loss
{W := W/2 }
Model: Reno
for every ack (
ca)
{W += 1/W }
for every loss
{W := W/2 }
link loss
probability
round-trip
loss probability
window size
throughput
Model: Reno
for every ack (
ca)
{W += 1/W }
for every loss
{W := W/2 }
Model: RED
source
rate
aggregate
link rate
Model: Reno/RED
Decentralization structure
q
y
Validation – Reno/REM
30 sources, 3 groups with RTT = 3, 5, 7 ms
Link capacity = 64 Mbps, buffer = 50 kB
Smaller window due to
small
RTT (~0 queueing
delay)
queue size
for every RTT
{ if W/RTTmin
– W/RTT <
then W
++
if W/RTT
min
– W/RTT >
then W
-- }
for every loss
W := W/2
Model: Vegas/Droptail
Model: FAST/Droptail
L., Peterson, Wang, JACM 2002
Validation: matching transients
Same RTT, no cross traffic
Same RTT, cross traffic
Different RTTs, no cross traffic
[Jacobsson et al 2009]
Recap
Protocol
(Reno, Vegas, FAST, Droptail, RED…)
Economic Dispatch in Power Networks with Storage
March 10-12, 2010: Workshop on Distributed Decisions via Games and Price Mechanisms, Lund University, Sweden (Anders Rantzer)
Explore the intricacies of communication networks focusing on transport services, protocol stack, UDP, TCP, error control, congestion control, and more. Learn about interworking, routing, DHCP, NAT, connection setup, and error recovery mechanisms. Dive into TCP and UDP headers, handshake processes, flow control, automatic repeat requests, and window management strategies. Gain insights into network mechanisms, protocol evolution, and data transmission across various layers.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
cs/ee/ids 143 Communication Networks Chapter 4 Transport Text: Walrand & Parakh, 2010 Steven Low CMS, EE, Caltech
Agenda Internetworking Routing across LANs, layer2-layer3 DHCP NAT Transport layer Connection setup Error recovery: retransmission Congestion control
Protocol stack Network mechanisms implemented as protocol stack Each layer designed separately, evolves asynchronously Many control mechanisms application transport network link physical Error control, congestion control (TCP) Routing (IP) Medium access control Coding, transmission, synchronization
Transport services UDP Datagram service No congestion control No error/loss recovery Lightweight TCP Connection oriented service Congestion control Error/loss recovery Heavyweight
UDP 1 ~ 65535 (216-1) UDP header 65535 Bytes 8 Bytes (UDP header) 20 Bytes (IP header) Usually smaller to avoid IP fragmentation (e.g., Ethernet MTU 1500 Bytes)
TCP TCP header
Example TCP states 3-way handshake 4-way handshake Possible issue: SYN flood attack Result in large numbers of half-open connections and no new connections can be made.
Window Flow Control RTT 1 2 W 1 2 W Source time ACKs data Destination 1 2 W 1 2 W time ~ W packets per RTT Lost packet detected by missing ACK
ARQ (Automatic Repeat Request) Go-back-N TCP Sender & receiver negotiate whether or not to use Selective Repeat (SACK) Can ack up to 4 blocks of contiguous bytes that receiver got correctly e.g. [3; 10, 14; 16, 20; 25, 33] Selective repeat
Window control Limit the number of packets in the network to window W W MSS Source rate = bps RTT If W too small then rate capacity If W too big then rate > capacity => congestion Adapt W to network (and conditions)
TCP window control Receiver flow control Avoid overloading receiver Set by receiver awnd: receiver (advertised) window Network congestion control Avoid overloading network Set by sender Infer available network capacity cwnd: congestion window Set W = min (cwnd, awnd)
TCP congestion control Source calculates cwnd from indication of network congestion Congestion indications Losses Delay Marks Algorithms to calculate cwnd Tahoe, Reno, Vegas,
TCP Congestion Controls Tahoe (Jacobson 1988) Slow Start Congestion Avoidance Fast Retransmit Reno (Jacobson 1990) Fast Recovery Vegas (Brakmo & Peterson 1994) New Congestion Avoidance
TCP Tahoe (Jacobson 1988) window time SS CA : Slow Start : Congestion Avoidance : Threshold
Slow Start Start with cwnd := 1 (slow start) On each successful ACK increment cwnd cwnd := cnwd + 1 Exponential growth of cwnd each RTT: cwnd := 2 x cwnd Enter CA when cwnd >= ssthresh
Congestion Avoidance Starts when cwnd >=ssthresh On each successful ACK: cwnd := cwnd + 1/cwnd Linear growth of cwnd each RTT: cwnd := cwnd + 1
Packet Loss Assumption: loss indicates congestion Packet loss detected by Retransmission TimeOuts (RTO timer) Duplicate ACKs (at least 3) (Fast Retransmit) Packets 1 7 2 3 4 5 6 Acknowledgements 3 1 2 3 3 3
Fast Retransmit Wait for a timeout is quite long Immediately retransmits after 3 dupACKs without waiting for timeout Adjusts ssthresh flightsize := min(awnd, cwnd) ssthresh := max(flightsize/2, 2) Enter Slow Start (cwnd := 1)
Summary: Tahoe Basic ideas Gently probe network for spare capacity Drastically reduce rate on congestion Windowing: self-clocking for every ACK { if (W < ssthresh) then W++ else W += 1/W } for every loss { ssthresh := W/2 W := 1 } (SS) (CA) Seems a little too conservative?
TCP Reno (Jacobson 1990) SS CA for every ACK { W += 1/W } for every loss { W := W/2 } (AI) (MD) How to halve W without emptying the pipe? Fast Recovery
Fast recovery Idea: each dupACK represents a packet having left the pipe (successfully received) Enter FR/FR after 3 dupACKs Set ssthresh := max(flightsize/2, 2) Retransmit lost packet Set cwnd := ssthresh + ndup (window inflation) Wait till W := min(awnd, cwnd) is large enough; transmit new packet(s) On non-dup ACK, set cwnd := ssthresh (window deflation) Enter CA
Example: FR/FR 1 2 3 4 5 6 7 8 1 9 10 11 S time Exit FR/FR time R 0 0 0 0 8 0 0 0 11 cwnd ssthresh 8 7 4 9 4 4 4 4 Fast retransmit Retransmit on 3 dupACKs Fast recovery Inflate window while repairing loss to fill pipe
Summary: Reno Basic ideas dupACKs: halve W and avoid slow start dupACKs: fast retransmit + fast recovery Timeout: slow start dupACKs congestion avoidance FR/FR timeout retransmit slow start
Delay-based TCP: Vegas (Brakmo & Peterson 1994) window time CA SS Reno with a new congestion avoidance algorithm Converges (provided buffer is large) !
Congestion avoidance Each source estimates number of its own packets in pipe from RTT Adjusts window to maintain estimate # of packets in queues between and for every RTT { if W/RTTmin W/RTT < RTTminthen W++ if W/RTTmin W/RTT > RTTmin } then W-- for every loss W := W/2
Implications Congestion measure = end-to-end queueing delay At equilibrium Zero loss Stable window at full utilization Nonzero queue, larger for more sources Convergence to equilibrium Converges if sufficient network buffer Oscillates like Reno otherwise
Theory-guided design: FAST We will study them further in TCP modeling in the following weeks
Summary UDP header/TCP header TCP 3-way/4-way handshake ARQ: Go-back-N/selective repeat Tahoe/Reno/New Reno/Vegas/FAST -- useful details for your project
Why both TCP and UDP? Most applications use TCP, as this avoids re- inventing error recovery in every application But some applications do not need TCP For example: Voice applications Some packet loss is fine. Packet retransmission introduces too much delay. For example: an application that sends just one message, like DNS/SNMP/RIP. TCP sends several packets before the useful one. We may add reliability at application layer instead. 31
TCP/AQM pl(t) AQM: DropTail RED REM/PI AVQ TCP: Reno Vegas FAST xi(t) Congestion control is a distributed asynchronous algorithm to share bandwidth It has two components TCP: adapts sending rate (window) to congestion AQM: adjusts & feeds back congestion information They form a distributed feedback control system Equilibrium & stability depends on both TCP and AQM And on delay, capacity, routing, #connections
Network model Network Links lof capacities cland congestion measure pl(t) Sources i Source rates xi(t) Routing matrix R R=1 1 0 1 0 1 x1(t) x1+x3 c2 x1+x2 c1 p1(t) p2(t) x2(t) x3(t)
Network model x y R F1 G1 Network AQM TCP FN q GL p RT = 1 if source TCP CC model consists of specs for Fi and Gl uses link Rli i l IP routing x(t+1) =F (x(t),RTp(t)) p(t+1) =G (Rx(t), p(t)) Reno, Vegas Droptail, RED
Examples Derive (Fi, Gl) model for Reno/RED Vegas/Droptail FAST/Droptail Focus on Congestion Avoidance
Model: Reno for every ack (ca) { W += 1/W } for every loss { W := W/2 } Dwit ( )=xi(t)(1-qi(t)) -wi(t) xi(t)qi(t) 2 wi
Model: Reno for every ack (ca) { W += 1/W } for every loss { W := W/2 } Dwit ( )=xi(t)(1-qi(t)) -wi(t) xi(t)qi(t) wi(t) 2 l qi(t)= Rlipl(t) throughput window size round-trip loss probability link loss probability
Model: Reno for every ack (ca) { W += 1/W } for every loss { W := W/2 } Dwit ( )=xi(t)(1-qi(t)) -wi(t) xi(t)qi(t) wi(t) 2 Uses: xi(t)=wi(t) 2 xi(t+1)= xi(t)+1 2-xi 2qi(t) Ti ( Ti ) qi(t) 0 Fixi(t),qi(t)
Model: RED i marking prob yl(t)= Rlixi(t) 1 aggregate link rate source rate queue length bl(t+1)= bl(t)+ yl(t)-cl [ pl(t)= min abl(t),1 { ] + } pl(t)=Glyl(t),pl(t) ( )
Model: Reno/RED 2 xi(t+1)= xi(t)+1 2-xi 2qi(t) Ti l i qi(t)= Rlipl(t) xi(t+1)=Fixi(t),qi(t) ( ) yl(t)= Rlixi(t) bl(t+1)= bl(t)+ yl(t)-cl [ pl(t)= max abl(t),1 { ] + } pl(t)=Glyl(t),pl(t) ( )
Decentralization structure x y y R F1 G1 Network AQM TCP FN q q GL p RT l i qi(t)= Rlipl(t) x(t+1) =F(x(t), q(t)) p(t+1) =G(y(t), p(t)) yl(t)= Rlixi(t)
Validation Reno/REM 30 sources, 3 groups with RTT = 3, 5, 7 ms Link capacity = 64 Mbps, buffer = 50 kB Smaller window due to small RTT (~0 queueing delay)
Model: Vegas/Droptail for every RTT { if W/RTTmin W/RTT < then W++ if W/RTTmin W/RTT > then W-- } for every loss queue size W := W/2 1 2(t) if wi(t)-dixi(t)<ai 1 2(t) if wi(t)-dixi(t)>ai xit+1 ( )= xi(t) + )= xi(t) - Fi: di Ti xit+1 ( di Ti xit+1 ( )= xi(t) else Ti(t)=di+qi(t) Gl: pl(t+1) = [pl(t) + yl (t)/cl - 1]+
Model: FAST/Droptail periodically { baseRTT = + W : W RTT } gi Ti(t)ai- xi(t)qi(t) ( ) xi(t+1)= xi(t)+ + pl(t+1)= pl(t)+1 ( ) yl(t)-cl cl
Validation: matching transients f ( ) 1 w t i = + + f ( ) ( ) i i p w t x t c 0 i i + ( ) c d p t i [Jacobsson et al 2009] Same RTT, no cross traffic Same RTT, cross traffic Different RTTs, no cross traffic
Recap Protocol (Reno, Vegas, FAST, Droptail, RED ) x(t+1) =F (x(t), q(t)) p(t+1) =G (y(t), p(t)) Equilibrium Performance Throughput, loss, delay Fairness Utility Dynamics Local stability Global stability








")




")





")