Understanding Set Transformer: A Framework for Attention-Based Permutation-Invariant Neural Networks


Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks
Ki-Ryum Moon
2023.04.28
RTOS Lab
Department of Computer Science
Kyonggi University




Introduction
2
Set-input problem
•
Set-input problem
의 대표적인 예시로
Multiple instance learning
이
있음
.
전체 데이터에서 파생된 인스턴스
(instance)
들의 집합을 입력으로 받아
,
전체 데이터의 정답 값을 추론하는
문제
.
•
이 밖에도
, 3D shape recognition,
sequence
ordering(
데이터의 순서에 따른 학습 영향력 고려
)
등이 있음
.
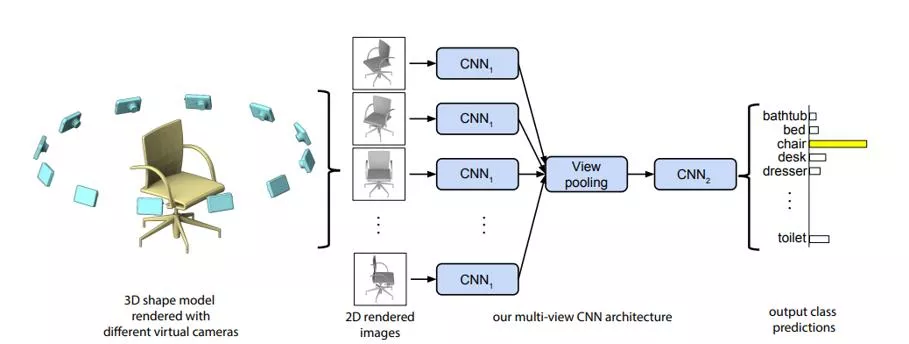
3D shape recognition

Introduction
3
Set-input problem
•
이러한
Set-input problem
은 이하 두 가지 핵심적인 요구사항을 만족해야 함
.
순열 불변성
(permutation invariant)
을 만족해야 함
.
어떠한 크기를 지닌 데이터라도 처리가 가능해야 함
.
•
하지만 이 요구사항들을 만족하여 정의된 집합 데이터들은 쉽사리 딥러닝 네트워크에 적용하기 어려움
.
(ex.
Feed forward network, RNN, etc)

Introduction
4
Set-input problem
•
하지만
, Set pooling
이라는 방법을 이용하여
두 가지 제약사항을 만족하는
neural network
가
2017
년에 제안됨
.
(Edwards & Storkey (2017) and Zaheer et al. (2017))
Set
내 각 요소는 먼저 고정 크기 입력을 받는 신경망에 독립적으로 입력됨
.
이를 통한 입력의
feature space
로의
embedding
결과물은 평균
,
합
,
최댓값 또는 유사한
pooling
연산을 사용하여 집계됨
.
최종
출력물은 집계된
embedding vector
에 대해 추가적인 비선형 처리
(
활성화 함수
)
를 거쳐 얻음
.
•
이로 인해
,
입력
set
에 대해 이를 바탕으로 수행되는 출력 값 계산 과정이 복잡하여도
,
효과적으로 수행 할 수 있게 됨
.
Introduction
5
Set-input problem
•
하지만
,
이러한 과정은
set
의 순서나 내용에 의존하지 않는다는 것임
.
•
이렇게 되면 모델의 최적화도 어려울 수 있으며
,
솔루션의 성능도 제한됨
.
•
또한 본 논문에서 실험적으로 이러한
pooling
아키텍처가 과소적합에 문제가 있다는 것을 보여줌
.
Introduction
6
•
Transformer
를 활용해서
set structure data
를 입력으로 받는 새로운 딥러닝 모델을 제안하는 논문임
.
•
Set Transformer
는 다음과 같은 특징을 지님
.
self-attention
연산을 이용하여
, set
내 원소 간 쌍 혹은 원소 간 상호작용을 자연스럽게 학습 가능함
.
self-attention
의 계산 복잡도를 줄여
,
대규모 입력에 대해서 수행 가능하도록 제안함
.
Background about set transformer
7
Background about set transformer
8
Encoding
된
feature
Decoder
수행 결과
Background about set transformer
9
Pooling Architecture for Sets
•
추가적으로 모델의 순열 불변성을 유지하기 위해서 설계한 순열 동등 계층
layer
를 층층이 쌓은
encoder
는
다음과 같이 정의할 수 있음
.
Set Transformer
10
Set Transformer – MAB(Multi Head Attention Block)
•
입력으로 받는 서로 다른
X,Y
집합 간
multi head Attention
을 수행함
.
•
이는
X,Y
집합 내의 원소
,
인스턴스 간의 쌍으로 학습 및 고차원 상호작용을 연산할 수 있도록 함
.
Set Transformer
11
Set Transformer – SAB(Set Attention Block)
•
MAB
를 응용하여 입력을
Set X
만을 사용하는
Attention
을 수행함
.
•
이 방법은
X
집합 내의 원소들 간의 상호작용 정보를 학습하도록 연산할 수 있도록 함
.
•
즉
, SAB
모듈을 여러 번 쌓아
Encoding
을 수행하면 원소들 간의 고차원 상호작용 정보를 모델링 할 수 있음
.
Set Transformer
12
입력
set X
에 대한 전역적인 구조를 학습하게 됨
.
Ex) ViT
의
CLS TOKEN
과 살짝 비슷함
.
Set Transformer
13
Query
로 입력되어
patch
집합에 대해
모든 정보를 학습하는 과정이 비슷함
.
Set Transformer – ISAB(Induced Set Attention Block) (2)
•
이는 저차원 투영 또는 오토 인코더 모델과 유사함
.
이들 모델에서는 입력
(X)
이 먼저 저 차원 객체
(H)
로
투영되어
다시 재구성되어 출력으로 생성됨
.
•
하지만
, ISAB
는 재구성을 하는 것이 아닌
,
입력
X
에 대해서 설명하는 좋은
Feature
를 학습하는 것이 목표
Set Transformer
14
Set Transformer – ISAB(Induced Set Attention Block) (3)
•
예를 들어
,
2D
평면에서의
Amortized Clustering
문제로 대입했을 때 상황을 비교하고자 함
.
•
2D
공간에서
induced points
가 적절하게 분포된 점들로 되어 있다고 할 때
Encoder
가 입력 집합
X
내의 원소들을
embedding
한 값과
embedding
된 값과
Induced points
와의 거리 측정을 통해 다른 점들과 유사성을 판단
,
이로
클러스터링을 수행함
.
Set Transformer
15
Set Transformer
16
Set Transformer – Pooling by Multi head Attention (1)
•
Permutation
invariant
한 네트워크에서 일반적인 집계 함수
(aggregation)
은 특징 벡터의 각 차원 별 평균
or
최댓값
.
•
Set transformer
는 학습 가능한
k
개의 벡터에 대해
muti head attention
을 수행하여 특징을 집계하도록 제안함
.
Z
는 인코더로부터 얻어진 특징들의
집합
.
Set Transformer
17
Set Transformer – Pooling by Multi head Attention (2)
•
PMA
는 출력이
k
개의
item
으로 이루어진 집합임
.
•
대부분의 경우
,
k = 1
임
.
•
하지만
, k
개의 상관된 출력이 필요한
amortized clustering
과 같은 문제의 경우
k
개의 벡터를 사용함
.
•
그리고
k
개의 출력
(cluster)
간 상호작용을 더 잘 모델링하기 위해
SAB
를 적용함
.
Set Transformer
18
Set Transformer – Overall Architecture (1)
•
Encoder, decoder
로 구성된
set transformer
를 구성하는 것은 다음과 같음
.
Experiments
19
Max regression task
Experiments
20
Meta clustering
Conclusion
21
•
Encoding
과
feature aggregation
시
attention
을 수행하는 방법을 제안함
.
•
기존 순열 불변 함수를 이용한 문제 해결 모델 중 제일 범용적으로 사용가능한 모델로 제시됨
.
Explore the Set Transformer framework that introduces advanced methods for handling set-input problems and achieving permutation invariance in neural networks. The framework utilizes self-attention mechanisms and pooling architectures to encode features and transform sets efficiently, offering insights into tasks like 3D shape recognition and sequence ordering.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
Set Transformer: A Framework for Attention-based Permutation-Invariant Neural Networks Ki-Ryum Moon 2023.04.28 RTOS Lab Department of Computer Science Kyonggi University
Introduction Set-input problem Set-input problem Multiple instance learning . (instance) , . , 3D shape recognition, sequence ordering( ) . 3D shape recognition 2
Introduction Set-input problem Set-input problem . (permutation invariant) . . . (ex. Feed forward network, RNN, etc) 3
Introduction Set-input problem , Set pooling neural network 2017 . (Edwards & Storkey (2017) and Zaheer et al. (2017)) Set . feature space embedding , , pooling . embedding vector ( ) . , set , . 4
Introduction Set-input problem , set . , . pooling . 5
Introduction Transformer set structure data . Set Transformer . self-attention , set . self-attention , . 6
Background about set transformer Pooling Architecture for Sets (permutation invariance) . , set embedding pooling network . pool , ?,? . 7
Background about set transformer Pooling Architecture for Sets Set transformer . ? ??? encoder , ?(???? decoder . ) Encoding feature Decoder 8
Background about set transformer Pooling Architecture for Sets layer encoder . 9
Set Transformer Set Transformer MAB(Multi Head Attention Block) X,Y multi head Attention . X,Y , . 10
Set Transformer Set Transformer SAB(Set Attention Block) MAB Set X Attention . X . , SAB Encoding . 11
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (1) , SAB . ?(?2), . Induced points vector . set X . Ex) ViT CLS TOKEN . 12
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (2) . (X) (H) . , ISAB , X Feature Query patch . 13
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (3) , 2D Amortized Clustering . 2D induced points Encoder X embedding embedding Induced points , . 14
Set Transformer Set Transformer ISAB(Induced Set Attention Block) (4) ISAB m(m << m) n Attention , ? ?? . permutation equivariant . 15
Set Transformer Set Transformer Pooling by Multi head Attention (1) Permutation invariant (aggregation) or . Set transformer k muti head attention . Z . 16
Set Transformer Set Transformer Pooling by Multi head Attention (2) PMA k item . , k = 1 . , k amortized clustering k . k (cluster) SAB . 17
Set Transformer Set Transformer Overall Architecture (1) Encoder, decoder set transformer . 18
Experiments Max regression task 19
Experiments Meta clustering 20
Conclusion Encoding feature aggregation attention . . 21