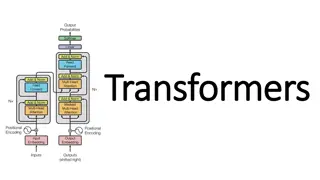
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations

The ZEN model improves pre-training procedures by incorporating n-gram representations, addressing limitations of existing methods like BERT and ERNIE. By leveraging n-grams, ZEN enhances encoder training and generalization capabilities, demonstrating effectiveness across various NLP tasks and datasets.

Download Presentation

Please find below an Image/Link to download the presentation.
The content on the website is provided AS IS for your information and personal use only. It may not be sold, licensed, or shared on other websites without obtaining consent from the author. Download presentation by click this link. If you encounter any issues during the download, it is possible that the publisher has removed the file from their server.
E N D
Presentation Transcript
ZEN: Pre-training Chinese Text Encoder Enhanced by N-gram Representations Shizhe Diao , Jiaxin Bai, Yan Song, Tong Zhang, Yonggang Wang The Hong Kong University of Science and Technology Sinovation Ventures
Introduction Normally, the pre-training procedures are designed to learn on tokens corresponding to small units of texts a representative study in Cui(BERT-wwm) proposed to use the whole- word masking strategy to mitigate the limitation of word information. Sun(ERNIE) proposed to perform both entity-level and phrase-level masking to learn knowledge and information from the pre-training corpus.
Introduction First, both methods rely on the word masking strategy so that the encoder can only be trained with existing word and phrase information. Second, similar to the original BERT, the masking strategy results in the mismatch of pre-training and fine-tuning, i.e., no word/phrase information is retained when the encoders are applied to downstream prediction tasks Third, incorrect word segmentation or entity recognition results cause errors propagated to the pre-training process and thus may negatively affected the generalization capability of the encoder
ZEN N-gram Extraction The first one is to prepare an n-gram lexicon, L, from which one can use any unsupervised method to extract n-grams for later processing. The second step of n-gram extraction is performed during pre-training, where some n-grams in L are selected according to each training instance c = (?1, ?2, ..., ??, ..., ???) with ??characters
ZEN Encoding N-grams We adopt Transformer as the encoder, which is a multi-layer encoder that can model the interactions among all n-grams through their representations in each layer
ZEN Representing N-grams in Pre-training
Experiment Settings Tasks and Datasets we use Chinese Wikipedia dump as the base corpus to learn different encoders including ZEN For fine-tuning, we choose seven NLP tasks and their corresponding benchmark datasets in our experiments Chinese word segmentation (CWS) Part-of-speech (POS) tagging Named entity recognition (NER) Document classification (DC) Sentiment analysis (SA) Sentence pair matching (SPM) Natural language inference (NLI)
Analyses Effects of Pre-training Epochs
Analyses Effects of N-gram Extraction Threshold
Analyses Visualization of N-gram Representations
pku x f1 0.957 0.957 x f1 0.961 0.961 paper f1 0.965 0.9647 precision recall 0.965 0.964 precision 0.965 0.968 recall 0.956 0.954 precision recall 0.968 bert+mlp bert+crf 0.949 0.95 0.963 bert 10 model(mlp) bert 10 model(crf) 0.954 0.701 0.962 0.727 0.945 0.677 0.956 0.958 0.964 0.966 0.948 0.95 bert loss 10 model(mlp) bert loss 10 model(crf) 0.954 0.955 0.962 0.963 0.945 0.947 0.956 0.961 0.964 0.969 0.948 0.954 bert dev 10 model(mlp) bert dev 10 model(crf) 0.955 0.956 0.963 0.966 0.946 0.946 0.956 0.959 0.964 0.968 0.949 0.951
msr x f1 0.968 0.969 x f1 0.971 0.979 paper f1 0.981 0.9819 precision recall 0.97 0.973 precision 0.972 0.98 recall 0.97 0.979 precision recall 0.981 bert+mlp bert+crf 0.965 0.966 0.982 bert 10 model(mlp) bert 10 model(crf) 0.953 0.305 0.942 0.327 0.964 0.286 0.864 0.327 0.846 0.258 0.882 0.444 bert loss 10 model(mlp) bert loss 10 model(crf) 0.953 0.959 0.942 0.951 0.964 0.967 0.864 0.981 0.846 0.984 0.882 0.978 bert dev 10 model(mlp) bert dev 10 model(crf) 0.953 0.943 0.943 0.952 0.964 0.934 0.864 0.981 0.846 0.983 0.883 0.98
cityu x f1 0.971 0.971 x f1 0.973 0.976 paper f1 0.976 0.9709 precision recall 0.971 0.97 precision 0.974 0.977 recall 0.972 0.975 precision recall 0.975 bert+mlp bert+crf 0.971 0.971 0.977 bert 10 model(mlp) bert 10 model(crf) 0.781 0.302 0.763 0.33 0.8 0.278 0.966 0.952 0.969 0.951 0.964 0.954 bert loss 10 model(mlp) bert loss 10 model(crf) 0.781 0.971 0.763 0.97 0.8 0.971 0.966 0.977 0.969 0.978 0.964 0.976 bert dev 10 model(mlp) bert dev 10 model(crf) 0.971 0.971 0.97 0.97 0.972 0.971 0.967 0.976 0.97 0.976 0.964 0.976
as x f1 0.952 0.955 x f1 0.96 paper f1 0.965 0.9623 precision recall 0.949 0.956 precision 0.961 recall 0.958 precision recall 0.964 bert+mlp bert+crf 0.955 0.954 0.967 bert 10 model(mlp) bert 10 model(crf) 0.674 0.456 0.617 0.489 0.742 0.428 0.876 0.852 0.902 bert loss 10 model(mlp) bert loss 10 model(crf) 0.674 0.951 0.617 0.948 0.742 0.955 0.876 0.852 0.902 bert dev 10 model(mlp) bert dev 10 model(crf) 0.951 0.948 0.95 0.943 0.952 0.953 0.874 0.849 0.901